
ICCV'23|华为诺亚提出轻量目标检测器Focus-DETR:30%Token就能实...
739573
作者丨Garfield 来源丨极市平台 本文首发于极市平台,转载须经授权并注明来源插入公众号名片。
导读
Focus-DETR 通过利用精细设计的前景特征选择策略,实现了目标检测高相关特征的精确筛选,以及模型性能和计算资源消耗、显存消耗、推理时延之间的平衡。

论文地址:https://arxiv.org/abs/2307.12612
代码地址:https://github.com/huawei-noah/noah-research/tree/master/Focus-DETR
1. 引言

这篇论文的研究背景是基于transformer的目标检测模型,特别是DETR系列模型。DETR类模型已经取得了很大进展,并逐渐弥补了与基于卷积网络的检测模型之间的差距。但是传统的encoder结构对所有tokens进行等量的计算,存在计算冗余。最近的工作已经讨论了在transformer encoder中压缩tokens以降低计算复杂度的可行性。但是这些方法倾向于依赖于不太可靠的模型统计信息。此外,简单减少tokens数量会严重影响检测性能。所以这篇论文的研究背景是如何在降低计算量的同时保持检测精度,即在计算效率和模型精度之间取得更好的平衡。具体来说,现有的稀疏方法存在以下问题:
- 现有方法倾向于过度依赖于解码器的交叉注意力图(DAM)来监督前景特征选择,这会导致前景特征选择效果不佳。尤其是在采用可学习queries的模型中,DAM与保留的前景tokens之间的相关性会降低。
- 现有方法无法有效利用多尺度特征图之间的语义关联性,不同尺度间tokens选择决策的偏差被忽略。
- 现有方法只进行简单的背景tokens舍弃,前景tokens的数量仍然繁多,无法进行更细粒度的查询交互来提升语义信息,因为计算量受限。
- 一些模型仅仅减少encoder的tokens数量,而没有设计增强前景语义表达的机制,导致性能难以提升。
也就是说,现有的模型前景特征选择策略并不优化,语义级别的细分不足,多尺度特征的关联被忽略,降低了模型的上限。那么论文提出的方法是怎么解决这些问题的呢?
这篇论文提出了Focus-DETR来聚焦更具信息量的tokens,其核心是设计了分级语义判别机制。作者设计了一个tokens评分机制,同时考虑定位和语义分类信息。首先通过前景tokens选择器基于多尺度特征进行前景选择,然后引入多类别评分预测器选择更细粒度的对象tokens。这样可以获取两个层次的语义细分。在这个可靠的评分机制指导下,不同语义级别的tokens被输入到双注意力编码器中。细粒度对象tokens首先进行自注意力增强表达,然后散落回前景tokens中以弥补可变形注意力的限制,从而提升前景queries的语义。通过逐步引入语义信息进行细粒度判别,Focus-DETR重构了编码器的计算流程,在最小的计算量下增强了细粒度tokens的语义。也就是说,Focus-DETR通过设计语义级别的渐进式判别和细粒度表示的增强注意力,使得transformer encoder可以高效聚焦在信息量更大的特征上,在降低计算量的同时提升了检测性能。相比之前过于依赖DAM的方法,本文通过引入定位和语义双重信息进行多级语义判别,并在此基础上进行表示增强,可靠性更高,从而取得了更好的性能。
2. 方法
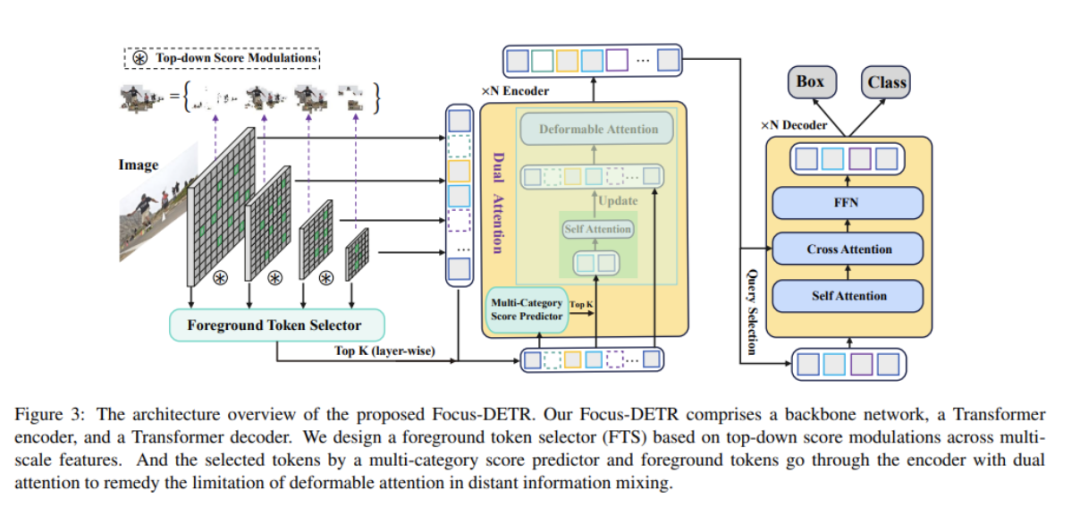
2.1 Model Architecture
整体来看,论文提出模型的结构主要分为以下部分:
- 骨干网络(Backbone):可以使用ResNet或Swin Transformer等进行特征提取。
- 前景Token选择器(Foreground Token Selector):基于多尺度特征图进行由上而下的评分调制,选择前景tokens。
- 多类别评分预测器(Multi-Category Score Predictor):基于前景SCORE和类别预测值选择更细粒度的对象tokens。
- 双注意力编码器(Dual Attention Encoder):包含自注意力模块对细粒度tokens进行增强表示,和可变形注意力模块来混合远程信息。
- 解码器(Decoder):包含自注意力模块和交叉注意力模块,最终预测bounding box和类别。
整体来看,Focus-DETR通过设计前景和细粒度tokens的评分机制,将不同语义级别的tokens输入双注意力编码器中进行特征增强,在降低计算量的同时提升了检测性能。下面我们来具体介绍论文提出方法的各个组件。
2.2 Scoring mechanism

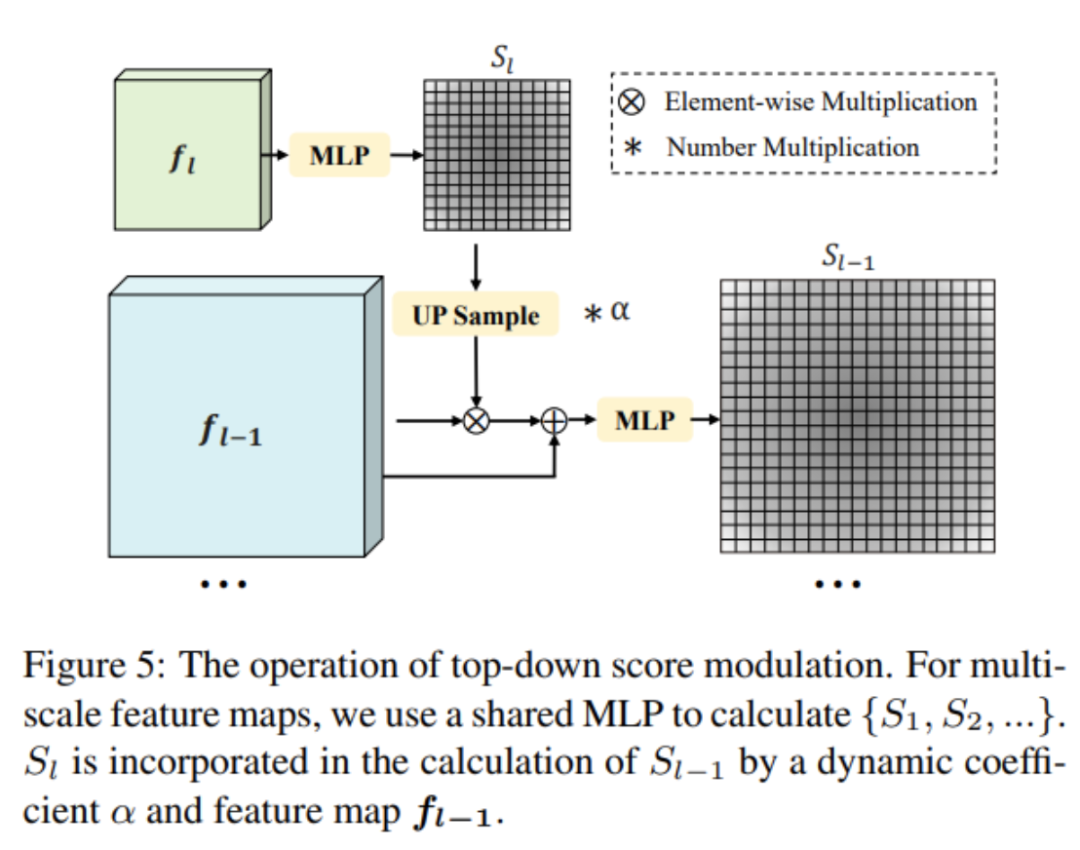
前景Token选择器(Foreground Token Selector)的工作流程如下:
-
基于多尺度特征图{f1, f2,...fL},使用共享的MLP网络预测每个token的前景分数Sl。
-
将高层语义的前景分数作为低层的补充信息,进行由上而下的评分调制。具体地是:
这里UP表示上采样函数,MLP_F预测前景概率,αl是学习的调制系数。
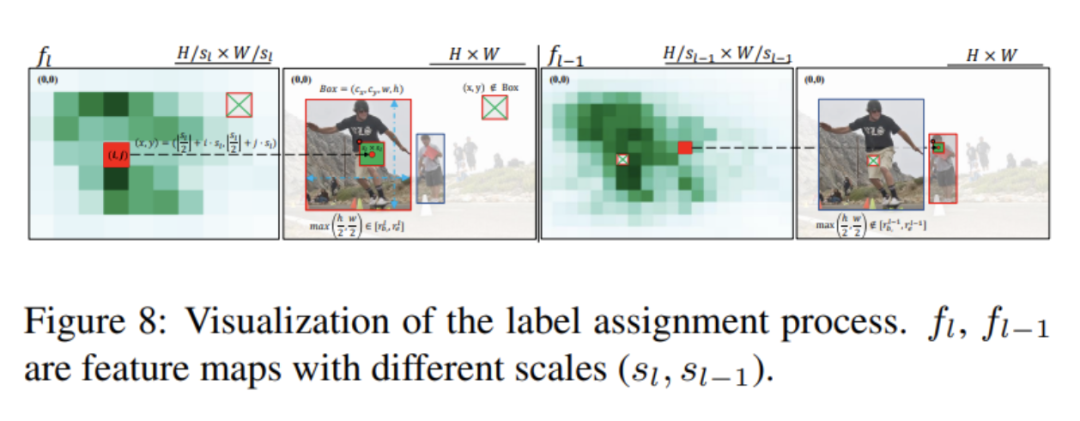
根据ground truth box,我们为每个token打上前景或者背景的标签,作为选择器的监督信号。具体通过上述进行标签分配。
-
多尺度特征图上的大尺度前景分数与语义信息会调制小尺度的特征图,增强选择的可靠性。
-
前景Token选择器充分利用了由上而下的语义指导,可以更准确地选择前景区域,为后续的表示增强提供基础。
而多类别评分预测器(Multi-Category Score Predictor)的工作流程如下:
- 在选择出前景tokens的基础上,为了精细选择对象tokens,引入了多类别评分预测器。
- 计算每个token的前景概率和额外的类别预测概率。
- 将两者相乘作为最终的细粒度tokens评分,即:这里来自额外的类别预测分支。
- 同时结合了token的定位和语义信息,可以选择出对象性更强的细粒度tokens。
- 与Deformable DETR不同,这里的类别预测不包括背景类别,避免对背景tokens进行计算。
- 根据pj选择topk的细粒度tokens进行进一步的表示增强。
多类别预测器基于前景tokens,引入语义信息选择更细粒度、更具代表性的对象tokens,为后续的表示增强提供支持。
2.3 Calculation Process of Dual Attention

Focus-DETR设计了Dual Attention Encoder来进行表示的增强。具体来说,首先根据前文设计的评分机制,可靠地选择出前景区域tokens和更细粒度的对象tokens。然后,将这些细粒度的对象tokens先进行自注意力模块的计算,增强这些tokens之间的语义信息交互。经过自注意力增强的细粒度对象表示,会被散落回到对应的前景tokens的位置中,以弥补可变形注意力在远程tokens信息融合方面的局限性。这样一来,前景tokens就同时结合了全局上下文信息和增强的细粒度对象语义信息。整个编码器中,重复这样的代表增强流程进行层次化的特征学习。这种双注意力编码器的设计,既考虑了计算效率,只对少量细粒度tokens进行额外的自注意力计算,也提升了前景特征表示的discrimination,有效地增强了前景语义信息。因此,双注意力编码器在最小的计算量下,有效地提升了Focus-DETR模型的检测性能。
2.4 Complexity Analysis
从双层注意力机制上,我们可以看出双注意力编码器的计算代价是可控的。具体来说,作者先分析了可变形注意力模块在编码器和解码器中的计算复杂度,发现编码器占主要的计算量。然后定义了细粒度tokens增强模块的计算复杂度。在典型的设置下,其计算量相比整个模型 Transformer 部分的计算量仅为2.5%左右。这说明,虽然引入了双注意力编码器和细粒度tokens的自注意力增强,但其对总体计算量的影响可以忽略。这得益于本文设计的评分机制,使得进入细粒度自注意力的tokens数量是可控的。所以,双注意力编码器在改善模型性能的同时,计算量的增加是在可接受范围内的。这充分证明了Focus-DETR在降低计算量和提高效率方面的有效性。
3. 实验
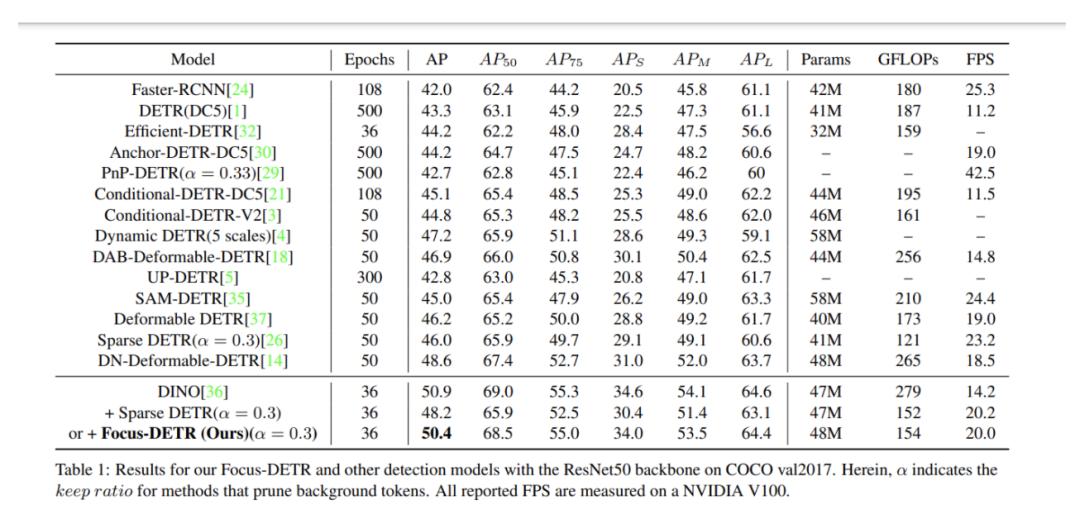
根据论文Table 1的实验结果,我们可以看到Focus-DETR相比其他检测方法取得了以下效果:与其他efficient DETR方法如PnP-DETR相比,在类似计算量下,Focus-DETR的性能更优。例如与PnP-DETR相比,获得了7.9的AP提升。将Sparse DETR集成到DINO中构建了一个强大的基准,而Focus-DETR比这个基准还高出2.2的AP,证明了其在token选择上的优势。与原DINO相比,Focus-DETR只损失了0.5的AP,但计算量降低了45%,推理速度提升了40.8%,这充分体现了其在计算效率上的优势。从精度计算量曲线来看,Focus-DETR相比其他检测transformer模型,在相似的计算量下能够取得最佳的检测性能。使用其他backbone如ResNet101和Swin Transformer,Focus-DETR仍能保持非常强的性能。
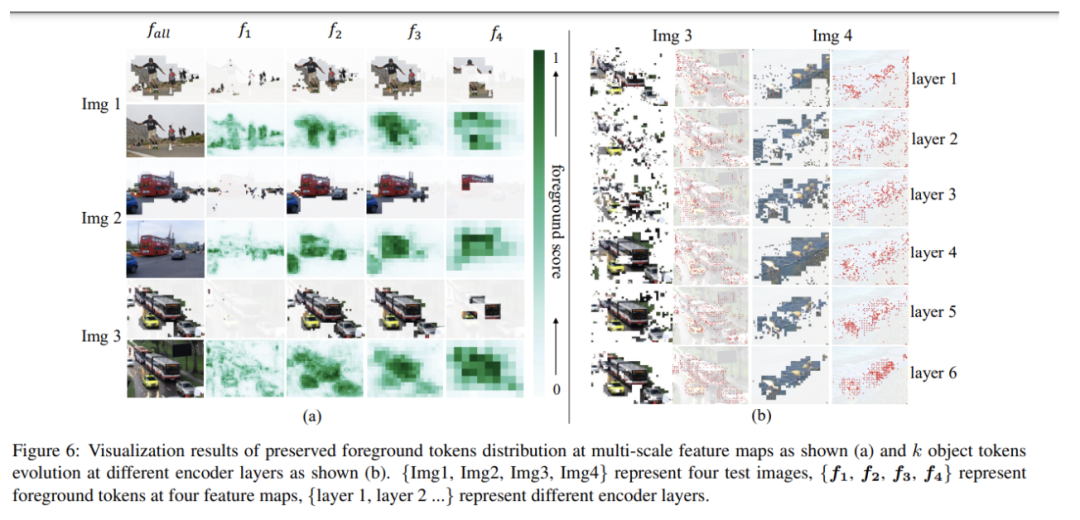
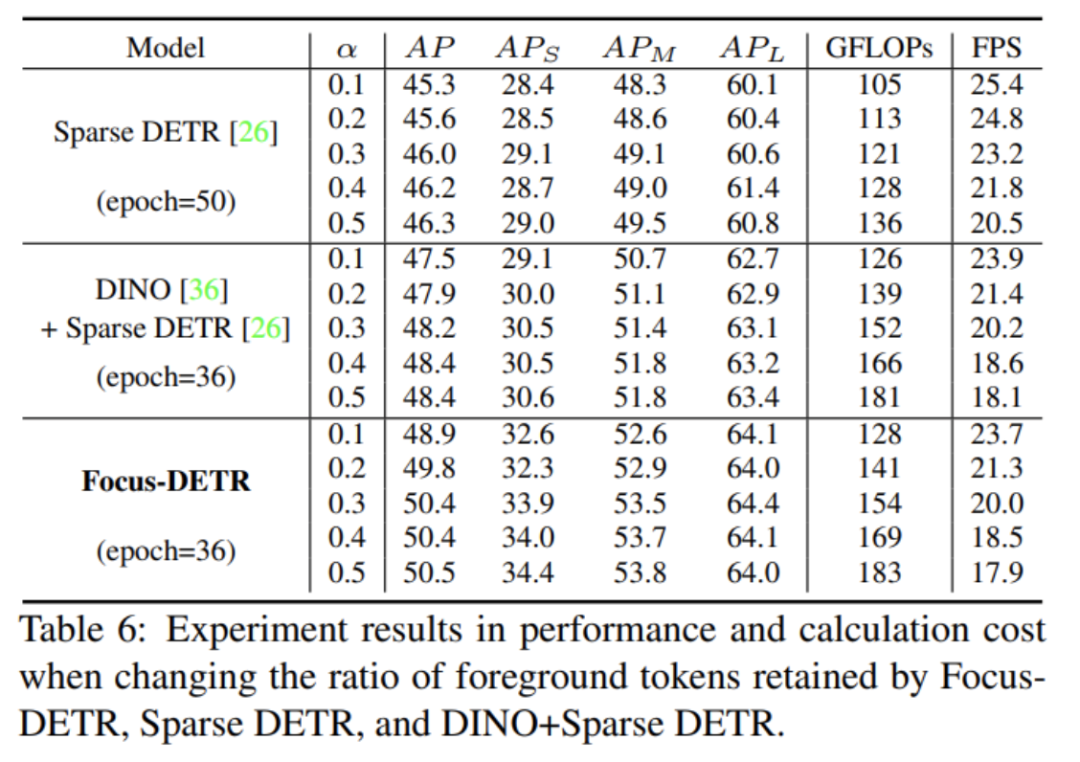
根据论文Table 6的结果,我们可以分析不同模型在改变保留前景tokens的比例时,性能和计算量的变化:当保留tokens的比例为0.1时,Focus-DETR比Sparse DETR高1.6AP,比DINO+Sparse DETR高1.4AP,验证其在小比例下的优势。而在0.2的tokens保留比例下,Focus-DETR仍分别领先Sparse DETR和DINO+Sparse DETR 1.2AP和1.9AP。同时当tokens保留比例为0.3时,这也是论文的默认设置,Focus-DETR比Sparse DETR高2.7AP,比DINO+Sparse DETR高1.4AP,优势更加明显。在更高的保留比例0.4和0.5下,Focus-DETR仍能保持紧凑的领先优势。从计算量来看,随着保留tokens的增加,各模型的GFLOPs成正比上升,而FPS下降。但Focus-DETR始终保持了较高的推理速度。也就是说总体上,Focus-DETR在任何tokens保留比例下,相比其他模型都能取得显著的性能提升,验证了其在前景选择上的效果。
4. 讨论
相较于其他基于DETR的目标检测方法,Focus-DETR的特别之处和主要优势包括:
- Focus-DETR设计了一个多级语义判别机制,通过前景token选择器和多类别评分预测器,融合定位和语义信息,进行由粗到细的tokens选择,使得进入编码器的tokens更加聚焦和具有代表性。
- 在粗略的前景tokens选择后,Focus-DETR引入了细粒度的对象tokens选择,通过自注意力模块增强了这些细粒度tokens的语义表达。这种级联的语义选择和表示增强机制,使得编码器可以高效地聚焦在对检测任务更关键的语义上。
- Focus-DETR采用了双注意力编码器,通过细粒度tokens增强来弥补可变形注意力的信息聚合局限,充分增强了前景语义表达。同时计算量可控,只需对少量tokens进行额外计算。
- 综上,通过设计语义级别的渐进式判别和细粒度表示的增强注意力,Focus-DETR使编码器可以更高效地聚焦在对检测更关键的语义上,从而在降低计算量的同时提升了检测精度。这是其相对于其他DETR检测方法的显著优势所在。
5. 结论
本文提出了Focus-DETR,其目标是通过设计分级语义判别机制来聚焦更具信息量的tokens,在提高计算效率的同时保持模型精度。本文设计了一个多级语义判别机制,包含前景token选择器和多类别评分预测器,可以获得两个层次的语义细分。基于语义判别结果,将不同层次的tokens输入双注意力编码器中,通过细粒度tokens的自注意力增强来提升前景语义。Focus-DETR重构了编码器的计算流程,在最小的计算量下增强了细粒度tokens的语义。实验结果表明,Focus-DETR与其他检测transformer相比,在类似计算量下取得了最佳的性能。总体而言,通过设计语义级别的渐进式判别和细粒度表示的增强注意力,Focus-DETR提出了一种更加高效的基于transformer的检测框架,取得了计算效率与模型精度的更好平衡。