
CNN训练循环重构——超参数测试 | PyTorch系列(二十八)
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

推荐
这个系列很久没有更新了,最新有小伙伴反馈官网的又更新了,因此,我也要努力整理一下。这个系列在CSDN上挺受欢迎的,希望小伙伴无论对你现在是否有用,请帮我分享一下,后续会弄成电子书,帮助更多人!
欢迎来到这个神经网络编程系列。 在这一节中,我们将看到如何在保持训练循环和组织结果的同时,轻松地试验大量的超参数值。
清理训练循环并提取类别
当我们在训练循环中退出几节时,我们建立了很多功能,使我们可以尝试许多不同的参数和值,并且还使训练循环中的调用需求可以得到结果 进入TensorBoard。
所有这些工作都有所帮助,但是我们的训练循环现在非常拥挤。在本节中,我们将清理训练循环,并使用上次构建的RunBuilder类并构建一个名为RunManager的新类,为进一步的实验打下基础。
我们的目标是能够在顶部添加参数和值,并在多次训练中测试或尝试所有值。
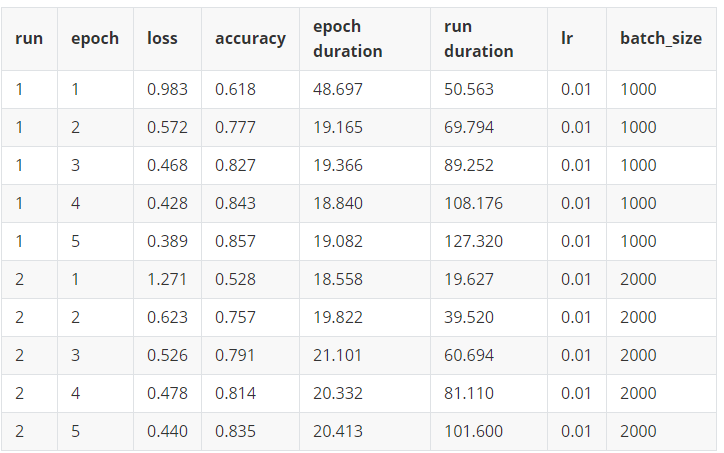
例如,在这种情况下,我们要使用两个参数lr和batch_size,对于batch_size,我们要尝试两个不同的值。这总共给了我们两次训练。批次大小不同时,两次运行的学习率相同。
params = OrderedDict(lr = [.01],batch_size = [1000, 2000])
对于结果,我们希望看到并能够比较两次运行。
我们将建立的两个类
为此,我们需要建立两个新类。在上一节中,我们构建了名为RunBuilder的第一个类。它被称为顶部。
for run in RunBuilder.get_runs(params):现在,我们需要构建此RunManager类,该类将使我们能够管理运行循环中的每个运行。RunManager实例将使我们能够提取许多繁琐的TensorBoard调用,并允许我们添加其他功能。
我们将看到,随着我们的参数和运行数量变大,TensorBoard将开始崩溃,作为一种可行的解决方案,用于审查我们的结果。
在我们每次运行的不同阶段,将调用RunManager。在运行阶段和纪元阶段的开始和结束时,我们都会有呼叫。我们还将调用跟踪每个epoch内的损失和正确预测的数量。最后,我们将运行结果保存到磁盘。
让我们看看如何构建此RunManager类。
构建用于训练循环运行的RunManger
让我们从imports 开始吧:
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Fimport torchvisionimport torchvision.transforms as transformsfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterfrom IPython.display import display, clear_outputimport pandas as pdimport timeimport jsonfrom itertools import productfrom collections import namedtuplefrom collections import OrderedDict
首先,我们使用class关键字声明该类。
class RunManager():接下来,我们将定义类构造函数。
def __init__(self):self.epoch_count = 0self.epoch_loss = 0self.epoch_num_correct = 0self.epoch_start_time = Noneself.run_params = Noneself.run_count = 0self.run_data = []self.run_start_time = Noneself.network = Noneself.loader = Noneself.tb = None
现在,我们将在构造函数中不使用任何参数,而只定义一些属性,这些属性使我们能够跨运行和跨epoch跟踪数据。
我们将跟踪以下内容:
epoch 数
一个epoch的loss。
某个epoch的正确预测数。
epoch的开始时间。
记得我们看到RunManager类有两个名称为epoch的方法。我们有begin_epoch()和end_epoch()。这两种方法将使我们能够在整个epoch周期中管理这些值。
现在,接下来我们有一些运行属性。我们有一个名为run_params的属性。这是关于运行参数的运行定义。它的值将是RunBuilder类返回的运行之一。
接下来,我们具有跟踪run_count和run_data的属性。run_count为我们提供了运行编号,run_data是一个列表,我们将使用它来跟踪每次运行的参数值和每个epoch的结果,因此我们将看到为每个列表添加一个值时代。然后,我们有了运行开始时间,该时间将用于计算运行持续时间。
好了,接下来,我们将保存用于运行的网络和数据加载器,以及可用于为TensorBoard保存数据的SummaryWriter。
What Are Code Smells?
你闻到了吗?这段代码有些不对劲。您以前听说过代码异味吗?你闻到它们了吗?code smell 是一个术语,用于描述一种条件,在这种情况下,我们眼前的代码似乎不正确。对于软件开发人员而言,这就像一种直觉。
code smell 并不表示一定有问题。code smell 并不表示代码不正确。这只是意味着可能有更好的方法。在这种情况下,code smell就是我们有几个带有前缀的变量名称。在这里使用前缀表示变量以某种方式属于在一起。
每当我们看到这种情况时,我们都需要考虑删除这些前缀。在一起的数据应该在一起。这是通过将数据封装在类内部来完成的。毕竟,如果数据属于同一类,则面向对象的语言使我们能够使用类表达这一事实。
通过提取类进行重构
现在可以保留此代码,但是稍后我们可能要通过执行所谓的提取类来重构此代码。这是一种重构技术,其中我们删除了这些前缀,并创建了一个名为Epoch的类,该类具有以下属性:count,loss,num_correct和start_time。
class Epoch():def __init__(self):self.count = 0self.loss = 0self.num_correct = 0self.start_time = None
然后,我们将这些类变量替换为Epoch类的实例。我们甚至可以将count变量更改为更直观的名称,例如数字或id。我们之所以现在就离开这个原因是因为重构是一个迭代过程,这是我们的第一次迭代。
提取类将创建抽象层
实际上,通过构建此类,我们现在正在做的是从我们的主要训练循环程序中提取一个类。我们正在解决的代码味道是这样的事实,即我们的循环变得混乱,开始显得过于复杂。
当我们编写一个主程序然后对其进行重构时,我们可以想到这种创建抽象层的方法,这些抽象层使主程序变得越来越易读和易于理解。程序的每个部分都应该很容易理解。
当我们将代码提取到其自己的类或方法中时,我们将创建其他抽象层,并且如果我们想了解任何这些层的实现细节,那么可以这么说。
以一种迭代的方式,我们可以考虑从一个程序开始,然后再提取出创建越来越深层的代码。该过程可以看作是分支树状结构。
开始训练循环
无论如何,让我们看一下该类的第一个方法,该方法提取开始运行所需的代码。
def begin_run(self, run, network, loader):self.run_start_time = time.time()self.run_params = runself.run_count += 1self.network = networkself.loader = loaderself.tb = SummaryWriter(comment=f'-{run}')images, labels = next(iter(self.loader))grid = torchvision.utils.make_grid(images)self.tb.add_image('images', grid)self.tb.add_graph(self.network, images)
首先,我们捕获运行的开始时间。然后,我们保存传入的运行参数,并将运行计数增加一。之后,我们保存了网络和数据加载器,然后为TensorBoard初始化了SummaryWriter。注意我们如何将运行作为注释参数传递。这将使我们能够唯一标识TensorBoard内部的运行。
好了,接下来,我们在训练循环中进行了一些TensorBoard调用。这些调用将我们的网络和一批图像添加到TensorBoard。
结束运行时,我们要做的就是关闭TensorBoard手柄,并将epoch计数重新设置为零,以准备进行下一次运行。
def begin_epoch(self):self.epoch_start_time = time.time()self.epoch_count += 1self.epoch_loss = 0self.epoch_num_correct = 0
现在,让我们看一下操作的大部分发生在哪里,该操作结束了一个epoch。
def end_epoch(self):epoch_duration = time.time() - self.epoch_start_timerun_duration = time.time() - self.run_start_timeloss = self.epoch_loss / len(self.loader.dataset)accuracy = self.epoch_num_correct / len(self.loader.dataset)self.tb.add_scalar('Loss', loss, self.epoch_count)self.tb.add_scalar('Accuracy', accuracy, self.epoch_count)for name, param in self.network.named_parameters():self.tb.add_histogram(name, param, self.epoch_count)self.tb.add_histogram(f'{name}.grad', param.grad, self.epoch_count)...
我们首先计算epoch 持续时间和运行持续时间。由于我们处于一个epoch的末尾,因此epoch的持续时间是最终的,但此处的运行时长表示当前运行的运行时间。该值将一直运行,直到运行结束。但是,我们仍将在每个epoch保存它。
接下来,我们计算epoch_loss和准确性,并根据训练集的大小进行计算。这给了我们每个样本的平均损失。然后,我们将这两个值都传递给TensorBoard。
接下来,像以前一样,将网络的权重和渐变值传递给TensorBoard。
跟踪我们的训练循环表现
我们现在准备好进行此处理中的新功能。这是我们要添加的部分,以便在执行大量运行时为我们提供更多的见解。我们将自己保存所有数据,以便我们分析超出TensorBoard大小的数据。
def end_epoch(self):...results = OrderedDict()results["run"] = self.run_countresults["epoch"] = self.epoch_countresults['loss'] = lossresults["accuracy"] = accuracyresults['epoch duration'] = epoch_durationresults['run duration'] = run_durationfor k,v in self.run_params._asdict().items(): results[k] = vself.run_data.append(results)df = pd.DataFrame.from_dict(self.run_data, orient='columns')...
在这里,我们正在构建一个字典,其中包含我们在运行中关心的键和值。我们添加run_count,epoch_count,loss ,accuracy, epoch_duration和run_duration。
然后,我们遍历运行参数中的键和值,将它们添加到结果字典中。这将使我们能够看到与性能结果相关的参数。
最后,我们将结果附加到run_data列表中。
将数据添加到列表后,我们将数据列表转换为pandas数据框,以便可以格式化输出。
接下来的两行特定于Jupyter笔记本电脑。我们清除当前输出并显示新的数据框。
clear_output(wait=True)display(df)
好了,这结束了一个epoch。您可能想知道的一件事是如何跟踪epoch_loss和epoch_num_correct值。为此,我们下面有两种方法。
def track_loss(self, loss):self.epoch_loss += loss.item() * self.loader.batch_sizedef track_num_correct(self, preds, labels):self.epoch_num_correct += self.get_num_correct(preds, labels)
我们有一个称为track_loss()的方法和一个名为track_num_correct()的方法。这些方法在每次批处理之后在训练循环内调用。损失将传递到track_loss()方法中,而预测和标签将传递到track_num_correct()方法中。
为了计算正确的预测数,我们使用与先前情节中定义的相同的get_num_correct()函数。此处的区别在于该函数现在封装在我们的RunManager类中。
def _get_num_correct(self, preds, labels):return preds.argmax(dim=1).eq(labels).sum().item()
最后,我们有一个名为save()的方法,用于将run_data保存为两种格式,即json和csv。此输出将进入磁盘,并可供其他应用使用。例如,我们可以在excel中打开csv文件,甚至可以使用数据构建自己更好的TensorBoard。
def save(self, fileName):pd.DataFrame.from_dict(self.run_data, orient='columns').to_csv(f'{fileName}.csv')with open(f'{fileName}.json', 'w', encoding='utf-8') as f:json.dump(self.run_data, f, ensure_ascii=False, indent=4)
现在,我们可以在训练循环中使用此RunManager类。
如果我们在下面使用以下参数:
params = OrderedDict(lr = [.01],batch_size = [1000, 2000],shuffle = [True, False])
这些是我们得到的结果:
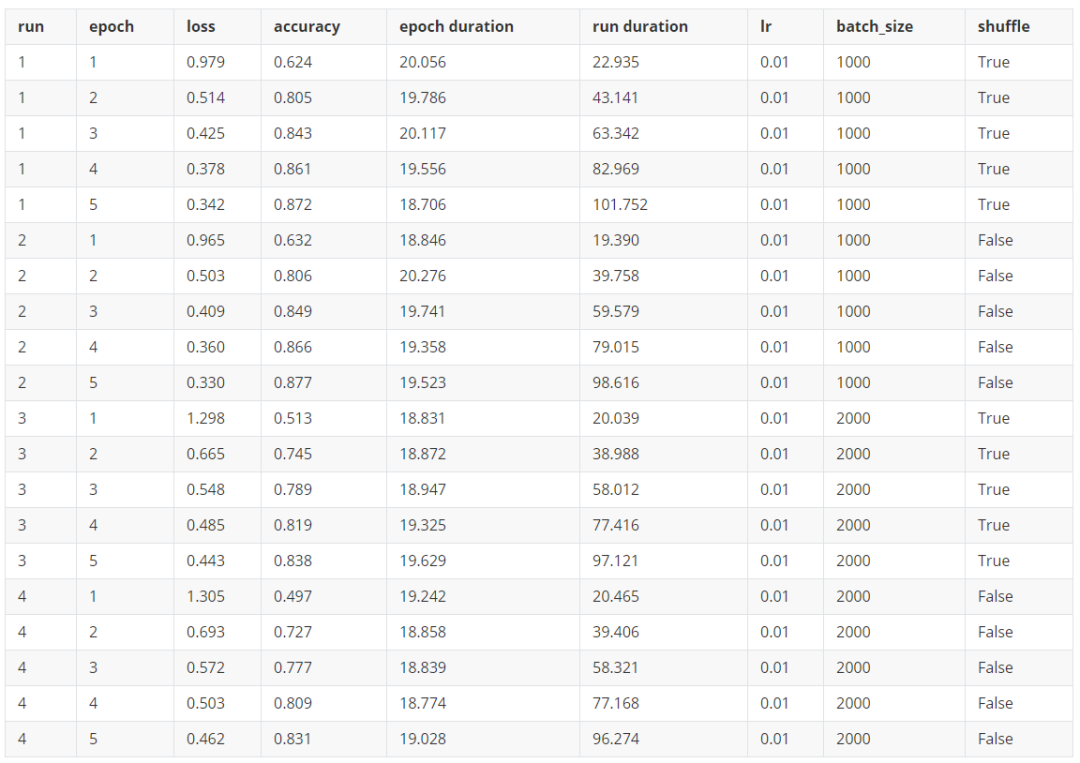
感觉哪里错了?
哇 像怪人。你好。别管我 我只是在这里重构代码并思考这个问题。哦。您想知道问题是什么。好吧,问题是这样的。错是什么感觉?
也许我们可以形容它感觉很不好。或者,也许我们可能将其描述为尴尬或羞辱。
好吧,不。实际上,这不是感觉错误的方式。这些是我们知道自己错了之后的感觉,在这种情况下,我们不再是错误的了。
根据这一事实,我们可以推断出实际上的感觉是错的。那是。在我们意识到之前,感觉上是错的就是感觉上是对的
文章中内容都是经过仔细研究的,本人水平有限,翻译无法做到完美,但是真的是费了很大功夫,希望小伙伴能动动你性感的小手,分享朋友圈或点个“在看”,支持一下我 ^_^
英文原文链接是:
https://deeplizard.com/learn/video/NSKghk0pcco



加群交流
欢迎小伙伴加群交流,目前已有交流群的方向包括:AI学习交流群,目标检测,秋招互助,资料下载等等;加群可扫描并回复感兴趣方向即可(注明:地区+学校/企业+研究方向+昵称)
