
Flink 数据湖 助力美团数仓增量生产
一、美团数仓架构图
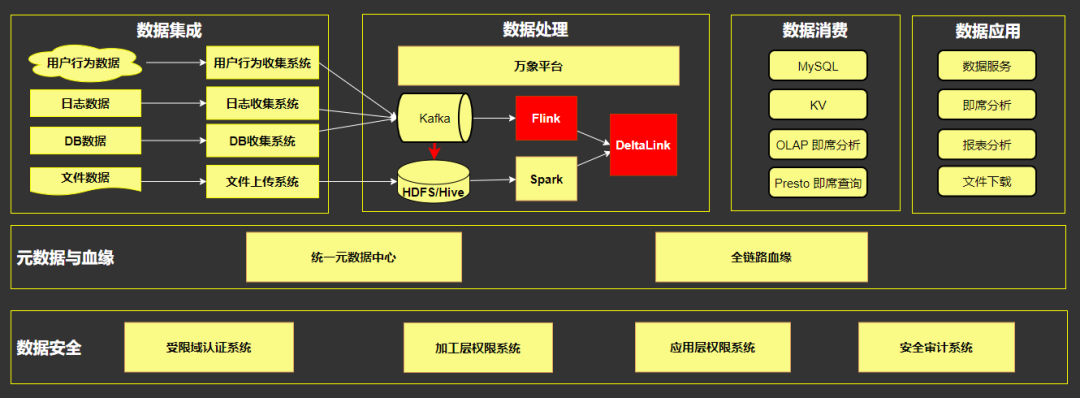
二、美团当前 Flink 应用场景和规模
实时数仓、经营分析、运营分析、实时营销 推荐、搜索 风控、系统监控 安全审计

三、基于 Flink 的流式数据集成
1. 数据集成 V1.0

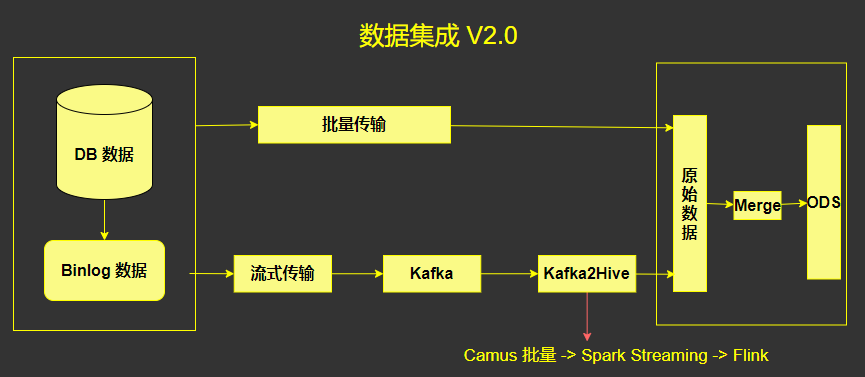
2. 数据集成 V2.0
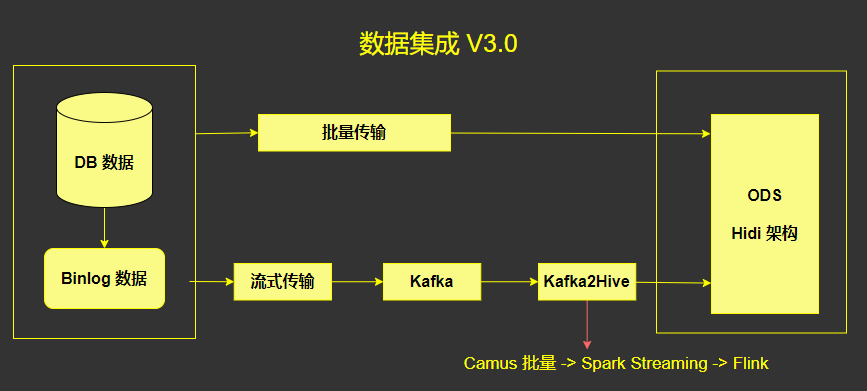
3. 数据集成 V3.0
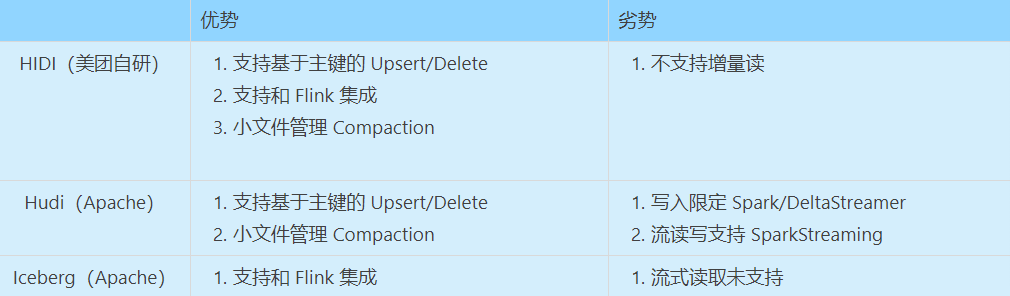
4. 美团自研的 Hidi
支持增量读取,也就是读取当前时间到前一段时间的数据, 才能做到增量; 支持基于主键的 Upsert/Delete。Hidi 是美团在 2,3 年前,在内部自研的架构,此架构的特性在于: 支持 Flink 引擎读写; 通过 MOR 模式支持基于主键的 upsert/Delete; 小文件管理 Compaction; Table Schema
四、基于 Flink 的增量生产
1、传统离线数仓特性分析
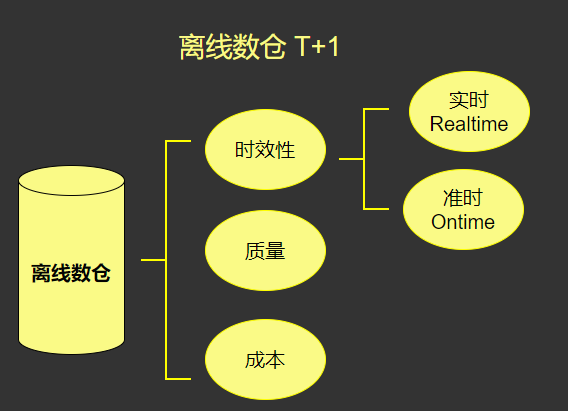
2. 增量生产
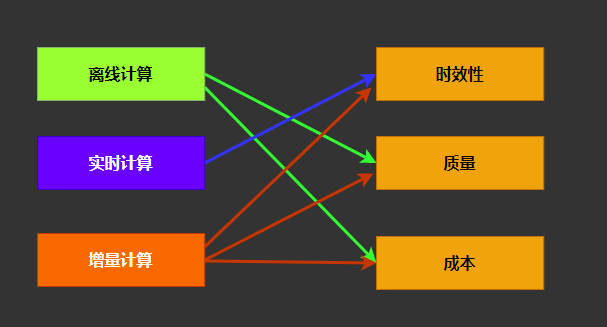
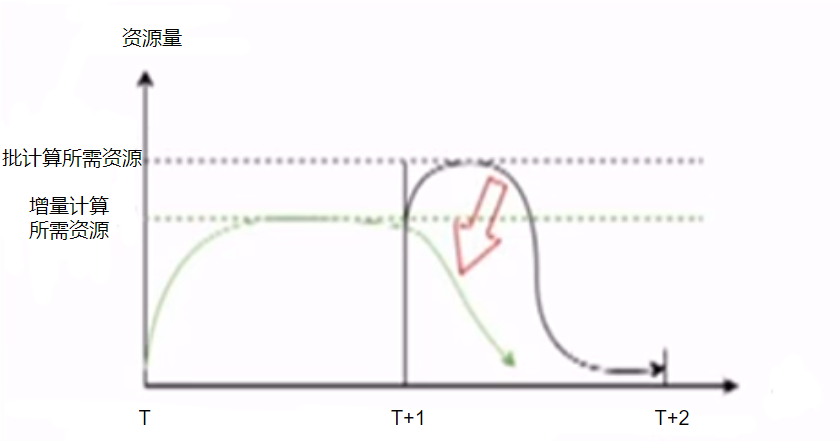
3. 增量计算的优点

4. 增量生产架构图
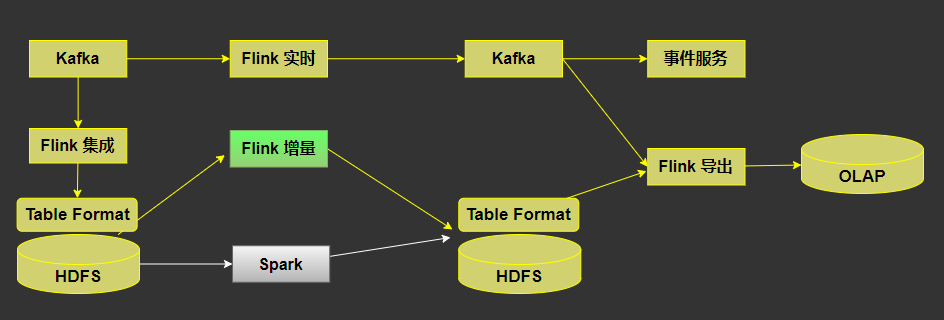
Flink SQL 能力能够对齐 Spark SQL; Hidi 支持 Upsert/Delete 特性(Hidi 已支持); Hidi 支持全量和增量的读取,全量读取用于查询和修复数据,增量读取用来增量生产;
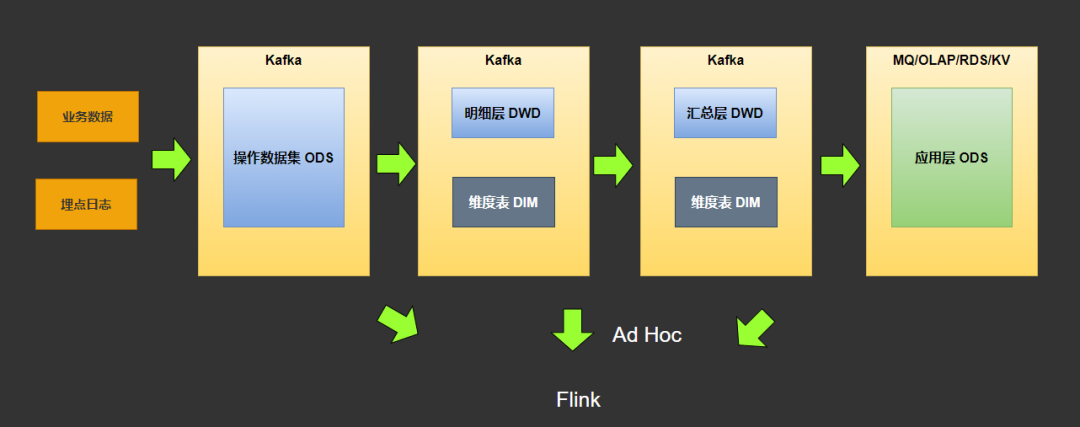
五、实时数仓模型与架构

六、流式导出与 OLAP 应用
1. 异构数据源的同步
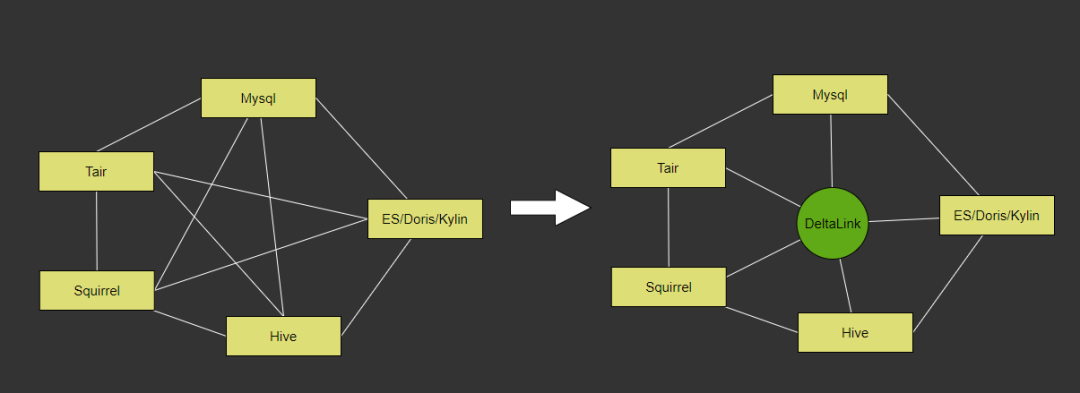
2. 第一版实现

工具平台层,对接用户,用来配置同步任务,配置调度,运维任务; 调度层,负责任务的调度,管理任务状态管理,以及执行机的管理,这其中有非常多的额外工作都需要自己做; 执行层,通过 DataX 进程,以及 Task 线程从源存储同步到目标存储。
3. 第二版实现

4. 基于 Flink 的同步架构关键设计
避免跨 TaskManager 的 Shuffle,避免不必要的序列化成本;Source 和 Sink 尽量在同一个 TaskManager; 务必设计脏数据收集旁路和失败反馈机制;数据同步遇到脏数据的时候,比如失败了 1% 的时候,直接停下来; 利用 Flink 的 Accumulators 对批任务设计优雅退出机制;数据传输完之后,通知下游数据同步完了; 利用 S3 统一管理 Reader/Writer 插件,分布式热加载,提升部署效率;很多传输任务都是小任务,而作业部署时间又非常长,所以需要要提前部署插件;
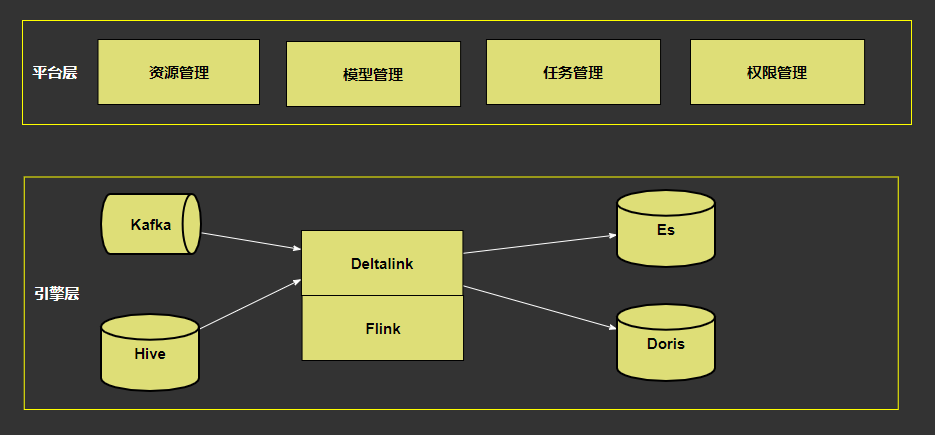
5. 基于 Flink 的 OLAP 生产平台
七、 未来规划
评论