
数仓已死?数据湖当立!
前言
前两天,我详细剖析了一下这两天脉脉上很火的数据建模帖子。指出来帖子里百度小哥“只见宽表不见建模”的核心原因是整个数据圈的核心逻辑变了。
然后就引起了建模群里一帮人在疯狂吐槽。

也有大厂的数仓大佬高屋建瓴,指点江山,侃侃而谈。

为啥吐槽?因为我们知道,这再也不是以前数据至上、工程为先的俄罗斯方块游戏了,而是客户至上、业务为先的神庙逃亡游戏。
但是绝大多数企业的数据仓库工程师,究竟还是沦落到拉宽表的境地。
大清都亡了,你上哪找辫子去啊?
玩法变了
早些年,业务变化还没那么频繁,战略是一年定一次,KPI 政策是一年发布一次。
我们有充足的时间去规划、业务建模、领域建模、逻辑建模、物理建模、验证模型。如同那时候的爱情,车马慢,一生只够爱一人。

那时候行业的玩法基本一致,所以也有了 FSLDM 这种经典数据模型可以套用。一个模型搞定一个行业有没有?
但是现在,谁家的玩法跟别人一毛一样?没有!就算是短视频界的两个直接竞争对手--抖音和快手,都是那么迥然不同的逻辑:
一个偏向算法推荐,一个偏向社交关系。
更不用说现在火热的社区团购,都在抢占市场,业务模式每天都在变。
我自己都不敢相信,我会建设一个能够支持 KPI 政策一个月一调整的 KPI 数仓+核算体系!
玩法真的变了!这世道变了!
建模变了
在这种边开飞机边换发动机的时代,传统数仓规规矩矩建设的逻辑就不好使了,开始朝着非常诡异的方向发展。
一个方向,是规模大、技术强、业务趋于稳定的企业,如阿里、美团的固有业务,他们开始尝试一种全新的建模理念。
他们的主题域划分根本不遵循老一套的“中性、通用”,而是“个性、专用”。所以他们采用的是按业务流程划分主题域,因为这样才能更方便的支撑上面的业务指标体系。这样弄,上哪提炼一个通用的模型去啊?
在建模的时候,传统建模,DWD 层必须是范式建模,而且一般不对外提供服务。如果各部门需要明细数据,则各自建立 DM 解决。
而现在这些大厂的建模方式,则是尽可能压缩范式建模的范围,扩大维度建模的深度。以结构化指标体系开道,用维度模型向下不断穿透,直到 DWD 层。
是的,DWD 层也是维度建模。所有 ID 统一、代码转换、数据打平的事情放在哪里做?ETL 里做。
哦,不!应该改叫 ELT 了。先 Load ,再 Transformation 。因为超大量的数据输入,我们必须首先解决数据吞吐量的问题。
另一个方向,是那些创业公司或者大公司的新业务。这类场景的特点是业务一直在变,产品功能也在变,业务数据库也在变。
在这种场景中传统数据仓库建设的逻辑完全失效。因为根本不可能有人能在这么短的时间内,设计出一个能适应 2 周一次的迭代速度的数据仓库模型。
所以他们选择了简单粗暴的拉宽表!
这就是脉脉上百度小哥疯狂吐槽的根本原因。不是不去建模,而是根本没时间、没条件给你建模。
数仓已死?
那种业务趋于稳定的大厂毕竟是少数,更多的情况是创业公司、业务不断试错、调整的小厂。
在业务 1 个月变一次方向、产品 2 周迭代一次、业务数据库不断更新还没人告诉你的地狱模式下,基本上宣告了数据仓库的死亡!
这就像是在玩游戏。
以前是玩俄罗斯方块,我们得精心设计好,每一块砖都要放在合理的地方,垒的整整齐齐,等待那一根棍子的到来。
而现在,是在玩神庙逃亡,操作方式同样都是上下左右,但是你根本没办法想合理、结构、布局,稍微迟疑一些,就被怪兽咬到屁股了。
而对于那些业务日趋稳定的大厂,数据仓库同样也有巨大的困扰。就像新能源汽车车主总有里程焦虑一样,几乎所有的离线数仓工程师都害怕任务失败。
任务失败就意味着报表出不来,就意味着运营的白眼和扣绩效。
另外,我们的增量入库方案,由于数据迟到、业务逻辑复杂等各种原因,慢慢的变得越来越复杂。以至于一些小公司干脆直接每天全量,这导致数据延迟更加严重。
貌似一切正常的离线数仓 T+1 延迟,成为压死数仓的最后一根稻草。因为业务部门已经不能满足于看昨天的数据了。
“我们并没有做错什么,但不知为什么,我们输了”,诺基亚 CEO 的声音仿佛萦绕耳边。
什么?你说 Lambda 架构可以满足?是,这样是能出数,但是你拿实时和离线两个结果对比一下试试看?
你现在告诉我,拿什么拯救已然过了互联网淘汰年龄的数据仓库?
数据湖当立
当互联网 HR 对着年龄超限的数据仓库拿出辞退信的时候,另一个 HR 给一个 09 年才出生的小娃娃发出了 Offer 。
它就是数据湖。
它爹是 Pentaho 的 CTO James Dixon。James 创造它的时候,也没想到这家伙能变得这么牛掰。他当初只是想把磁带上存储的所有数据统统倒进一个地方,方便任意探索。
而现在的数据湖,已经成长为一个巨无霸!凭借着基于快照的设计方式、满足快照隔离、优秀的原子性、新元数据等巧妙设计,数据湖拥有了支持批流一体、完美增量入库、入库即可计算等特性。
这些特性意味着什么?
对于 ETL 工程师来说,意味着数据湖没有 T+1 !太令人兴奋了!
但是更兴奋的是大数据架构师,数据湖不仅意味着什么数据都往里扔,更意味着一种新架构的诞生!
一个万能的架构,能够满足算法工程师随意淘换原始数据的架构,能够满足大数据工程师随时拉一张准实时宽表出来的架构,能够满足准实时数据增量接入和即时分析的架构,能够让大数据工程师不用早起看任务是否失败的架构。
架构变了
Kappa 架构中,最无奈的其实是 Kafka ,生把一个 MQ 整成了数据库。这也直接导致了 Kappa 架构无法存储海量数据的弊端。
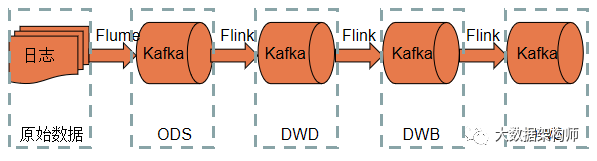
但是这个弊端,数据湖可以解决啊。把 Kafka 改成数据湖之后,问题解决了。 Kafka 也终于歇了口气,可以卸下莫名其妙得到的“数据库”头衔。
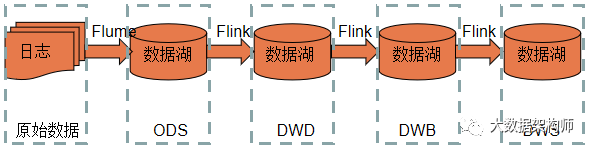
而传统数仓的“数据孤岛问题,在数据湖面前,瞬间荡然无存。因为数据湖本来就是大杂烩,什么都往里装呀!
而且现在已经有各种组件与数据湖产品进行对接了。数据湖真的变成了一个湖!
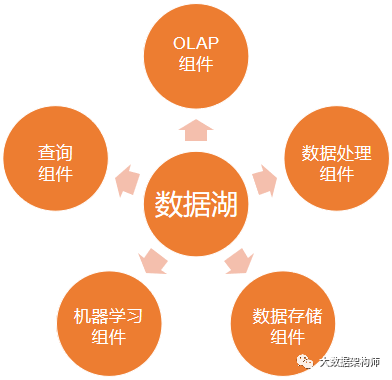
这个架构简直了!
你可以用数据处理组件,从湖里抽数出来,抽完直接做成宽表扔给运营。
也可以写一个 DAG ,数据规整、打通之后扔其他数据库里。
对数据非常了解的人,可以利用查询组件,直接到数据湖里查数据。
算法工程师同样可以直接对接数据湖,从湖里捞原始数据投喂给算法,训练模型。
最关键的一点,OLAP 引擎也能直接对接数据湖!
这个就厉害了!换句话说,咱可以依据这个构建一个超级无敌的 OLAP 体系,准实时、不用复杂的分层建设、不用担心任务跑不完、业务要啥可以快速给出去!
市场变了
你说,这个东东是不是很牛?对你来说是不是很有价值?
是的,不仅对你有价值,对资本市场也很有价值。美国有个公司叫Snowflake,好家伙,直接估值过 1000 亿美金!!!PS 远超其他各大独角兽。
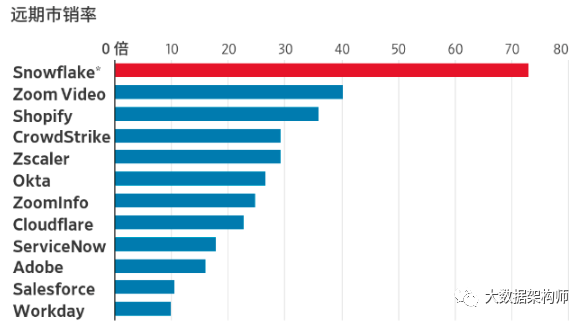
除了 Snowflake 之外,数据湖的老选手亚马逊 AWS 也是一路狂奔,早就有了自己的 OLAP 产品 AWS Athena ,跟自己的数据湖双剑合并,推出了“湖仓一体”的概念。
当然,这里面肯定也少不了中国队的身影,首当其冲的就是阿里系了。阿里的 OSS 大家应该都挺熟悉的,这个存储便宜的要死。
但是你可能不知道,阿里基于 OSS 的存储还整了一个云原生数据湖体系,其中不仅包括了数据湖,还有基于数据湖的 OLAP 产品 DLA !
当然啊,这个价钱嘛,嘿嘿,你懂的。
其他选择也有哈。目前开源的数据湖有江湖人称“数据湖三剑客”的 Delta Lake、IceBerg 和 Hudi。
上面的 OLAP、查询引擎可以用 Kylin、Presto,Spark SQL、Impala等。
这里着重强调一下 Kylin 哈,不仅是因为这是中国团队开源的产品,更重要的是这玩意我们大数据工程师熟啊~~~
而且,就算你不是大数据工程师,是传统数仓工程师,学习起来也不要太简单了!因为这玩意你可以理解为大数据环境下的 Cube。这不就是我们天天在干的活儿么?
当然,Kylin现在已经不局限于传统的Cube,基本上已经把Cube当成Index和存储了。之前分享过,Kylin现在已经支持明细查询和实时查询的功能。
为了帮大家探路,我厚着脸皮找到了 Kylin 创始团队的史少锋大佬,要来了几份半公开的资料。大家自己收着就行哈。
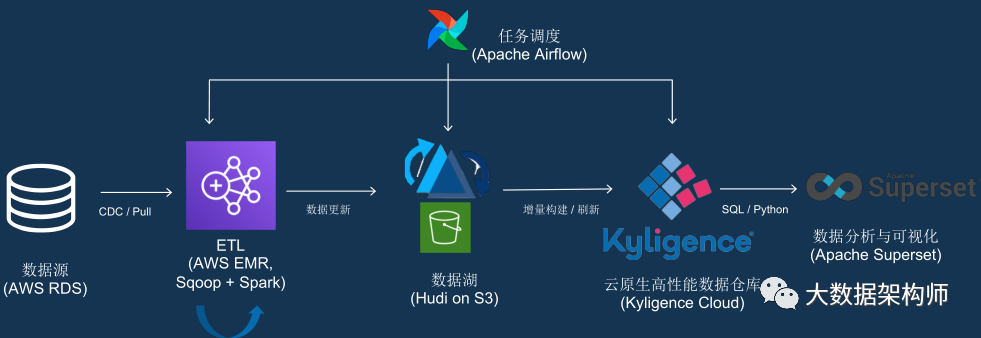
云上数据湖 + Kylin 的这个产品叫 Kyligence Cloud,从上图可以看到它的位置,就在湖之上,可视化之下。因为是直接从湖里取数建 Cube,然后直接展示。这省了多少事儿啊!
有哥们问了,那构建 Cube 不得要时间么?咋说呢,第一次建 Cube,的确要一些时间。但是之后就不需要那么长时间了,因为数据可以增量加载。
因为数据湖的特性,它可以告诉 Kylin 在从上次消费后,有哪些 Partition 发生了修改。这样 Kylin 只要刷新特定的 Partition 就可以了。而且数据湖可以只拉取变化的数据,使得增量修改 Cube 变得可行。如果有查询不能被 Cube 满足,那么直接下压查询数据湖也是支持的,只是性能上会降级到普通水平。
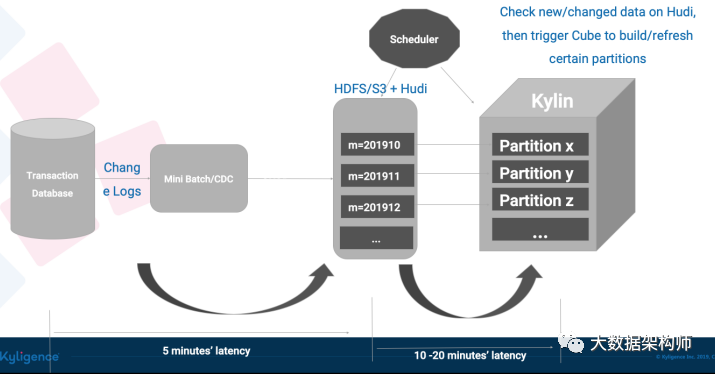
这样,整个数据流,从产生到展示,基本上能控制在半个小时以内。啥?你还嫌慢?
嗯,的确,跟 ClickHouse 比起来,的确是慢一些,我也不是过来跟你掰扯那个工具好,谁的并发量高、速度快。
但是,哥们,咱说句良心话,你真的想成为一个整天“拉宽表”的 SQL Boy 吗?我之前也写过一篇 ClickHouse 的文章,那个快则快矣,但是小心反噬啊。
我们知道,OLAP 其实基本分为三个发展方向:MOLAP、ROLAP 和 HOLAP 。Kylin 是 MOLAP,ClikcHouse 是 ROLAP,这两个产品,犹如倚天屠龙。ClickHouse就是那倚天,追求极致的快,Kylin就是那屠龙,厚重而沉稳。
如果倚天屠龙能合二为一,各自取长补短,那简直无敌了!期待Kylin和ClickHouse团队的合作,推出更牛的产品,让我们的工作更轻松一些。
不过现在么,单纯的 ClickHouse 只能算是辟邪。辟邪虽好,必先自宫啊。ClickHouse 用的多了,那咱练就的一手建模技巧,恐怕就要废了!
你问问那些吐槽天天拉宽表的哥们,就知道其实哥们很悲观。
结语
唉,你以为我在耸人听闻,却不知已然是事实。数仓人的前路该往哪个方向?
这是群里兄弟私信我的问题。说实话,这个问题我不知道怎么回答。时代在变迁,技术在进步,跟不上就必然会淘汰。
前几天我在跑步机上看了《百鸟朝凤》,人们喜欢西洋乐队更甚于传统的唢呐。最后焦师傅赌气吐血吹唢呐,宛若凤凰绝唱的时候,我心都碎了。
我是个老数仓人。05 年实习的时候就在做建仓建模的事情,真心觉得这是个手艺活儿。所以不管怎地,我都得找来 Kylin 的资料,分享给大家。相比起其他工具,Kylin 还是更亲近我们数仓人一些的。
感兴趣的可以戳【原文】直接去试用一下,反正又不要钱,领导问起来也好解释,研究新技术么。好歹给自己简历上多写一句话啊。
唉,数仓不知道死没死,但是数据湖已经来了。大家努力吧,加油!
扩展阅读:【6份数据湖资料+4份Kylin内部解决方案、案例】,公众号“大数据架构师”后台回复“数据湖”,转发即可下载。
感谢阅读,本次分享的内容就结束了。本公众号目前保持日更3000字,为你提供优秀的数据领域的分享。
 点击名片关注大数据架构师
点击名片关注大数据架构师