
超越 ConvNeXt、RepLKNet | 看 51×51 卷积核如何破万卷!


自从
Vision Transformers(ViT) 出现以来,Transformers迅速在计算机视觉领域大放异彩。卷积神经网络 (CNN) 的主导作用似乎受到越来越有效的基于Transformer的模型的挑战。最近,一些先进的卷积模型使用受局部大注意力机制驱动设计了大Kernel的卷积模块进行反击,并显示出吸引人的性能和效率。其中之一,即RepLKNet,以改进的性能成功地将Kernel-size扩展到31×31,但与Swin Transformer等高级ViT的扩展趋势相比,随着Kernel-size的持续增长,性能开始饱和。
在本文中,作者探索了训练大于 31×31 的极端卷积的可能性,并测试是否可以通过策略性地扩大卷积来消除性能差距。这项研究最终得到了一个从稀疏性的角度应用超大kernel的方法,它可以平滑地将kernel扩展到 61×61,并具有更好的性能。基于这个方法,作者提出了Sparse Large Kernel Network(SLaK),这是一种配备 51×51 kernel-size的纯 CNN 架构,其性能可以与最先进的分层 Transformer 和现代 ConvNet 架构(如 ConvNeXt 和 RepLKNet,关于 ImageNet 分类以及典型的下游任务。
1应用超过 31×31 的超大卷积核
作者首先研究了大于 31×31 的极端Kernel-size的性能,并总结了3个主要观察结果。这里作者以 ImageNet-1K 上最近开发的 CNN 架构 ConvNeXt 作为进行这项研究的 benchmark。
作者关注最近使用 Mixup、Cutmix、RandAugment 和 Random Erasing 作为数据增强的作品。随机深度和标签平滑作为正则化应用,具有与 ConvNeXt 中相同的超参数。用 AdamW 训练模型。在本节中,所有模型都针对 120 个 epoch 的长度进行了训练,以仅观察大Kernel-size的缩放趋势。
观察1:现有的技术不能扩展卷积超过31×31
最近,RepLKNet 通过结构重新参数化成功地将卷积扩展到 31×31。作者进一步将Kernel-size增加到 51×51 和 61×61,看看更大的kernel是否能带来更多的收益。按照RepLKNet中的设计,依次将每个阶段的Kernel-size设置为[51,49,47,13]和[61,59,57,13]。
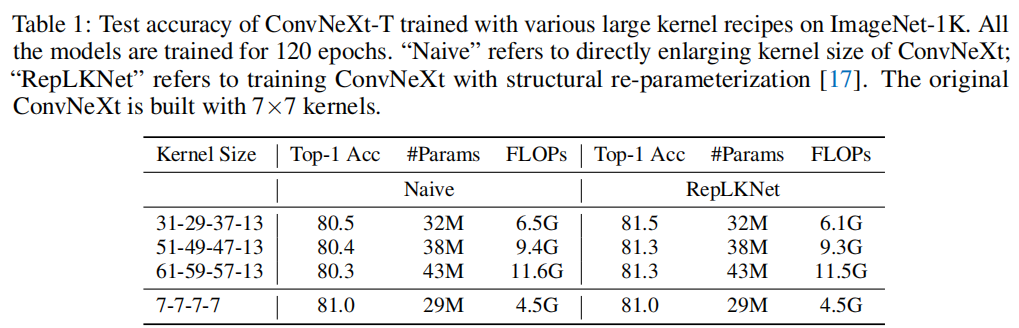
测试精度如表 1 所示。正如预期的那样,将Kernel-size从 7×7 增加到 31×31 会显著降低性能,而 RepLKNet 可以克服这个问题,将精度提高 0.5%。然而,这种趋势不适用于较大的kernel,因为将Kernel-size增加到 51×51 开始损害性能。
一种合理的解释是,虽然感受野可以通过使用非常大的
kernel,如51×51和61×61来扩大感受野,但它可能无法保持某些理想的特性,如局部性。由于标准ResNet和ConvNeXt中的stem cell导致输入图像的4×降采样,具有51×51的极端核已经大致等于典型的224×224ImageNet的全局卷积。因此,这一观察结果是有意义的,因为在ViTs的类似机制中,局部注意力通常优于全局注意力。在此基础上,通过引入局部性来解决这个问题的机会,同时保留了捕获全局关系的能力。
观察2:将一个方形的大kernel分解为2个矩形的parallel kernels,可以将Kernel-size平滑地缩放到 61。
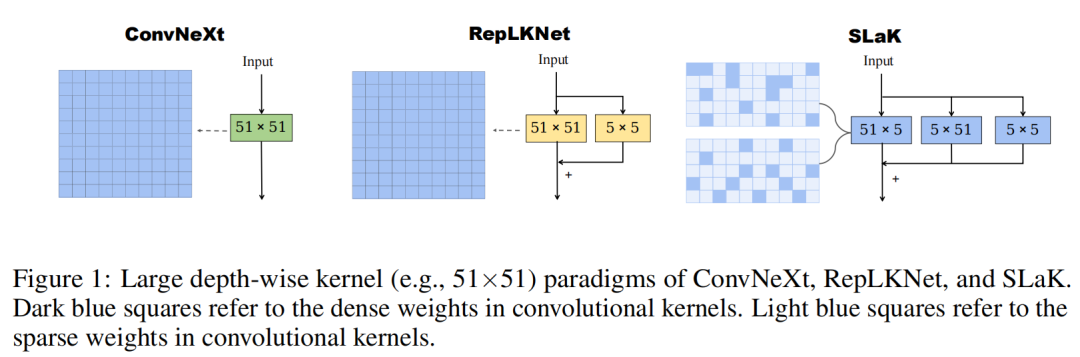
虽然使用中等大小的卷积(例如,31×31)似乎可以直接避免这个问题,但作者就是想看看是否可以通过使用(全局)极端卷积来进一步推动cnn的性能。作者这里使用的方法是用2个平行和矩形卷积的组合来近似大的 M×M kernel,它们的Kernel-size分别为M×N和N×M(其中N<M),如图1所示。在RepLKNet之后,保持一个5×5层与大kernel并行,并在一个批处理范数层之后汇总它们的输出。
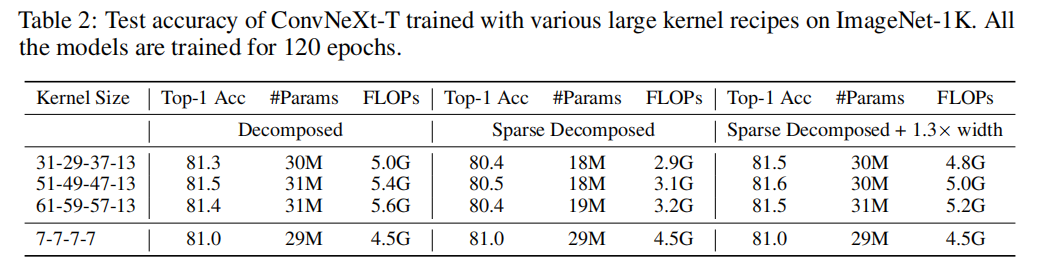
这种分解不仅继承了大kernel捕获远程依赖关系的能力,而且可以提取边缘较短的局部上下文特征。更重要的是,随着深度Kernel-size的增加,现有的大kernel训练技术会受到二次计算和内存开销的影响。
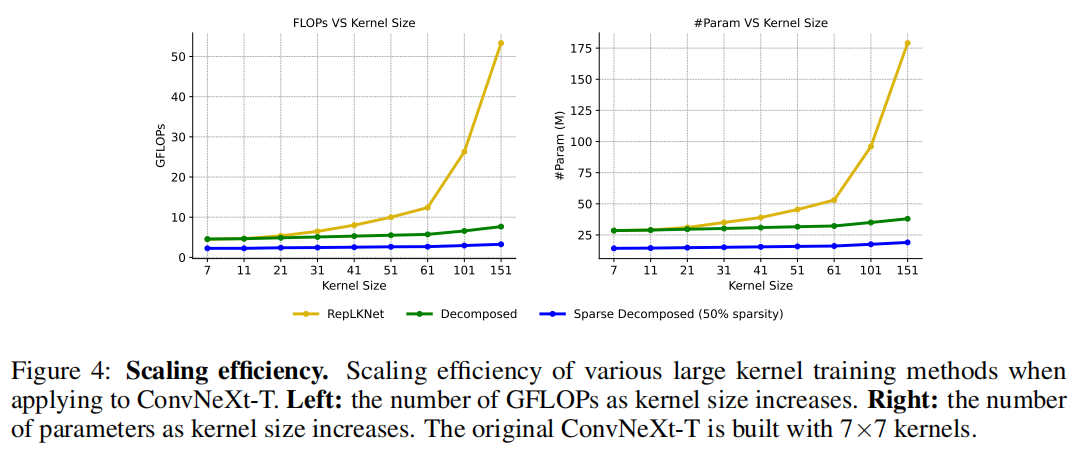
与之形成鲜明对比的是,这种方法的开销随着Kernel-size线性增加(图 4)。N = 5 的kernel分解的性能在表 2 中报告为“分解”组。由于分解减少了 FLOP,与具有中等kernel的结构重新参数化 (RepLKNet) 相比,预计网络会牺牲一些准确性,即 31×31。然而,随着卷积大小增加到全局卷积,它可以惊人地将Kernel-size扩展到 61 并提高性能。
观察3:“use sparse groups, expand more”显著提高了模型的容量
最近提出的 ConvNeXt 重新访问了ResNeXt中引入的原理,该原理将卷积滤波器分成小但更多的组。ConvNeXt没有使用标准的组卷积,而是简单地使用增加宽度的深度卷积来实现“use more groups, expand width”的目标。在本文中,作者试图从另一个替代的角度来扩展这一原则——“use sparse groups, expand more”。
具体来说,首先用稀疏卷积代替密集卷积,其中稀疏核是基于SNIP的分层稀疏比随机构造的。构建完成后,用动态稀疏度训练稀疏模型,其中稀疏权值在训练过程中通过修剪最小幅值的权值,随机增加相同数量的权值进行动态调整。这样做可以动态地适应稀疏权值,从而获得更好的局部特征。
由于kernel在整个训练过程中都是稀疏的,相应的参数计数和训练/推理流只与密集模型成正比。为了评估,以40%的稀疏度稀疏化分解后的kernel,并将其性能报告为“稀疏分解”组。可以在表2的中间一列中观察到,动态稀疏性显著降低了FLOPs超过2.0G,导致了暂时的性能下降。
接下来,作者证明了上述动态稀疏性的高效率可以有效地转移到模型的可扩展性中。动态稀疏性允许能够友好地扩大模型的规模。例如,使用相同的稀疏性(40%),可以将模型宽度扩展1.3×,同时保持参数计数和FLOPs与密集模型大致相同。这带来了显著的性能提高,在极端的51×51 kernel下,性能从81.3%提高到81.6%。令人印象深刻的是,本文方法配备了61×61内核,性能超过了之前的RepLKNet,同时节省了55%的FLOPs。
2Sparse Large Kernel Network - SLaK
到目前为止,已经发现了本文的方法可以成功地将Kernel-size扩展到61,而不需要反向触发性能。它包括2个受稀疏性启发的设计。
在宏观层面上,构建了一个本质稀疏网络,并进一步扩展网络,以提高在保持相似模型规模的同时的网络容量。
在微观层面上,将一个密集的大kernel分解为2个具有动态稀疏性的互补kernel,以提高大kernel的可扩展性。
与传统的训练后剪枝不同,直接从头开始训练的网络,而不涉及任何预训练或微调。在此基础上提出了Sparse Large Kernel Network(SLaK),这是一种纯CNN架构,使用了极端的51×51 kernel。
SLaK 是基于 ConvNeXt 的架构构建的。阶段计算比和干细胞的设计继承自ConvNeXt。每个阶段的块数对于 SLaK-T 为 [3, 3, 9, 3],对于 SLaK-S/B 为 [3, 3, 27, 3]。stem cell只是一个具有 kernel-size为4×4和stride=4的卷积层。作者将 ConvNeXt 阶段的Kernel-size分别增加到 [51, 49, 47, 13],并将每个 M×M kernel替换为 M×5 和 5×M kernel的组合,如图 1 所示。作者发现添加在对输出求和之前,直接在每个分解的kernel之后的 BatchNorm 层是至关重要的。
遵循 “use sparse groups, expand more”的指导方针,进一步稀疏整个网络,将阶段宽度扩大 1.3 倍,最终得到 SLaK-T/S/B。尽管知道通过调整模型宽度和稀疏度之间的权衡来提高 SLaK 的性能有很大的空间,但为了简单起见,将所有模型的宽度保持为 1.3 倍。所有模型的稀疏度设置为 40%。
虽然模型配置了极端的 51×51 kernel,但整体参数计数和 FLOP 并没有增加太多,并且由于RepLKNet提供的出色实现,它在实践中非常有效。
3实验
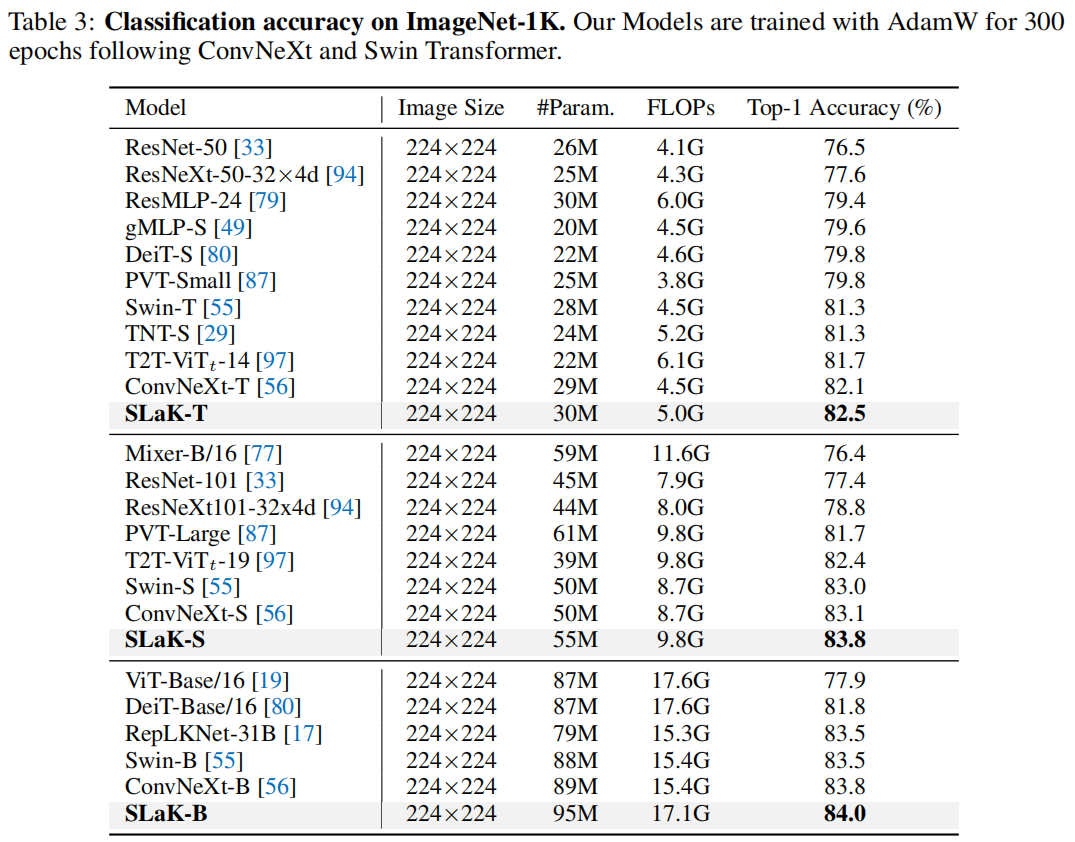
3.1 分类实验
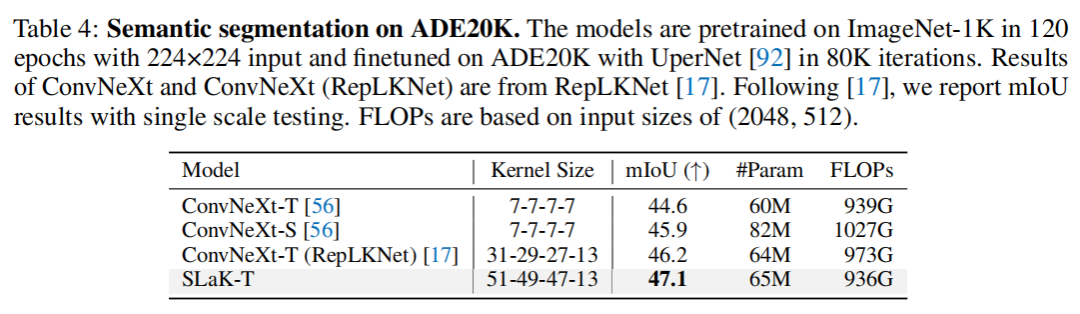
3.2 语义分割
4参考
[1].More ConvNets in the 2020s : Scaling up Kernels Beyond 51 × 51 using Sparsity.
5推荐阅读
YOLOv7官方开源 | Alexey Bochkovskiy站台,精度速度超越所有YOLO,还得是AB
BoT-SORT 丝滑跟踪 | 超越 DeepSORT、StrongSORT++ 和 ByteTrack
Inception 新结构 | 究竟卷积与Transformer如何结合才是最优的?
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
