
你在被窝里刷手机岁月静好,一个“神秘引擎”却在远方和时间赛跑
浅友们好~我是史中,我的日常生活是开撩五湖四海的科技大牛,我会尝试各种姿势,把他们的无边脑洞和温情故事讲给你听。如果你想和我做朋友,不妨加微信(shizhongmax)。
你在被窝里刷手机岁月静好,
一个“神秘引擎”却在远方和时间赛跑
文 | 史中
“时间就是金钱,效率就是生命。”
1981年,一群年轻人用红油漆把这12个字刷在三合板上,立在了刚刚成立不久的深圳特区蛇口工业园。
这句闪着文艺光泽的标语,宣示了一个被人遗忘许久的朴素道理:你干活儿越快越好,你拥有的幸福感就越牢靠。

而后时光如大河涌动,14亿中国人把主要的聪明才智都用在了“如何让生产效率更高”这件事儿上。
于是神舟上天,航母下水,高压线飞架,铁路桥纵横,山河之间,各式机器飞转。我们愣是把自己家干成了世界工厂,从拖鞋袜子造到手机电脑,造不出来算我输。(这不最近造芯片遇到点困难,正在痛定思痛。)
强大的生产力支撑起了每个人具体的幸福生活。
就拿我来说,每天晚上回家,香菇炖鸡、葱烧排骨、红烧牛肉,想泡哪包就泡哪包,还能加个卤蛋。
我想说的是,看得见摸得着的生产力,大家都能理解它的重要意义;可是很多人不了解,就在身边的“平行世界”,我们正在磨炼一种更加神奇的生产力。
它生产出来的东西看不见也摸不着,却对每个人都生死攸关,意义非凡。这就是——大数据计算力。
讲真,即便到了2021年,很多人看到大数据都像韭菜看见联合收割机,两股战战,几欲先走,更别说从生产力的本质角度去解释它了。
大数据技术就像莫高窟一样,每一个洞窟都画满了不同的壁画,值得仔细品味。要是系统地参观,一年都看不完。
今天,中哥就试着做一把导游,用一万字的篇幅带你去参观其中最闪耀的那幅画——“实时计算引擎”。
接下来,你不仅能看到原汁原味的科普,还能了解一个让人骄傲的事实:我们中国的百万程序员已经用了六年时间把“实时计算引擎”这这幅画描绘得光彩照人。在这个顶尖的技术领域,中国正在引领世界。
废话少说,Let's ROCK!
(一)“马屎咖啡馆”
根据中哥一贯的风格,无论是癌症的治疗还是原子弹的制造,咱们都先从幼儿园级别的“1+1=2”开始讲起。
假设,你把“世界这么大,老子去看看”的辞职信甩到了老板脸上,回老家科尔沁草原正中央开了一家咖啡馆,名叫“马屎咖啡”。

创业不易,需要绞尽脑汁吸引顾客。于是你搞了一个促销活动,一杯咖啡积1分,每个顾客只要积够10分,就白送一次骑马体验。

于是你给每个顾客都发了一张小卡片,每买一杯咖啡就盖一个戳,代表一分。顾客们很开心,你的生意一天比一天好。
可是不久你发现,好像哪里不对,怎么有这么多人都满10分了呀。。。你仔细一看,好像有顾客自己买了戳偷偷盖上。

你要哭了,像这样薅羊毛,马都快被骑秃噜皮了。。。

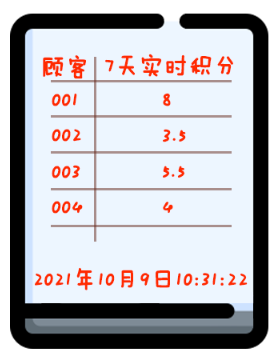
于是,你做了第一个改进:自己做一套“计分表”。
在咖啡店的墙上挂了黑板,写了一张大表,每个格子里都是“顾客的编号”和“Ta 的积分”。每次顾客来买咖啡,你就先跑去墙边给他记一下积分,再跑回来做咖啡。
这么一搞,虽然没人薅羊毛,但累是真累啊。。。

一年后,你的店成了网红,全国顾客都来你这打卡。
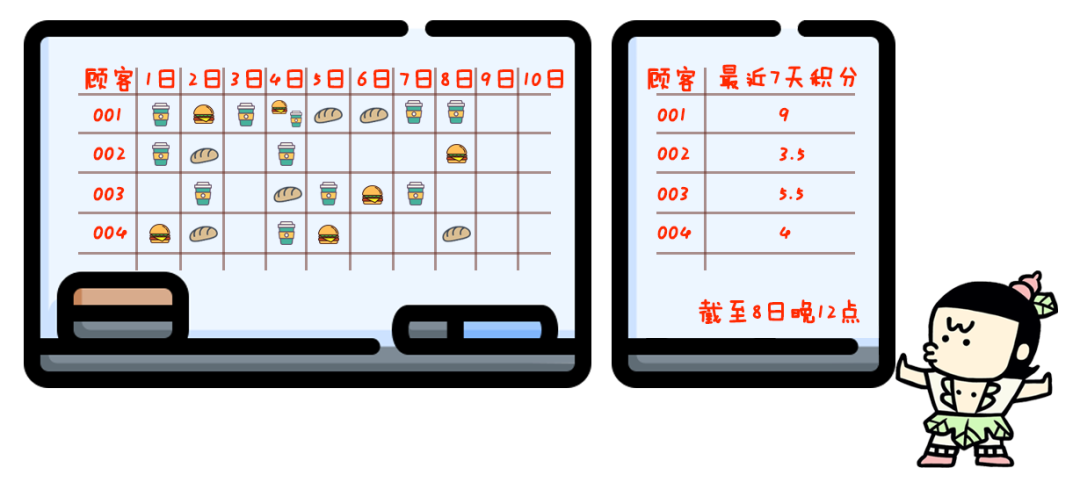
你店里卖的东西种类越来越多:10种咖啡,8种点心,还有6种正餐。
与此同时,你的促销活动也变得更复杂:一份咖啡积1分,一份点心积0.5分,一份正餐积2分。
一周内积够10分才送骑马,七天之前的过期积分就作废。
这么一搞,你现场计分就忙不过来了。。。
于是你做了第二个改进:把“复杂计算”和“正常业务”分离。
每天顾客买了啥你先记在墙上,这个不费多少劲儿。到了晚上打烊,你有空了,再在第二块黑板上仔细把每个顾客当天新增和减掉的积分都算好。
第二天开张,任何一个顾客来,你瞟一眼墙上的结果就可以直接看到 Ta有多少积分了。
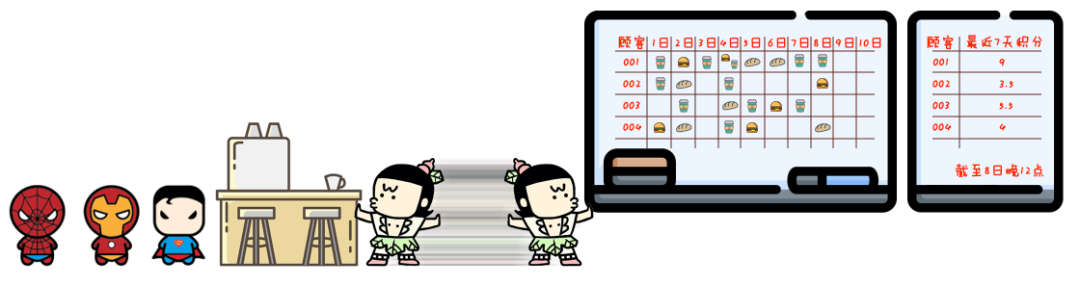
然鹅,按下葫芦浮起瓢。
你这么搞,虽然解决了忙不过来的问题,但也引入了新的问题:有一天,001号顾客来买了一杯咖啡,然后告诉你加上这杯他刚刚积够了10分,要骑马。
你看了看墙上,的确他已经有9分了。可那是昨天晚上的结果。
可今天是9号,他的积分中有2分是2号得到的,恰巧是今天作废的。

那他实际上就没有在一周内完整积够10分,不应该骑马。

这一切的原因都在于计算不及时。
这咋办呢?
于是你做了第三个改进:补充一个实时计算员。
每当遇到这种存在争议的“特殊情况”,你就喊店里那位霍格沃茨大学数学系毕业的哈利伙计帮忙,给这哥们现场计算一下积分。
毕竟是名校毕业,心算五秒就出结果,也不太耽误事儿。
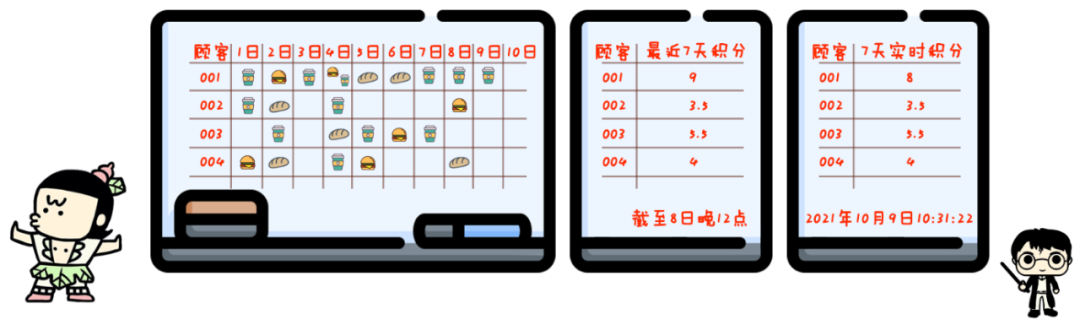
有了这三次改进,你终于搞定了烦人的计算问题,可以把精力继续放在经营上,做出全世界最好的马屎咖啡了~

说到这,我们总结一下。
刚才,其实我们模拟了一个典型的商业场景:
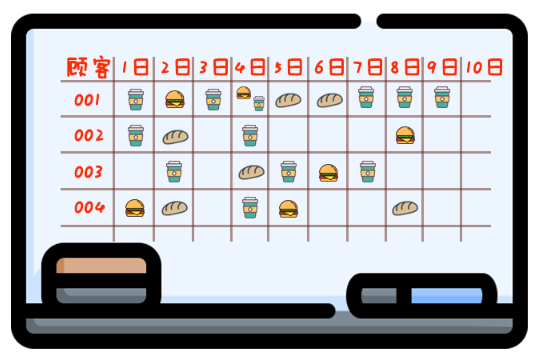
第一次改进,墙上第一块黑板上的大表格就是“数据库”;
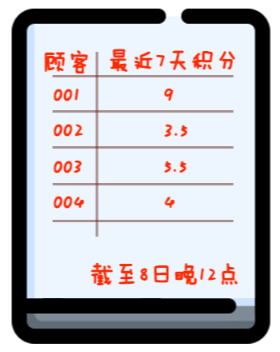
第二次改进,你每天晚上在第二块黑板上那一波算积分的操作就叫“离线计算”;
第三次改进,伙计在第三块黑板上现场给人算积分的操作,就叫做“实时计算”。
可别小看这三个词儿:其实它们每一个都妥妥点亮了一根璀璨的科技树分支,拼起来恨不得就是一部中国基础软件的“追赶史”,未来还可能是一部中国代码界的“超越史”。
“数据库”对精准有变态的要求——同时记录亿万数据,精确到任何一个小数点都不能错。
这项技术长期被美国公司 Oracle 和 IBM 垄断,直到最近几年不服输的中国程序员们研发出了分布式金融级数据库 OceanBase 和 TDSQL,才实现了追平甚至反超。(这两个国之重器中哥都完整记录过,可以去看:《OceanBase,蚂蚁爬上舞台》、《隐秘历史:一场国产金融的核武器试爆》)
“离线计算”对规模有变态的要求——甭管你有1亿用户、5亿用户还是10亿用户,所有数据计算都要在天亮前搞定,如果搞不定,第二天又会涌来新的数据。
完成这么大量的计算,需要先把几万台机器连在一起,进行“大规模分布式计算”。这个技术的底座其实就是很多人都熟悉的“云计算”。(云计算技术中哥写的就更多了,可以参考《阿里云的这群疯子》)
“实时计算”当然就是对速度有变态的要求——顾客才不会管商家计算过程有多难,反正我他喵的等着骑马呢,赶紧给我牵过来!
还记得我们开篇那句话么?没错,时间就是金钱,效率就是生命。
这就是为什么我在举例的时候,特别强调了要用一位“霍格沃茨毕业的伙计”来帮忙算数。在实际应用中,这位“伙计”就是一整套可以最短时间内完成大数据实时计算的系统,也就是我们今天要说的“实时计算引擎”。

最近几年中国经济突飞猛进,各行各业其实都经历了“马屎咖啡馆”的发展路径,早几年先用上了离线计算。
近几年人们越来越发现,离线计算就像三餐,可实时计算却像爱情——三餐不可少,爱情价更高。
给你举几个栗子就明白了:
某家物流公司,每天成千上万件包裹在运输过程中会出现各种难以预料的突发情况:有的比想象中快一点;有的因为交通不畅耽误了时间;有时寄件突然变多,“爆仓”了要临时调配仓库;有时收件人拒收还得原样送回去。。。
各种情况防不胜防,必须要实时同步所有商品的状态,才能为每个包裹规划出最为合理的配送路径。
蔚来汽车,对于几万车主的服务是无微不至的。每位车主享受的道路救援、保险优惠都不尽相同,要保证在 App 上实时能查询、能使用。
而且由于是电动车,汽车开到一定里程,蔚来还要提醒车主对电池这样的关键部件进行保养。
这些服务要想及时准确,就必须把各种数据实时进行汇总计算。
以上这些例子我们等会儿还会详细说,这里中哥先直接给你看三个重要的事实:
1、“实时计算”的潮流势不可挡,在最近三年,全世界都经历了从头部互联网公司到全体互联网公司的扩散,现在正在经历从互联网行业到传统行业的传递过程。
2、“实时计算引擎”曾经有很多技术路线相互竞争。如今,有一种引擎刚刚锁定胜局,承担了各行各业大多数实时计算的任务,这个引擎叫做 Flink。
3、Flink 的技术纵然非常精密,但它本身不属于任何一家公司,是完全开源的,人人都可以像呼吸空气一样自由使用 Flink。而对这项前沿技术掌握最炉火纯青的,正是我们中国的百万程序员。
估计浅友会有点不适应:在各种顶尖科技上,中国一般都是“后进生”,为啥“实时计算引擎”的技术发展方向却被中国程序员牢牢攥在手里呢?
反转从来都不是白白得来的。这背后,其实藏着一条不为人知的精彩故事线。
不久前,我见到了 Flink 的中文社区召集人王峰。让他来回答这些问题,那是再合适不过了。

王峰
(二)一辆好开的车
说起来,王峰有很多身份:首先他是一个撸代码十多年的技术宅大牛,其次他也是实时计算和开源精神的信仰者,如今除了是 Flink 社区召集人,他还是阿里巴巴实时计算团队的负责人。
让王峰说话之前,我们先从头唠叨几句 Flink 的前世今生。
Flink 是一个德语单词,意思是“灵巧、机灵”。而 Flink 的 Logo 是在柏林随处可见的萌货,红松鼠。

左边是 Flink 的 Logo,右边是红松鼠。不能说像,简直是一模一样。
显然,Flink 并不原产自中国。
实际上,Flink 是在2010年由德国柏林工业大学、柏林洪堡大学、波兹坦大学几位痴迷计算的博士后们联合发起的项目,前身叫做 Stratosphere(是平流层的意思)。
开始这帮技术宅只是想做一个数据洞察工具,可是做了几年,这群人被自己的技术惊呆了——左边进数据,右边出结果;左边赶猪进去,右边就有香肠出来。
这玩意儿如此丝滑,隐隐散发出一种能改变世界的味道啊!
于是,2014年他们把项目改名为 Flink,捐献给最负盛名的开源基金会 Apache(就是程序员们天天说的“阿帕奇”),让人人都能免费使用。

联合创始人 Kostas 在介绍 Stratosphere。

2014年10月6日,Flink 在柏林举办了第一次见面会(Meet up)。
难道说这些人是想做慈善吗?也不全是。
创始人团队随即自己成立了一家商业公司,给不愿意(或者顾不上)自己鼓捣 Flink 的公司提供全套技术支持服务,帮他们用好 Flink。
简单来说就是:车白送,但是你得自己开。要是不愿意自己开,我原厂的老师傅可以帮你开,坏了还帮你修,就收个童叟无欺的辛苦费。
如此,一举两得:一方面这么NB的计算引擎可以通过免费开源模式普惠苍生,另一方面创始团队也能有一定收入,给孩子赚点奶粉钱。(实际上这也是如今最为流行的一种开源文化。)
多说一句,他们成立的公司名叫 Data Artisans(数据工匠),和老罗的锤子 Smartisan 是同一个后缀。。。


2015年圣诞节,公司创始团队在涮火锅团建。
故事讲到这儿,我们不妨把时间暂停一下,让柏林这群技术宅们先凝固,咱们把地球转半圈,看看北京的一群技术宅。
2015年,可是王峰人生的至暗时刻。
故事是这样的。
那一年,全中国各大城市都开始出现了“扫码一条街”,随便逛一圈能收一车毛绒玩具。但扫码只是表象,它背后的真相是:智能手机迅速普及,开始成为每个人赖以生存的“器官”。

十亿“器官”连起来能绕地球三圈,你的每一次“下拉刷新”,都会向 App 的后台服务器请求一次最新数据。这些请求就像洪流一样冲击着各大 App 的相关系统。
淘宝自然也是“洪峰”进攻的首要目标。
那阿里巴巴抗洪的水平如何呢?
在当时,阿里巴巴的“离线计算引擎”刚经过几年挣扎,已经基本搞定。
他们搞出的离线引擎叫做 “MaxCompute”。
每天深夜,淘宝上的各家店铺还有剁手党们的数据都可以被 MaxCompute 给整理得明明白白,第二天黎明破晓,各个业务就可以化好淡妆开门迎客了。
但是,“实时计算引擎”就稍显简陋了。
虽然阿里的程序员们也不是吃素的,各个团队都开发了一些实时引擎自己用,但由于没有统一的理论指引,这些引擎的实现技术各不相同,也各有缺点。
就像几辆老爷车,有的加速不好,有的容易抛锚,有的不能适应多种路况。反正凑合开开没问题,但是未来“洪峰”继续加大,能不能顶住确实不好说。
不过,自古以来,险恶的地方才有英雄传说。
那个节骨眼儿,谁要能搞出一个包打天下的“下一代实时计算引擎”,绝对能填补这个硬核科技的空白点。
当时,还在淘宝搜索团队的王峰脑袋一热,决定“揭竿起义”——跟领导商量一下,把原来负责的业务都交出去,自己只带了两个人内部创业,目标就是要搞出一套“下一代实时计算引擎”。
现在回忆起来,这个操作颇有壮士之风,可是当时,王峰差半步就成了“烈士”。。。
“下一代实时计算引擎”到底难在哪呢?
为了说明“下一代”,得先说明“上一代”。
传统的离线计算引擎,是以“批处理”为核心的。批处理,顾名思义,攒够一批数据才能处理。
具体来说,你需要先告诉计算引擎这批计算的量有多大——是1w个数据,还是10w个数据?数据多不怕,但你得先都摆在面前,引擎才知道如何把任务合理分配给不同的服务器。
但是,通过“马屎咖啡”的例子你知道,“A顾客买一杯咖啡”这个事儿这一秒刚发生,他下一秒就需要知道自己的积分变动。也就是说:很多数据是“随来随算”的,引擎不可能提前知道到底有多少数据。
面对这个没有尽头的“流数据”,批处理的逻辑好不好使呢?
可以凑合用。但是要把“流数据”假设成一小批一小批。比如,把1分钟产生的数据看做一批,每分钟算一波。就像公交车一样,先来的数据就在站台上等着,这趟赶不上就赶下趟。
简单来说,就是用“批”的方法算“流”。这就是“上一代实时计算引擎”的基本原理。
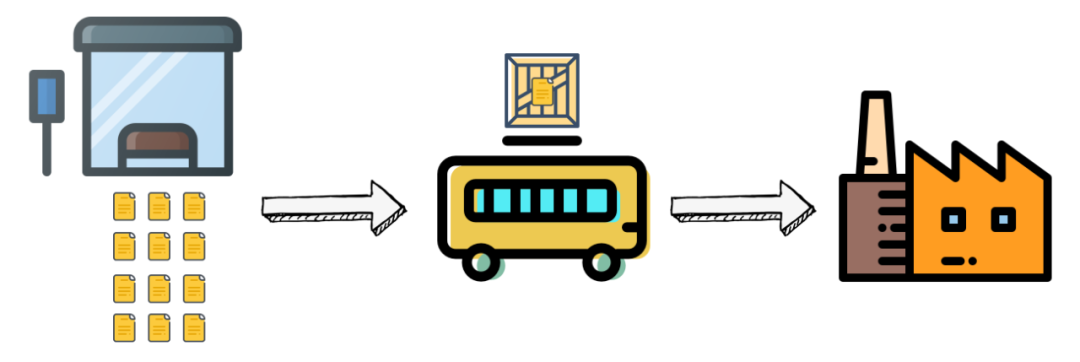
但这么操作并不优雅,而且很多情况下人们等不了1分钟。
王峰想做的,是用“流”算“流”——只要来一个数据,我当时就给计算好。这就相当于一个小轿车,任何数据只要产生出来,就能立刻带走进厂,一丝一毫都不用等。
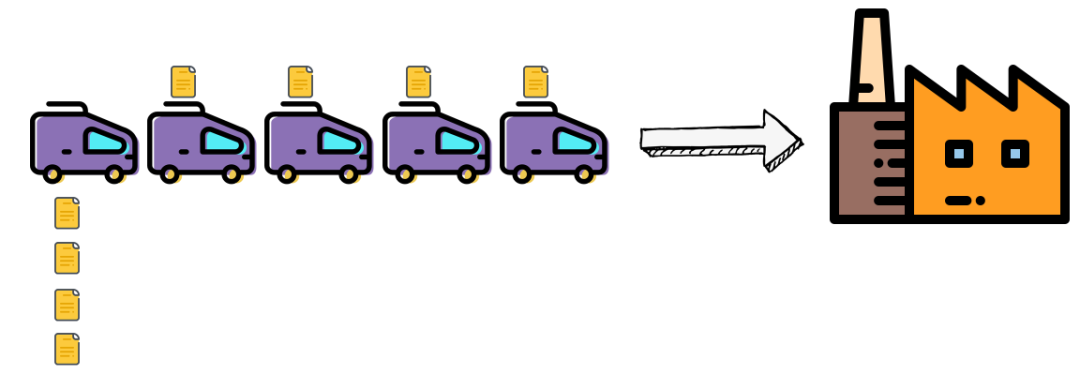
所以,这种下一代实时计算引擎还有一个更贴切的名字:“流式计算引擎”。
2015年,王峰他们卷起衣袖从春节干到夏天,结果,换来一个多么痛的领悟:流式计算引擎的逻辑比想象中复杂太多,真要从头开始十年磨一剑,恐怕黄花菜都要凉了。。。
场面顿时有点尴尬。牛X已经吹出去了,真要干不出来,还有什么脸见江东父老。。。
破釜沉舟眼看就要干成乌江自刎。
就在这个危急时刻,王峰突然看到了在当年 Hadoop 峰会上的一个演讲,题目就叫《有了 Flink,未来还需不需要 Hadoop?》
Hadoop 无人不知,稳坐当时离线计算框架的第一把交椅(阿里自研的 MaxCompute 和它算是同一类东西)。可 Flink 是谁?敢用这种口气和江湖老大说话,不是骗子就是大神。
王峰带着满头问号把 Flink 的开源代码看了一遍,表情逐渐失控:Flink 正是用“流”的方法处理“流数据”,和他的宏大构想不谋而合。
而且,Flink 团队比自己早出发了几年,已经把一整套系统都给写好了。关键在于,代码还是开源的。
这简直是困了有人送枕头,饿了有人送馒头!
那一瞬间,地球两端互不相识的技术宅们,通过共同的计算信仰第一次“连了电”。

2015年6月18日,世界另一端,Flink 举办了美国湾区见面会。
实时计算团队像是发现了宝藏,赶紧向领导汇报,得到认可后,王峰招呼大家紧急转向,放弃之前的半成品,直接基于 Flink 开发阿里巴巴的流式计算引擎。
你可能有个小疑问,Flink 既然都这么先进了,直接用不就行了?还需要开发啥呢?
问题恰恰就出在“太先进”上。
因为王峰的任务是做引擎,不是用引擎。引擎最后是要给业务团队用的。
比如在阿里,用到流式计算引擎的业务就有“店铺服务”、“会员服务”、“商品搜索”、“商品推荐”、“天猫双11大屏”等等很多。
可是你懂的,越是先进的东西,就越难学会怎么用。。。
你给家里的爷爷奶奶一台诺基亚,他们勉强能搞懂,要是给他们 iPhone,他们就蒙了;给你一辆三轮车你可能自己摸索学会怎么骑,可是直接给你一辆汽车,你会开吗?
王峰他们立刻意识到,今后几年要想让 Flink 在阿里巴巴甚至中国生根发芽,最大的挑战恰恰是降低 Flink 的使用难度。
2015年,Flink 的操作难度有点像当年的 DOS,你想干个啥,得先敲一行命令。
实际上 Flink 的操作还比 DOS 复杂得多,要想部署一个计算任务,你得先写一堆 Java 代码描述你想要的操作,不仅费时间,还对编程水平要求极高。
那么,有啥办法可以降低操作难度呢?
这里,就要说到绝大多数程序员都会的神奇语言:SQL。
SQL(Structured Query Language)是一个使用最为广泛的结构化查询语句库。
你可以理解为:它把最常用的操作逻辑都浓缩成了一个个简单的句子。
比如,用 Java 的话你必须说:“请你向西偏北30度走3米,把手抬到1米的高度,握紧盛满液态 H2O 的容器,再走回到原点。”
如果换成 SQL 语句说就是:“你把那个杯子给我拿来。”
会写 Java 的老司机万里挑一,能说 SQL 的技术宅满地都是。要是能用 SQL 语句控制 Flink,那会用 Flink 的人瞬间就多一百倍。
于是,2016年前半年,王峰团队主要就在干一件事:用代码把 Flink 的各种操作和 SQL 语句一一“绑定”,就像把手动挡的汽车改装成了自动挡。

没想到,这个操作成为了引爆 Flink 江湖的最初火花。
带了 SQL 语句的“自动挡 Flink”,被团队起名叫做 Blink。来不及喘气,新生的 Blink 就开始了在阿里内部“攻城略地”的征途。
由于那时候很多业务团队本来已经有了“上一代实时计算引擎”(就是公交车拉乘客那种),Flink 想要替代旧系统,必须得比原来的好十倍,人家才愿意折腾替换。
于是,2016年下半年,Blink 干的最多的事情就是跟别的引擎 PK。“公交车”和“自动挡小轿车”放在一起,你要不要没关系,先上车开一圈儿!
事实证明,有了小轿车(还是自动挡),绝大多数人都会无情抛弃公交车。。。
在各种 PK 中,Blink 都被业务团队相中,名头越来越大。从支持搜索,到支持人工智能推荐,再到2017年双11大屏上实时成交数据都交给 Blink 来算。(这个故事,我在另一篇文章里详细记载过,浅友们可以参考《阿里巴巴果然有预测未来的能力了》)

2016年“双11”
这中间还有一个有趣的小故事。
2016年中,Blink 刚刚开发完成,阿里流式计算团队就把“自动挡 Flink”这个成果投稿到了当年的 Hadoop 峰会。(就是去年那个《有了Flink,谁还用Hadoop?》的那个峰会。。。Hadoop 心中一万只草泥马。。。)

结果,阿里团队的议题成为了那次会议唯二的有关 Flink 的议题,另一个议题,当然是 Flink 创始团队自己投的。
Flink 联合创始人 Kostas 看到议程之后狂喜,我们在中国也没亲戚啊,咋在大洋彼岸突然冒出来一个免费帮我们吹牛的啊。(因为使用开源项目并不用通知创始团队,所以他们并不知道阿里已经在用 Flink。)
于是,Kostas 赶紧联系了阿里巴巴流式计算团队,了解清楚来龙去脉之后,电话两边相见恨晚,隔空互道一声:“同志,你辛苦了!”。
当年8月,另一位创始人,Flink 的技术灵魂 Stephan 还专门飞到杭州,给中国的战友们做了一次演讲,还和这群布道者们一起工作了好几天。

2016年7月,Stephan 在推上发了一张图,总结了使用 Flink 的大公司,阿里巴巴应该是唯一一家中国公司。
故事讲到这,Flink 在中国的推动者还只有阿里巴巴这群人。不过,这个局面不会维持太久。历史的转折往往如大坝裂缝,一旦冲开口子,很快就会白浪滔天。。。
(三)吃螃蟹的“司机们”
2017年,字节跳动的同学有点烦。
彼时,字节已经有了一个叫 JStorm 的引擎。(这个引擎从原理上来讲也属于流式计算引擎。)
本来 JStorm 也挺能打,但这一年,今日头条迅速火爆,而且这家伙身后还有个叫抖音的二弟,用户量发展迅猛,眼看有超越大哥的潜力。
用户量越多,数据量就越大,JStorm 系统用起来问题就越来越多,到后来,光维护这套系统都让团队累得半死。。。
可偏偏实时引擎对于字节跳动来说非常非常非常重要。
就拿抖音来说,每一秒钟都有无数用户在进行“点赞、评论、收藏、转发”等等动作。
这些动作被 Flink 迅速整理成标准格式,马不停蹄地送进人工智能引擎,人工智能引擎拿到热乎的数据也会赶紧学习,生成适合每个用户的模型,以实现用户体验的优化。
你也看出来了,整个过程必须行云流水,一秒都不能耽误。
要是计算引擎罢工十分钟,那就相当于全部抖音用户这10分钟内的数据都没被整理出来,用户模型没办法与时俱进,就只好冻结在10分钟以前的状态,用户体验会越来越不佳。
当时,JStorm 三天两头闹罢工。一有风吹草动,头条、抖音就排着队来吐槽。
流式计算引擎团队忍无可忍,决定掀起一场“引擎革命”。
如你所料,他们最终选择了性能更强大,维护更简单的 Flink。
同样是流式引擎,为啥 Flink 维护起来就比 JStorm 容易呢?说到这里,正好我把 Flink 计算引擎简单拆开一下,给你看看里面的结构。
你可以把 Flink 想象成一个工厂,里边有两个重要的角色:“车间主任”和“工人”。
用最简单的例子来说,他们是这样配合的:
1、客户把需求告诉车间主任,例如我要把A数据通过B函数算出一个结果C。

2、车间主任制定一套详细的“计算计划”,然后把任务切割成每个工人恰好能算得过来的小份。

3、工人们收到一份一份的计算任务,然后埋头计算,算好了就交回给车间主任。
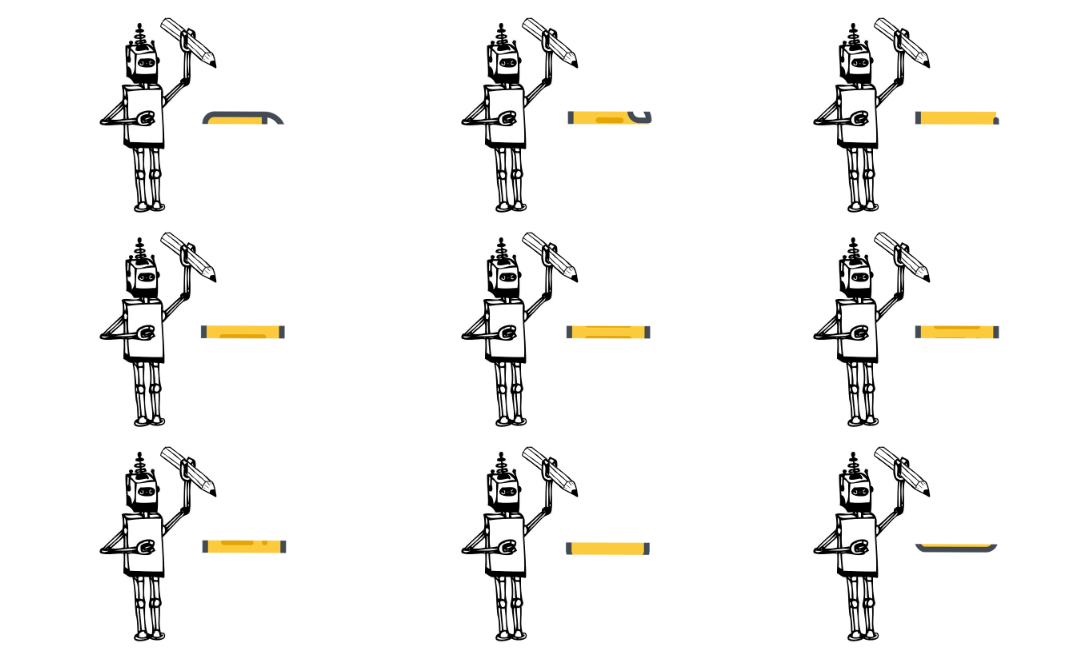
4、就这样,车间主任不断分发任务,汇总结果。

5、拿到最终结果C,车间主任就会交还给客户。

别看原理挺简单,但这其中涉及一个重要且有趣的问题,那就是“资源隔离”。
葫芦娃干活当然需要工具,在计算场景,这个工具就是内存、硬盘、CPU 之类的资源。
在 JStorm 的系统里,没有设计资源隔离的机制,工人们需要什么工具就自己取。
这样的话,如果计算任务不繁重,大家还能相安无事,可是一旦计算任务大量涌来,工人们就会开始抢工具,结果活还没干,光抢工具就已经头破血流了。
这个现象,表现在宏观世界就是——死机。

JStorm 就会经常出现这样的问题。一旦死机,不仅要花时间重启系统,前面算了一半儿的数还白算了,事儿就耽误了。。。
Flink 的厉害之处恰恰在于:设计的时候,就专门考虑且规避了“工人火并”这种情况。
Flink 可以直接跑在 Yarn 或者 K8s 这样的资源调度系统上,这些系统最擅长的工作就是做隔离。
你可以想象,每个工人有一个工作台,他面前的工作台上就摆了这么多工具,不够用也没办法去抢别人的。这样一来,工作就井然有序多了。纵使任务繁重,出现死机的概率也大大降低。
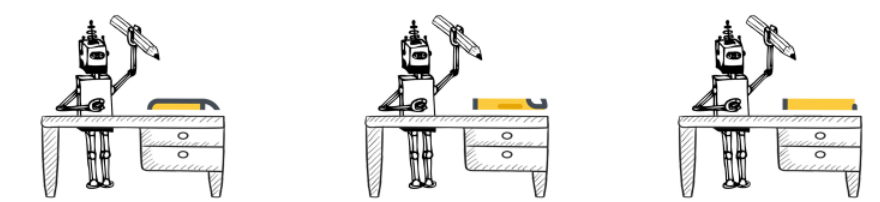
把实时计算引擎换成 Flink 之后,字节跳动掀起了一场持续一年的“大迁徙”——把所有业务的实时计算工作从 JStorm 迁移到 Flink 上。
如今,抖音已经有了超过6亿日活用户。而为了服务这些用户,字节跳动流式计算团队维护了一个世界上最大的 Flink 流式任务,几百台最高配置的服务器熊熊燃烧,时刻为抖音输送数据弹药。
字节跳动只是头部互联网公司的一个代表,就在那段时间前后,美团、京东、百度等等头部互联网公司都先后开始吃 Flink 这个螃蟹,并且越吃越香。
所有吃螃蟹的人中,有一家公司很特别,那就是蔚来。
2019年,蔚来的关键词就是——“惨”。这一年,他们的股价一度跌到1块多美金,简直就是在鬼门关上疯狂试探,创始人李斌被评为“年度最惨的人”。。。
而就在这样的生死关头,蔚来的老师傅们拼死交付了20565辆车,不仅后来股价一飞冲天,还让围成一圈准备看笑话的人们大失所望。
当然,以上是大家耳熟能详的往事。
很多人不知道的是,正是在爬雪山过草地的2019年,蔚来却大举投入部署了 Flink 引擎。
蔚来汽车大数据团队负责人唐怀东,就是这次 Flink 的操刀手。

唐怀东
唐怀东告诉我,蔚来的一贯操作,是把用户当成最好的朋友。
既然是好朋友,那当然要时刻响应他们的需求。
但问题是,车主跟蔚来打交道,会通过很多不同途径——比如买车,是和线下门店打交道;比如保养,是和售后部门打交道;比如上保险,是和三方保险公司打交道;比如投诉,又是和客诉部门打交道;比如在蔚来论坛发帖,是和蔚来 App 打交道。
对于车主来说,我只认一个蔚来。
比如我刚刚打投诉电话反映了一个问题,过一会儿再给售后服务打电话,客服小姐姐如果说:“对不起,售后和客诉两个部门之间的信息还没来得及同步”,那我肯定会原地爆炸。。。我他喵的管你有多少部门?只要我反馈了某个信息,就默认你们所有人部门的都要知道。
这个各部门信息实时同步的重任应该交给谁呢?没错,Flink。
唐怀东和同事们基于Flink实现并整合里了一批能够实时反映用户各个触点的聚合信息。从此,客服小姐姐就再也不用说“对不起”了。
故事讲到这里,有些浅友可能会皱皱眉头:“你别吹了,说得这么热闹,Flink 不还是个洋玩意儿么?你中国人用得再好,也没掌握核心科技啊!要是有一天,Flink 社区不开源了,或者不让你用了,那不得傻眼么?”
这个担心确实有道理,但不够准确。我们不妨接着往下看。
(四)“关键先生”
2018年底到2019年初,三个重磅消息接连袭来。
1)阿里巴巴把 Flink 一年一度的官方大会 Flink Forward 引入了中国,也就是 Flink Forward Asia。

Flink Forward 2018 北京
2)阿里巴巴把 Blink 捐献给 Flink 社区,从此人人都可以开上“自动驾驶汽车”。
Stephan 向全体社区宣布 Blink 开源的邮件
3)阿里巴巴把 Flink 创始团队成立的商业公司 Data Artisans 给收购了。。。
Kostas 当时在推上的宣布。
这意味着,Flink 的创始团队进入了一家中国公司,两个半球的人再也不是惺惺相惜的“精神伴侣”,而是一个屋檐下过日子的家人了。
你可能有个小疑问:Flink 既然这么好,为啥 Kostas 他们还要把公司卖掉呢?
刚才我举的那些 Flink 应用的例子都发生在中国企业身上。其实不瞒你说,那几年 Flink 的突飞猛进,也主要就发生在中国。
原因也很简单:中国人太多了——能让 Flink 尽情发挥的需要同时计算如此众多数据的战场,只存在于中国。
你可能还会质疑:不对啊,很多美国 App,那用户可是遍及全球的,加起来不比中国人多么?
要知道,很多国家对于用户数据都有一根红线——数据不能出国界。美国人的数据只能在美国处理,欧盟的数据只能在欧洲处理。单一国境内大数据最多的是谁,不言自明。
结论很明确:在相当长的一个阶段内,中国都会是 Flink 最大的使用者,也是 Flink 生态商业服务的最大市场。
说到这里,我必须得介绍一下影响开源社区的重要角色:Committer。
Committer 是指一个开源项目的核心贡献者。这个单词字面翻译是:承诺者。这个意思其实非常准确,一旦你做出对社区的承诺,你就要保证风雨无阻地为它做贡献,不论贫穷还是富有,疾病还是健康。
Committer 有两个主要职能:1)自己直接写代码为项目添砖加瓦;2)社区成员提交代码给 Committer,Committer 负责审核并最终提交代码。
所以,一个开源技术诞生在哪个国家并不重要,Commiter 们才是真正影响一个社区技术走向的“关键先生”(或女士)。
当然,要成为 Committer 并不容易,就像加入某个神秘组织,你必须先是积极分子,然后得到某位内部长老的举荐,再由全部长老评审,你才有机会被吸纳。
自从 Flink 在中国生根发芽,不断有中国程序员成为 Flink 的 Committer。
比如,研发 Blink 的主力工程师伍翀,凭着对 Flink 的巨大贡献,在2017年被提名为 Flink 社区的 Committer,还在2019年成为了 PMC(项目管理委员会成员)。
还有字节跳动流式引擎的工程师李本超,也因为在 SQL 方向上的努力进一步降低了 Flink 的使用门槛,在2020年成为了 Committer。

伍翀(图片截取自二叉树的采访)

这是一封伍翀作为 PMC 宣布李本超成为 Committer 的邮件。
中国的 Committer,当然就会更理解中国的具体场景,从而使得 Flink 有机会添加更多解决中国公司实际困难的技术特性。
这一点,对于非互联网行业的千万中国企业至关重要。
一家头部物流公司A就就是其中之一。
A公司的大数据负责人告诉我,早在2017年,他们就开始用流式引擎来支持所有快递小哥的送货工作——一个小哥刚送了一个件,他的总任务完成进度如何,今天可以赚多少钱,就能在手机上实时查询到了。
可是在他们心里,却一直有一个愿望:用流式引擎来支持“路由推演”。
啥叫路由推演呢?
就是我们在文章最开始介绍的,把所有正在运输途中的快件实时信息汇总,然后推演出每个快件的最佳配送路径。这是物流的核心大脑要做的事情。
2017年的时候,A公司利用离线引擎,可以做到每个小时进行一次路由推演。
你可以想象面前有一幅巨大的地图,上面显示着每个快件的位置和路线。每隔1小时,大屏幕会刷新一次,根据最新数据给出最优线路。
可是,一小时的时间里会发生很多事情,间隔这么久算一次可能会错过重要时机——卡车出发了就不能掉头,飞机起飞了更不能再回机场。
如果能用流式引擎做这件事儿,那就能实现每秒,甚至每毫秒推演一次路由,运输的精准度会大大提高,也会减少很多浪费。
2018年,A公司的团队用 JStorm 实现了实时路由推演,可是和字节跳动一样,他们也发现了 JStorm 在大规模计算的时候容易发生诸多问题,于是在2020年,他们把核心的路由推演系统搬迁到了 Flink,大功终于告成。
现在的A公司,燃烧的大脑每天会进行几十亿次的计算,核心路由推演每时每刻都在刷新。不仅如此,所有人员排班,智能报表,都会通过 Flink 集群完成。
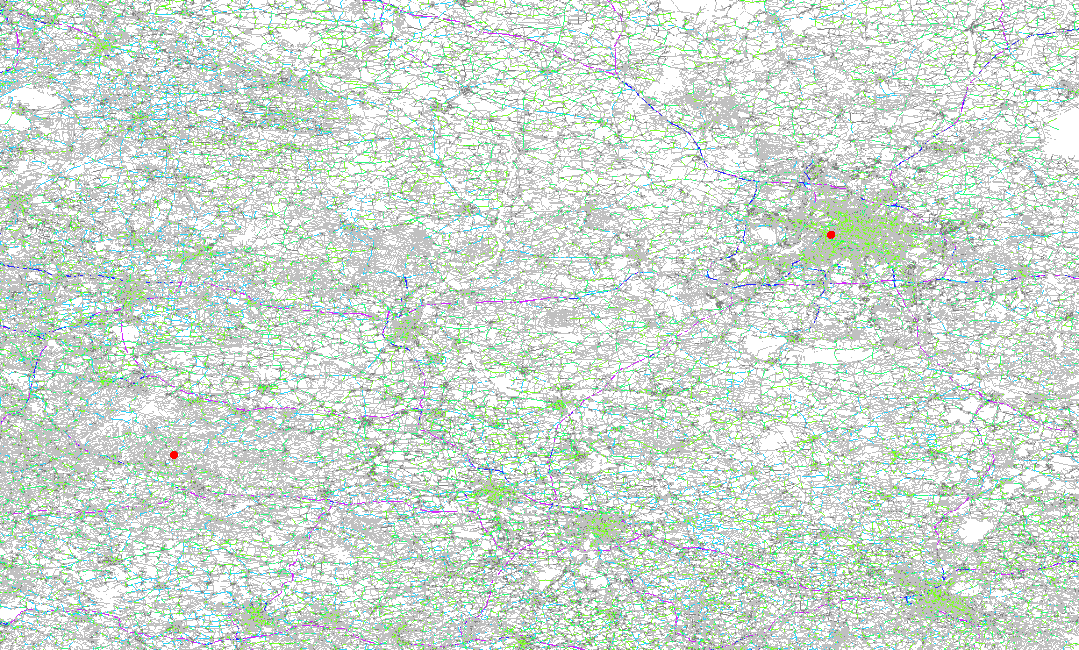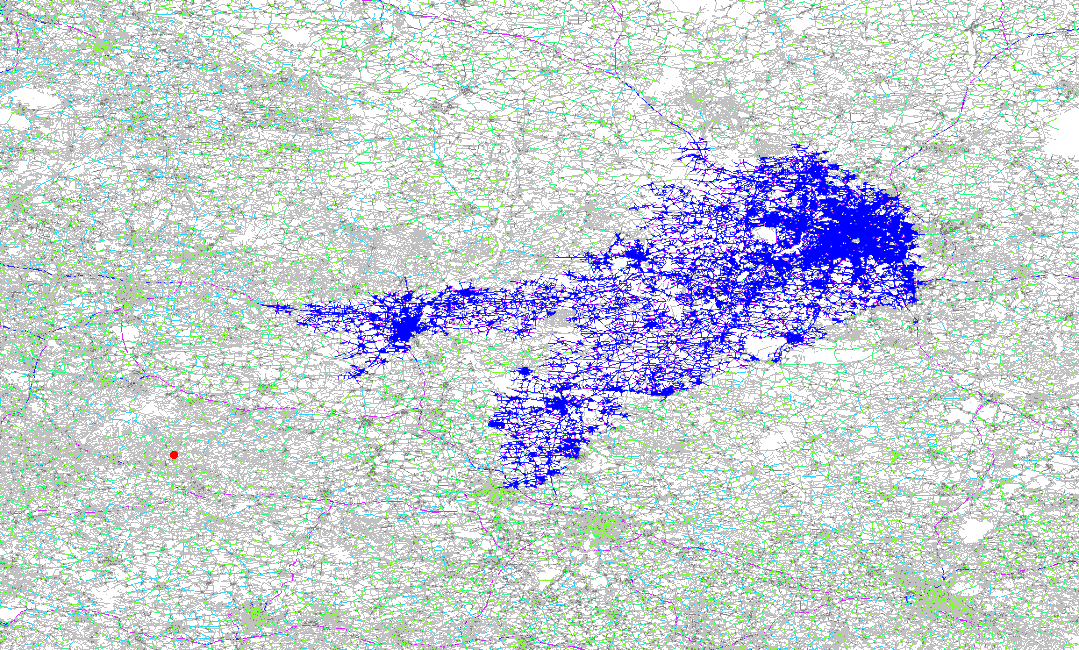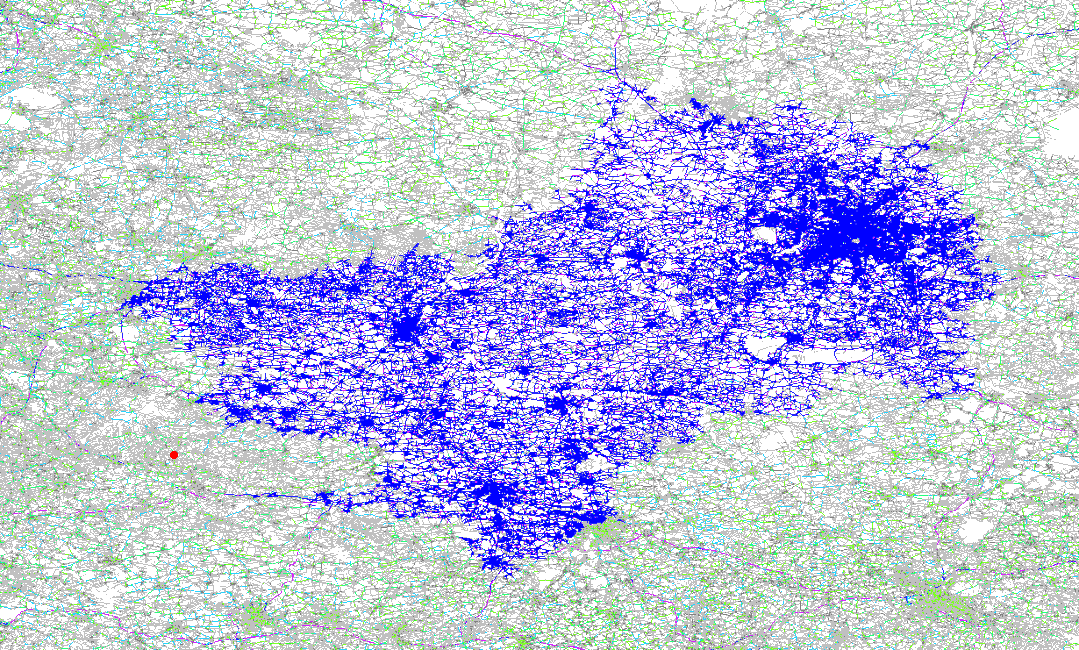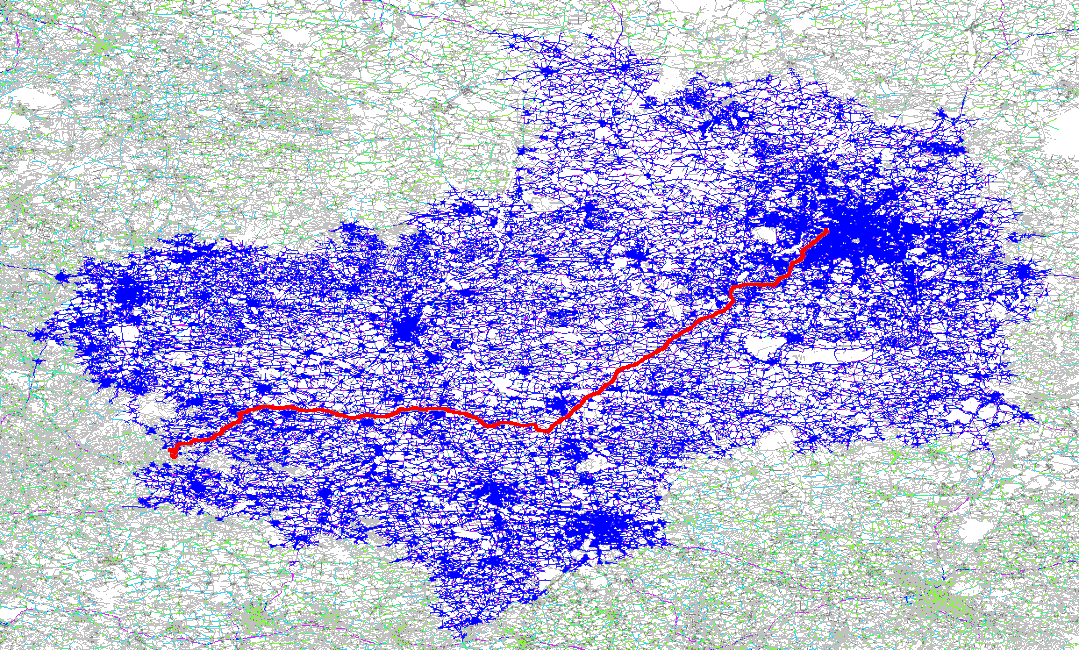
这张图模拟了两点间路由计算的计算过程,你可以感受一下其中计算的复杂度。
而最让大数据团队觉得舒心的,是各个部门的同事都可以用 SQL 这个“自动挡”驾驶 Flink。
比如,广东有一位同事想知道深圳市今天晚上五点到六点之间送的快件比昨天多了多少,只要给引擎输入一行命令,结果就跳出来。
整个过程根本不需要技术团队的帮助。
不用技术部门辅助而直接操作,会让业务团队越用越爱用,越用越多。
别忘了,所有简单易用的功能都不是从天而降的,这背后暗藏着中国 Committer 和代码贡献者几年来的不懈努力。
随着 Flink 越来越好用,中国有很多能源、制造业、媒体、金融企业也开始使用 Flink。
例如国家电网用 Flink 进行电压合格率分析、央视用 Flink 分析春晚的实时收视率、农行用 Flink 做实时风险监控,小鹏汽车把 Filnk 用在智能生产线上实时指导生产。
星星之火,正在燎原。
各行各业都在集合每一个细节的数据,才有可能认识现在;只有认识现在,才有可能预测未来。
Flink 开始承担国计民生重要职责,核心开发者们反而压力山大。。。
王峰告诉我,他们可不敢闲着,最近一年,团队正使出吃奶得劲儿让大数据计算引擎的“驾驶”难度进一步降低。

(五)大统一理论
流批一体,就是最近两年 Flink 社区一直在挑战的目标。
你还记得我们的“马屎咖啡”吗?我们先是建立了一个“离线计算引擎”,后来发现“离线引擎”不够用,才建立了“实时计算引擎”。
绝大多数企业的发展路径也是这样的。
这个历史原因,造就了有趣的局面:很多公司都有两套计算系统:一个离线,一个实时。
可你仔细想想,两个引擎其实是有点问题的。同一套业务逻辑,用户需要用两套引擎开发两遍,不仅管理很不方便,线上线下数据一致性也不好保证。
如果能把两个活儿用一个引擎搞定,岂不是既高效又准确?
没错,这就是“流批一体”要实现的宏伟目标。
你把数据流想象成水龙头里流出来的水,原来我们流出一滴就做一次计算,现在我们拿一个桶,在下面接满一桶再拿给 Flink 计算。
再打个比方,就像你追剧,原来出一集你看一集,现在你攒十集一起看,不也行吗?
王峰说。
对于阿里巴巴来说,流批一体的好处还不仅仅是减少一个引擎这么简单。它还能解决一个大痛点。
2020年“618大促”的时候,出现了一个尴尬的现象:
用同样的数据计算同一个指标,结果离线引擎和 Flink 给出了两个略有差异的答案。。。
究其原因,毕竟两个系统是两个团队分别做的,在数据口径和计算逻辑上会有微小的差异。这就像墙上挂了两个钟表,你都不知道该信谁了。。。

于是,2020年“618”一过,阿里巴巴就下定决心,要在当年的“双11”上把离线和实时的营销数据分析报表都统一用 flink 计算。
计算团队没日没夜忙活了半年,终于如约搞定,所有数据统一走 Flink 的口径计算。
墙上只剩一块表。
不过,王峰告诉我,虽然阿里巴巴已经实现了流批一体,但这仍然是建立在阿里老司机们强大的开车技术之上的。要把流批自由转换的门槛降低,还是老方法——把它做成“自动挡”。
但流批一体的自动挡,比纯流式计算的难度“更上一层楼”。

比如,批计算有一个语义是“停止”,但流计算就没有“停止”,你就必须用一套简洁易懂的 SQL 语言逻辑实现又能描述批的行为又能描述流的行为。
再比如,流式引擎一般从 Kafka 这样的中间件里读取数据,但批式引擎会从落盘之后的永久存储里读数据。面对两种数据源,Flink 要能用一套方式对它们进行操作。
这些都要求设计者对计算引擎的逻辑有非常深刻的理解。
王峰说。
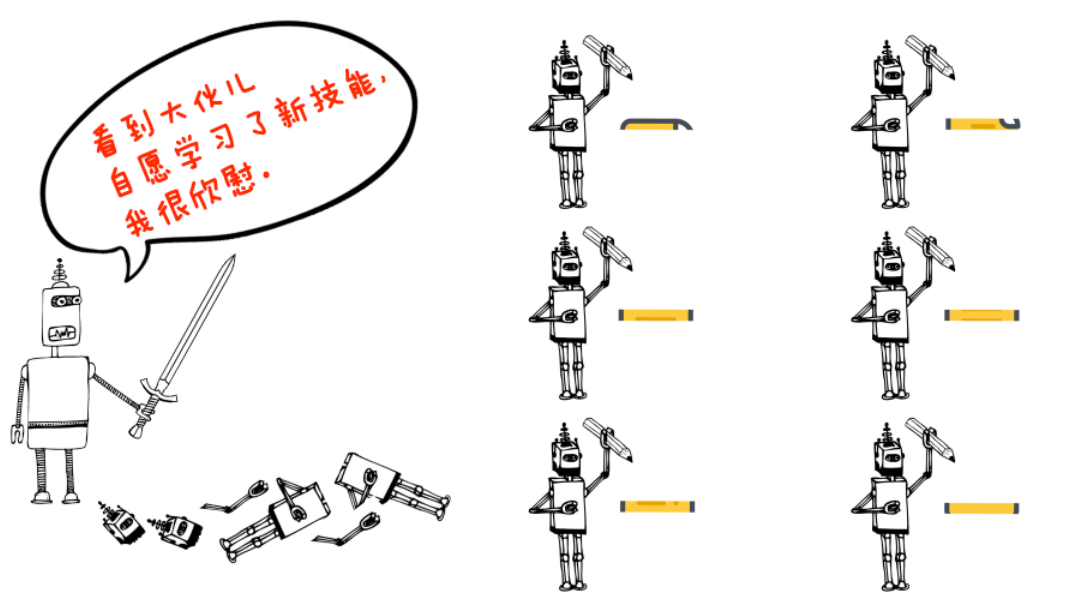
而且王峰还觉得,仅仅能支持流批一体还不够,让用户来手动选择流还是批,很多时候本身就是不优雅的。
引擎应该有能力自动实现“流批转换”,接入一堆数据,要先按照批的模式跑,跑到最新的那一条数据之后,就切换成流继续跑。
就像下面这张图。
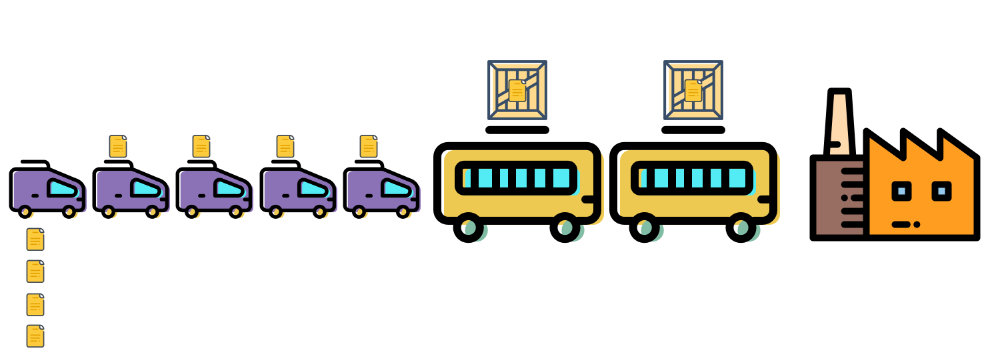
这就有点像“变形金刚”,乘客多的时候就变成能装的大巴车,乘客少了就变成速度快的小轿车。而什么时候要变,那得变形金刚自己决定。
“就像苹果手机,某个功能你用起来觉得很智能,背后一定有工程师们做过无数复杂的打磨。”王峰说。
为了降低中国程序员研究 Flink 的语言障碍,中国社区专门把手册翻译成了中文,2019年还注册了 Flink 中文社区公众号,各大公司的研究员都会投稿。
他们还搞了 Flink 中文网站,让各家使用 Flink 的企业交流经验。
在网站上我看到了各种大公司的名字。
除此之外,还定期举办线下线上的“Meet up”。
2019年一场最大的 Meet up 居然来了2000人,疫情之后改成线上活动,最多有4w人在线。
其实,Flink 社区里很多人都是利用业余时间义务工作的。
对于很多程序员来说,干活绝不仅仅是为了养家糊口。能够遇到志同道合的人,一起创造一个更完美的世界,这才是真正的激情所在。
王峰念叨这些的时候如数家珍。

(六)世界并未渐行渐远
现在 Flink 的核心代码中,欧洲团队和中国团队的贡献是“五五开”。
欧洲的创始团队主要负责收集欧洲和美国的需求,中国的负责负责收集亚洲的需求。
两边的团队每周都会开会,从自己遇到的实际情况出发来研究 Flink 下一步的技术演进方向。
“难道你们就没有因为文化不同发生冲突的时候吗?”我摆出不信脸。
“毕竟两个团队相隔千里,还得用英语线上交流,真想打起来也不容易。。。
再说,虽然我们中国的场景确实是最丰富的,但这也不代表他们有的场景你都有,而且欧洲团队天然对欧美文化和市场更了解。这么几年磨合下来,我们最大的心法就是“相互尊重,相互认可”。
尊重是一种态度,认可是一种能力。”
王峰说得很坦诚。

我突然理解:在技术面前,其实未曾有“舶来品”的概念。
佛学虽是舶来品,但中国人在其上又生蓬莱:
白马古刹,玄奘西行,丝路敦煌,鉴真东渡,华严净土,德音远播。
《三国演义》关羽他乡遇故,普净和尚助他过关斩将;《水浒传》智真长老三偈盖全篇;《红楼梦》宝玉出家青埂还石;《西游记》本身就是漫漫西途求取真经。四大名著里的佛教情节可都是 Made in China。
由此,充斥在每个人眼里的“全球化退潮”也许并不是全部真相,在某些更深层的肌理中,无数证据表明世界并未渐行渐远。
这些证据更值得成为我们的决策参考。
2020年4月,相关文件里,在传统的四大生产要素“土地”、“人力”、“技术”、“资本”之后,第一次添加了第五大生产要素,这就是“数据”。
土地之上如果没有工厂,那就永远是杂草丛生的荒地;资本之上如果没有金融,它就永远是一般等价物;而数据之上没有计算引擎,隐藏在其中的知识就无法浮现。
但数据会伤人吗?
如果非要我说,知识是利刃枪炮,当然可以用来伤人,利用数据霸权伤人的事情也在各个角落发生,这些应该也正在被讨论。
但这却不应是人们退回到石器时代的理由。
古往今来,对抗魔法的只有魔法,对抗技术的只有技术。而归根到底,披甲的先知才有权善良,而手无寸铁的庸人别无选择。
怪兽从不会因为奥特曼的神隐而退场,而世上总会有人继续相信光。
在和很多数据“操刀手”们聊天时,我发现他们中的大多数和你我并无区别,他们像爱惜眼睛一那爱惜隐私,也像万千程序员一样简单善良。
于是我得出了一个有趣的结论:单打独斗的科学怪人非常危险,但程序员们作为一个整体反而更加可靠。
而且,掌握大数据生产力的人越多,这个群体越值得被信赖。
由此来看,我们正走向一个并不太坏的未来。


时间就是金钱
效率就是生命
再自我介绍一下吧。我叫史中,是一个倾心故事的科技记者。我的日常是和各路大神聊天。如果想和我做朋友,可以搜索微信:shizhongmax。
哦对了,如果喜欢文章,请别吝惜你的“在看”或“分享”。让有趣的灵魂有机会相遇,会是一件很美好的事情。
Thx with  in Beijing
in Beijing
评论