
golang:快来抓住让我内存泄漏的“真凶”!
导语 | 有句话说得好:“golang10次内存泄漏,8次goroutine泄漏,1次真正内存泄漏”,那还有一次是什么呢?别急,下面就结合本次线上遇到的问题来讲一讲golang的内存泄漏和分析解决办法。
一、起——内存泄漏表现
在平常开发中golang的gc已经帮我们解决了很多问题了,甚至逐渐已经忘了有gc这种操作。但是在近期线上的一个trpc-go项目的表现实在让人匪夷所思,先让我们看看该患者的症状:
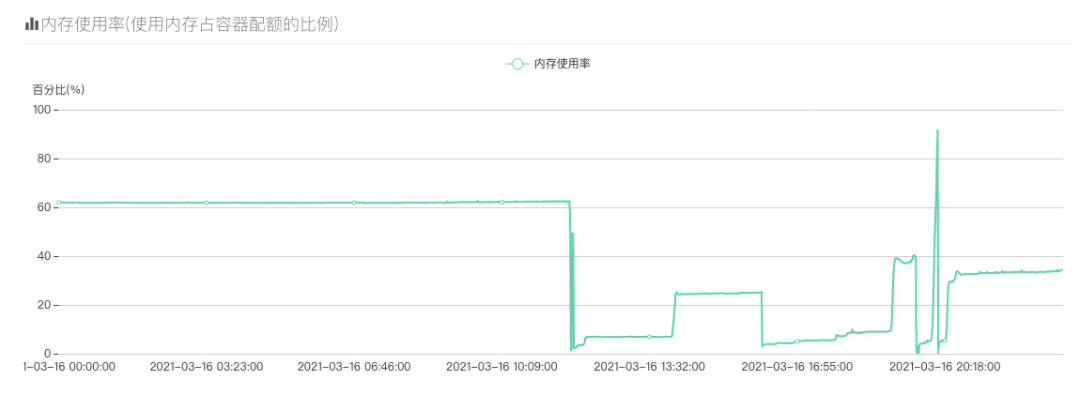
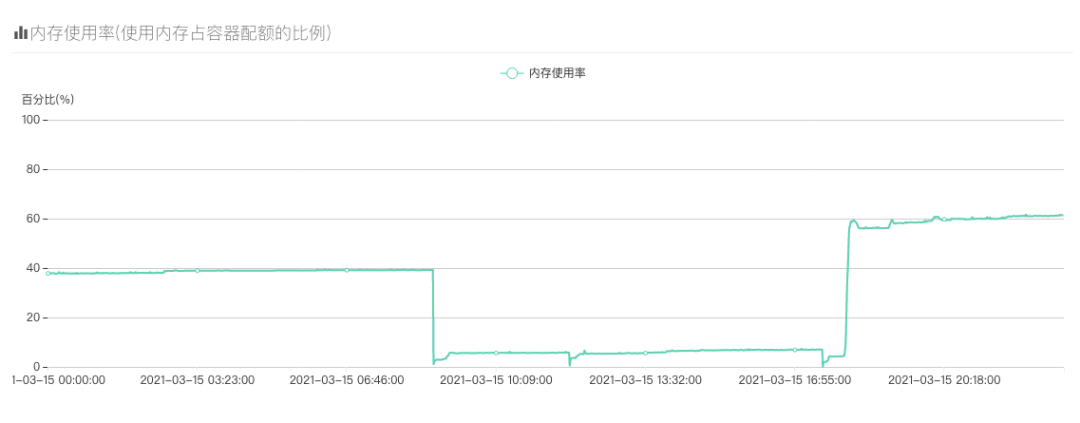
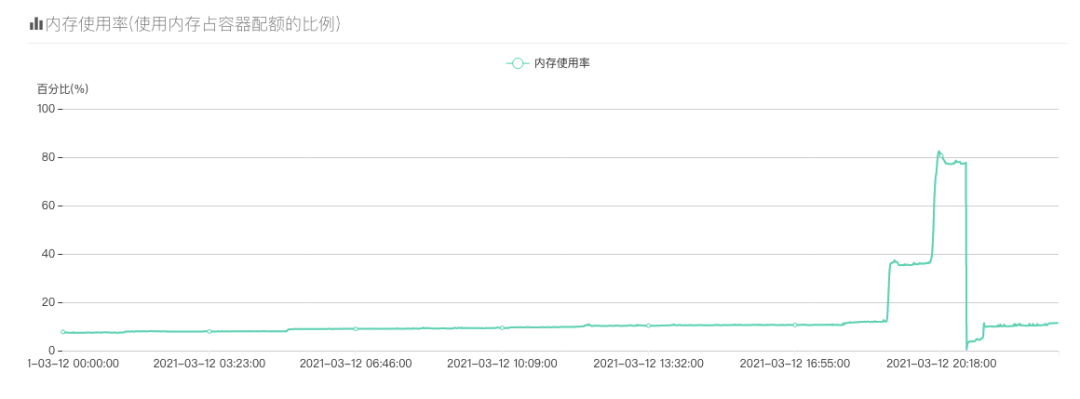
也是那么巧,每天晚上八点左右,服务的内存就开始暴涨,曲线骤降的地方都是手动重启服务才降下来的,内存只要上去了就不会再降了,有时候内存激增直接打爆了内存触发了OOM,有的同学可能就会说了“啊,你容器的内存是不是不够啊,开大一点不就好了?”,容器已经开到20G内存了…我们再用top看看服务内存情况:

让我忍不住直呼好家伙,服务进程使用的常驻内存RES居然有6G+,这明显没把我golang的gc放在眼里,该项目也没用本地缓存之类的,这样的内存占用明显不合理,没办法只好祭出我们golang内存分析利器:pprof。
二、承——用pprof分析
(一)内部pprof
相信很多同学都已经用过pprof了,那我们就直入主题,怎么快速地用pprof分析golang的内存泄漏。
首先说一下内部如何使用pprof,如果123平台的服务的话,默认是开启了admin服务的,我们可以直接在对应容器的容器配置里看到ip和admin服务对应的端口。
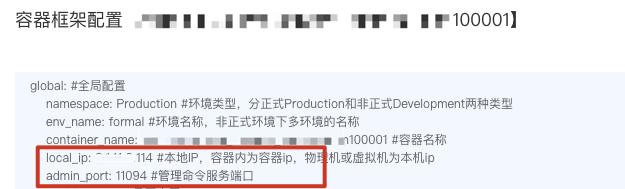
公司内部已经搭好了pprof的代理,只需要输入ip和刚才admin服务端口就能看到相应的内存分配和cpu分配图。
但是上面的可视化界面偶尔会很慢或者失败,所以我们还是用简单粗暴的方式,直接用pprof的命令。
(二)pprof heap
有了pprof就很好办了是吧,瞬间柳暗花明啊,“这个内存泄漏我马上就能fix”,找了一天晚上八点钟,准时蹲着内存泄漏。我们直接找一台能ping通容器并且装了golang的机器,直接用下面的命令看看当前服务的内存分配情况:
$ go tool pprof -inuse_space http://ip:amdin_port/debug/pprof/heap-inuse_space参数就是当前服务使用的内存情况,还有一个-alloc_space参数是指服务启动以来总共分配的内存情况,显然用前者比较直观,进入交互界面后我们用top命令看下当前占用内存最高的部分:
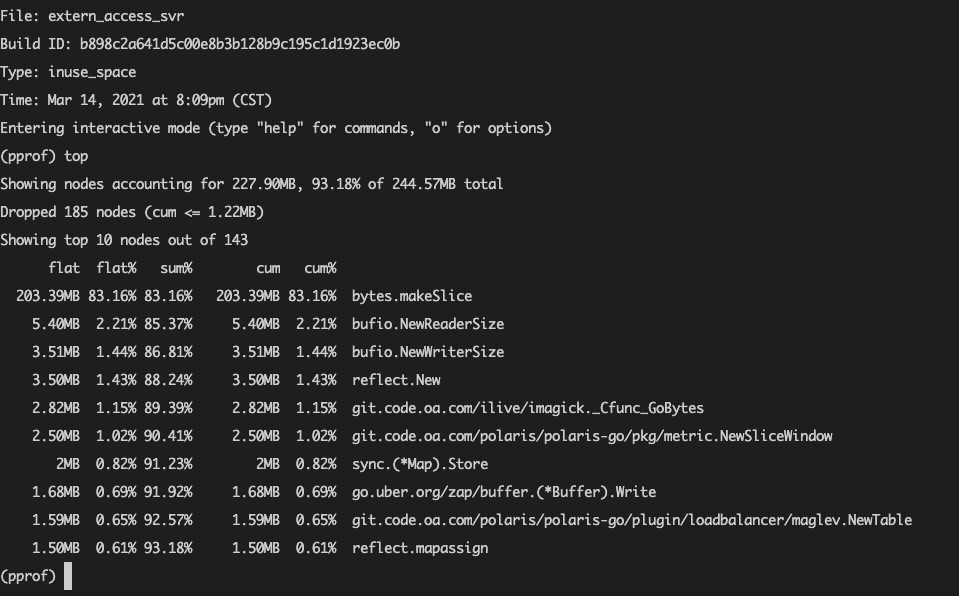
“结果是非常的amazing啊”,当时的内存分配最大的就是bytes.makeSlice,这个是不存在内存泄漏问题的,我们再用命令png生成分配图看看(需要装graphviz):
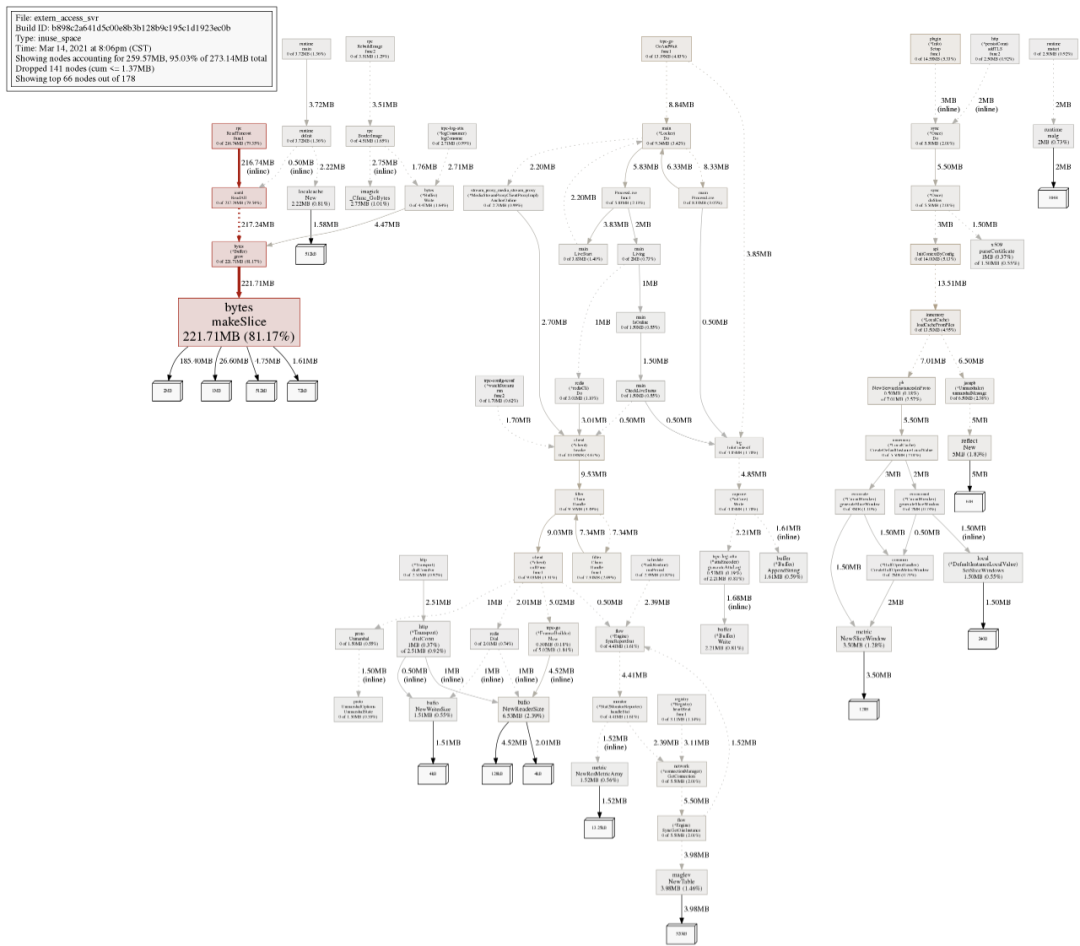
看起来除了bytes.makeSlice分配内存比较大,其他好像也并没有什么问题,不行,再抓一下当前内存分配的详情:
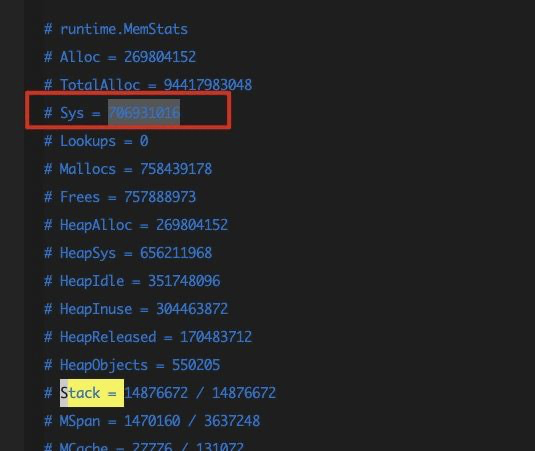
$ wget http://ip:admin_port/debug/pprof/heap?debug=1这个命令其实就是把当前内存分配的详情文件抓了下来,本地会生成一个叫heap?debug=1的文件,看一看服务内存分配的具体情况:
三、落——channel导致goroutine泄漏
带着上面的疑惑又思考了许久,突然又想到了导语的那句话:golang10次内存泄漏,8次goroutine泄漏,1次真正内存泄漏。
对啊,说不定是goroutine泄漏呢!于是赶在内存暴涨结束之际,又火速敲下以下命令:
$ wget http://ip:admin_port/debug/pprof/goroutine?debug=1$ wget http://ip:admin_port/debug/pprof/goroutine?debug=2
debug=1就是获取服务当前goroutine的数目和大致信息,debug=2获取服务当前goroutine的详细信息,分别在本地生成了goroutine?debug=1和goroutine?debug=2文件,先看前者:

服务当前的goroutine数也就才1033,也不至于占用那么大的内存。再看看服务线程挂的子线程有多少:
ps mp 3030923 -o THREAD,tid | wc -l好像也不多,只有20多。我们再看看后者,不看不知道,一看吓一跳:
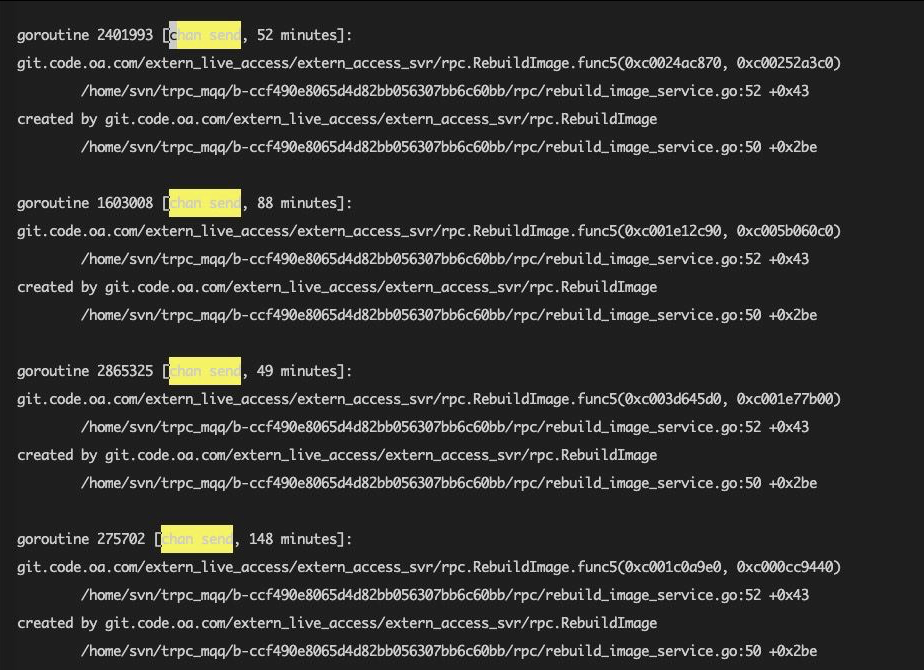
可以看到goroutine里面有很多chan send这种阻塞了很长时间的case,“这不就找到问题了吗?就这?嗯?就这?”,赶紧找到对应的函数,发现之前的同学写了类似这样的代码:
func RebuildImage() {var wg sync.WaitGroupwg.Add(3)// 耗时1go func() {// do sthdefer wg.Done()} ()// 耗时2go func() {// do sthdefer wg.Done()} ()// 耗时3go func() {// do sthdefer wg.Done()} ()ch := make(chan struct{})go func () {wg.Wait()ch <- struct{}{}}()// 接收完成或者超时select {case <- ch:returncase <- time.After(time.Second * 10):return}}
简单来说这段代码就是开了3个goroutine处理耗时任务,最后等待三者完成或者超时失败返回,因为这里的channel在make的时候没有设置缓冲值,所以当超时的时候函数返回,此时ch没有消费者了,就一直阻塞了。看一看这里超时的监控项和内存泄漏的曲线:
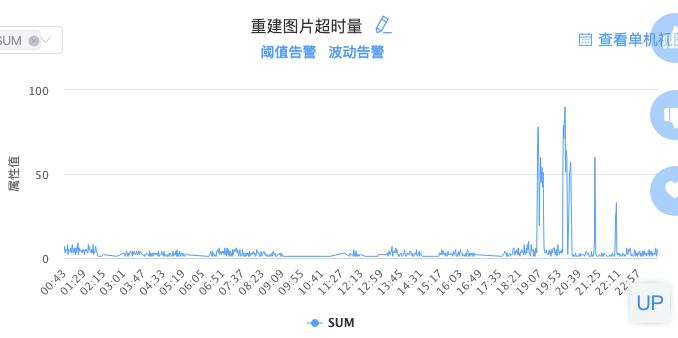
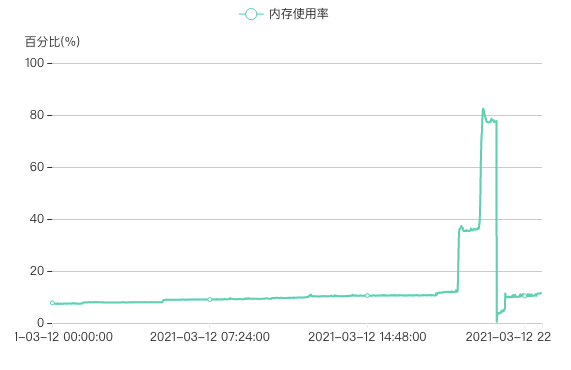
时间上基本是吻合的,“哎哟,问题解决,叉会腰!”,在ch创建的时候设置一下缓冲,这个阻塞问题就解决了:
ch := make(chan struct{}, 1)于是一顿操作:打镜像——喝茶——等镜像制作——等镜像制作——等镜像制作……发布,"哎,又fix一个bug,工作真饱和!"
发布之后满怀期待地敲下top看看RES,什么?怎么RES还是在涨?但是现在已经过了内存暴涨的时间了,已经不好复现分析了,只好等到明天晚上八点了……
四、再落——深究问题所在
(一)http超时阻塞导致goroutine泄露
第二天又蹲到了晚上八点,果然内存又开始暴涨了,重复了之前的内存检查操作后发现服务内存分配依然是正常的,但是仿佛又在goroutine上找到了点蛛丝马迹。
再次把goroutine的详情抓下来看到,又有不少http阻塞的goroutine:
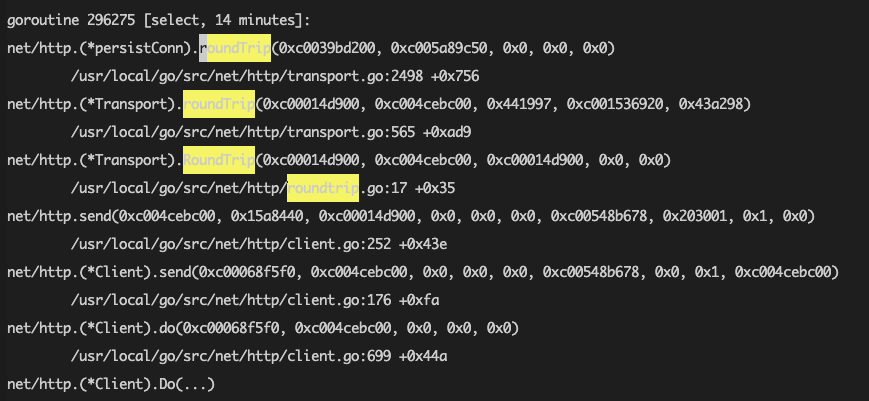
看了下监控项也跟内存的曲线可以对得上,仿佛又看到了一丝丝希望……跟一下这里的代码,发现http相关使用也没什么问题,全局也用的同一个http client,也设置了相应的超时时间,但是定睛一看,什么?这个超时的时间好像有问题:
默认的httpClientvar DefaultCli *http.Clientfunc init() {DefaultCli = &http.Client{Transport: &http.Transport{DialContext: (&net.Dialer{Timeout: 2 * time.Second,KeepAlive: 30 * time.Second,}).DialContext,}}}
这个确实已经设了一个DialContext里面的Timeout超时时间,跟着看一下源码:
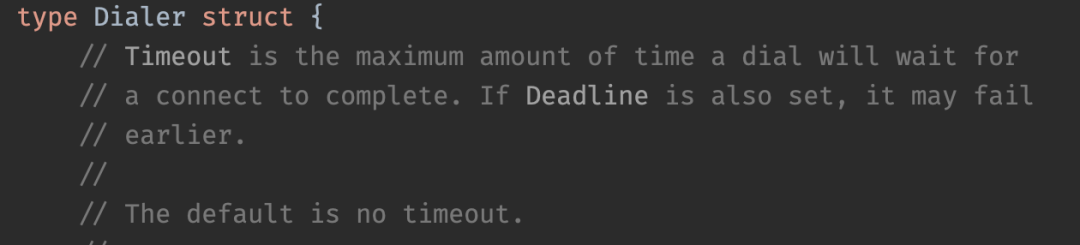
func init() {DefaultCli = &http.Client{Timeout: time.Second * 4,Transport: &http.Transport{DialContext: (&net.Dialer{Timeout: 2 * time.Second,KeepAlive: 30 * time.Second,}).DialContext,}}}
fix之后又是一顿操作:打镜像——喝茶——等镜像制作——等镜像制作——等镜像制作……发布,发布后相应阻塞的goroutine确实也已经没有了。
在组内汇报已经fix内存泄漏的文案都已经编辑好了,心想着这回总该解决了吧,用top一看,内存曲线还是不健康,尴尬地只能把编辑好的汇报文案删掉了……
(二)go新版本内存管理问题
正苦恼的时候,搜到了一篇文章,主要是描述:Go1.12中使用的新的MADV_FREE模式,这个模式会更有效的释放无用的内存,但可能会让RSS增高。
但是不应该啊,如果有这个问题的话大家很早就提出来了,本着刨根问底的探索精神,我在123上面基于官方的golang编译和运行镜像重新打了一个让新的MADV_FREE模式失效的compile和runtime镜像:
还是一顿操作:打镜像——喝茶——等镜像制作——等镜像制作——等镜像制作……发布,结果还是跟预期的一样,内存的问题依然没有解决,到了特定的时候内存还是会激增,并且上去后就不会下来了。
经历了那么多还是没有解决问题,虽然很失落,但是冥冥中已经有种接近真相的感觉了……
五、转——幕后真凶:“cgo”
每晚望着内存的告警还是很不舒服,一晚正一筹莫展的时候打开了监控项走查了各项指标,竟然有大发现……点开ThreadNum监控项,发现他的曲线可以说跟内存曲线完全一致,继续对比了几天的曲线完全都是一样的!
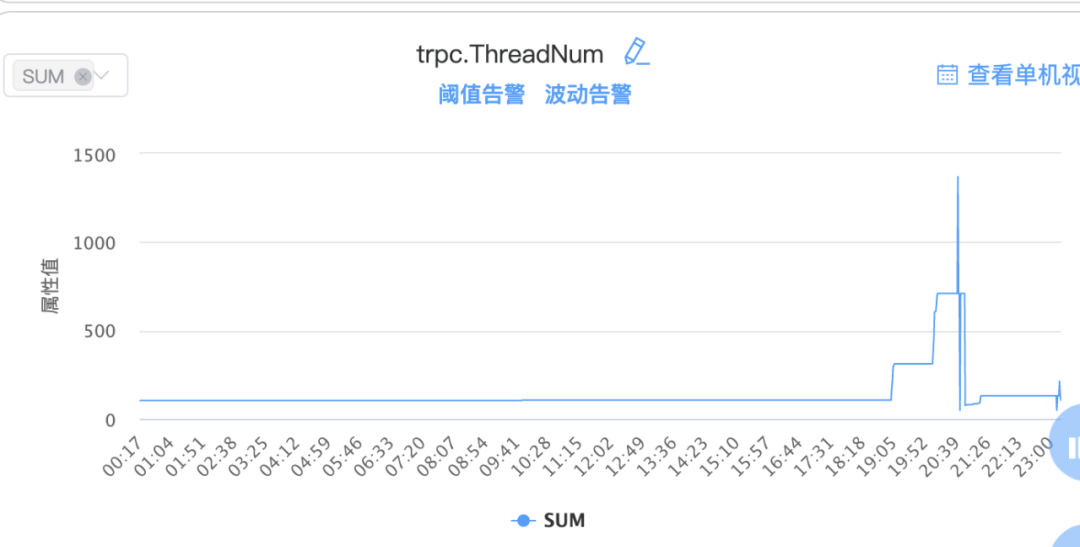
询问了007相关同学,因为有golang的runtime进行管理,所以一般ThreadNum的数量一般来说是不会有太大变动或者说不会激增太多,但是这个服务的ThreadNum明显就不正常了,真相只有一个:服务里面有用到cgo。
对于cgo而言,为了不让goroutine阻塞,cgo都是单独开一个线程进行处理的,这种是runtime不能管理的。
到这,基本算是找到内存源头了,服务里面有用到cgo的一个库进行图片处理,在处理的时候占用了很大的内存,由于某种原因阻塞或者没有释放线程,导致服务的线程数暴涨,最终导致了golang的内存泄漏。
再看看服务线程挂的子线程有多少:
ps mp 3030923 -o THREAD,tid | wc -l此时已经有几百了,之前没发现问题的原因是那个时候内存没有暴涨。
根据数据的对比又重新燃起了信心,花了一晚上时间用纯go重写了图片处理模块,还是一顿操作后发布,这次,仿佛嗅到了成功的味道,感觉敲键盘都带火花。
果不其然,修改了发布后内存曲线稳定,top数据也正常了,不会出现之前内存暴涨的情况,总算是柳暗花明了。

六、合——常规分析手段
这次内存泄漏的分析过程好像已经把所有内存泄漏的情况都经历了一遍:goroutine内存泄漏 —— cgo导致的内存泄漏。
其实go的内存泄漏都不太常见,因为runtime的gc帮我们管理得太好了,常见的内存泄漏一般都是一些资源没有关闭,比如http请求返回的rsp的body,还有一些打开的文件资源等,这些我们一般都会注意到用defer关掉。
排除了常见的内存泄漏可能,那么极有可能内存泄漏就是goroutine泄漏造成的了,可以分析一下代码里有哪些地方导致了goroutine阻塞导致gooutine泄漏了。
如果以上两者都分析正常,那基本可以断定是cgo导致的内存泄漏了。遇到内存泄漏不要害怕,根据下面这几个步骤基本就可以分析出来问题了。
(壹)
先用top看下服务占用的内存有多少(RES),如果很高的话那确实就是服务发生内存泄漏了。
(贰)
在内存不健康的时候快速抓一下当前内存分配情况,看看有没有异常的地方。
$ go tool pprof -inuse_space http://ip:admin_port/debug/pprof/heap这个操作会在当前目录下生成一个pprof目录,进去目录后会生成一个类似这么一个打包的东西:

它保存了当时内存的分配情况,之后想重新查看可以重新通过以下命令进去交互界面进行查看:
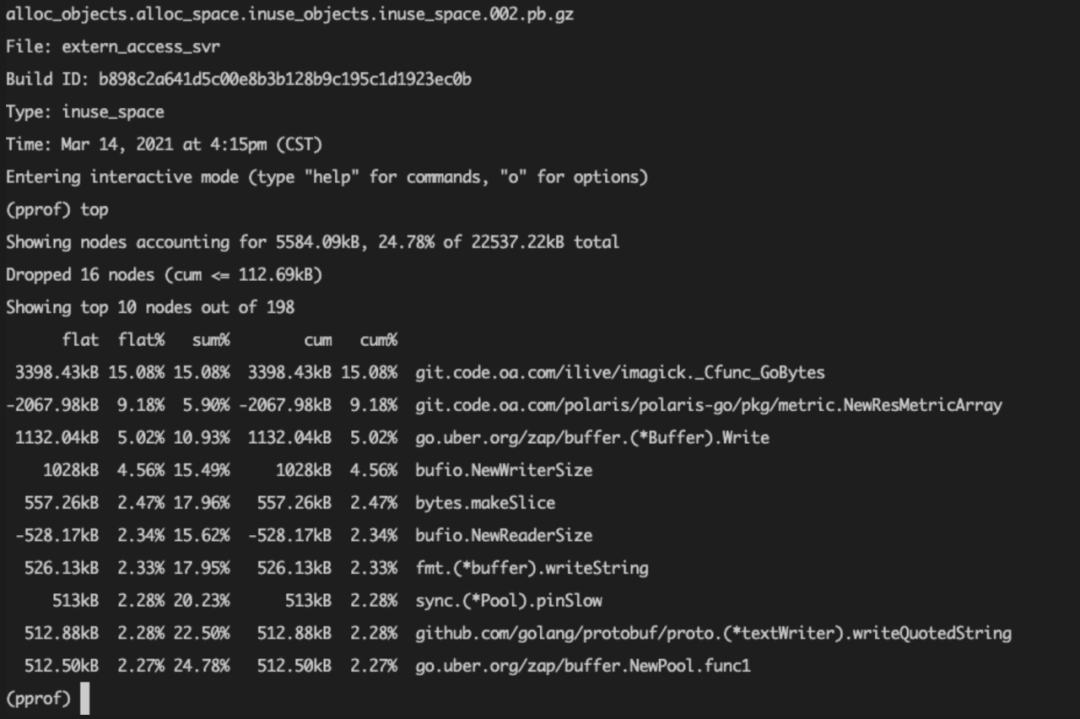
go tool pprof pprof.extern_access_svr.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz我们分析的时候可以先用命令生成一次,等待一段时间后再用命令生成一次,此时我们就得到了两个这个打包文件,然后通过以下命令可以对比两个时间段的内存分配情况:
go tool pprof -base pprof.extern_access_svr.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz pprof.extern_access_svr.alloc_objects.alloc_space.inuse_objects.inuse_space.002.pb.gz通过上述命令进入交互界面后我们可以通过top等命令看到两个时间内存分配的对比情况,如果存在明显内存泄漏问题的话这样就能一目了然:
进一步确认内存分配的详情,我们可以通过以下命令抓一下内存分配的文件,看看当前堆栈的分配情况,如果栈占用的空间过高,有可能就是全局变量不断增长或者没有释放的问题:
$ wget http://ip:admin_port/debug/pprof/heap?debug=1(叁)
如果上述内存分配没有问题,接下来我们抓一下当前goroutine的情况:
$ wget http://ip:admin_port/debug/pprof/goroutine?debug=1$ wget http://ip:admin_port/debug/pprof/goroutine?debug=2
通过debug=1抓下来的文件可以看到当前goroutine的数量,通过debug=2抓下来的文件可以看到当前goroutine的详情,如果存在大量阻塞的情况,就可以通过调用栈找到对应的问题分析即可。
(肆)
如果通过以上分析内存分配和goroutine都正常,就基本可以断定是cgo导致的了,我们可以看看代码里面是否有引用到cgo的库,看看是否有阻塞线程的情况,也可以通过pstack命令分析一下具体是阻塞在哪了。
七、总结
以上分析过程中可能有不严谨或者错误的地方欢迎各位指正,也希望大家看了本篇分析之后在处理内存泄漏的问题上能得心应手。
golang10次内存泄漏,8次goroutine泄漏,1次是真正内存泄漏,还有1次是cgo导致的内存泄漏。
作者简介

李卓奕
腾讯后台开发工程师
腾讯后台开发工程师。目前负责手机浏览器后台相关开发工作,有较丰富的直播开发经验,对微服务框架、go语言性能有较为深入的研究。
推荐阅读