来源:知乎—Fatescript
地址:https://zhuanlan.zhihu.com/p/517279248 本文适合算法研究员/工程师阅读,如果你遇到奇怪的内存泄漏问题,说不定本文能帮你找到答案,解答疑惑。 虽然在大部分场景下,程序的内存泄漏都和数据息息相关。但是读完本文你就会了解,没有被正确使用的Tensor也会导致内存和显存的泄漏。
某次组会的时候,同事报告了一个很好玩的issue:我司某组的一个codebase出现了奇怪的泄漏现象,奇怪的点有以下几个方面: (1)不同的模型,内存/显存泄漏的现象不一样。比如A模型和B模型泄露的速度是不一样的 (2)训练同一个模型的时候,如果在dataset中增加了数据量,相比不加数据,会在更早的epoch就把内存泄漏完。 是不是听起来现象非常离谱,本着”code never lies“的世界观,我开始探求这个现象的真正原因。
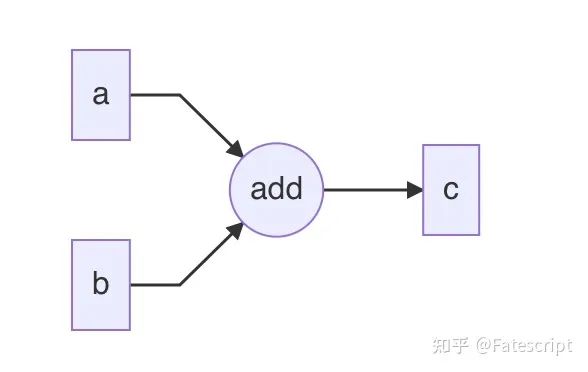
要想解决一个大的问题,首先就要降低问题的复杂度。最小复现代码是我们找问题的基础,而这个写最小复现代码的过程其实也是遵循了一定套路的,此处一并分享给大家: 如果突然出现了历史上没有出现过的问题(比如在某个版本之后突然内存开始泄漏了),用git bisect找到 first bad commit(前提项目管理的比较科学,不会出现很多feature杂糅在一个commit里面;还有就是git checkout之后复现问题的成本不高)。如果bisect大法失效,考虑下面的复现流程。 首先排除data的问题,也就是只创建一个dataloader,让这个loader不停地供数据,看看内存会不会涨(通常data是一系列对不上点、内存泄漏的重灾区)。 其次排除训练的问题,找一个固定数据,不停地让网络训练固定数据进行,看看是否发生泄漏。这一步主要是检查模型、优化器等组件的问题(通常模型本身不会发生泄漏,这一步经常能查出来一些自定义op的case) 最后就是检查一些外围组件了。比如各种自己写的utils/misc的内容。这块通常不是啥重灾区。 最后给出来我的最小复现(psutil需要通过pip安装一下): import torchimport osimport psutildef log_device_usage (count, use_cuda) : mem_Mb = psutil.Process(os.getpid()).memory_info().rss / 1024 ** 2 cuda_mem_Mb = torch.cuda.memory_allocated(0 ) / 1024 ** 2 if use_cuda else 0 print(f"iter {count} , mem: {int(mem_Mb)} Mb, gpu mem:{int(cuda_mem_Mb)} Mb" ) def leak () : use_cuda = torch.cuda.is_available() val = torch.rand(1 ).cuda() if use_cuda else torch.rand(1 ) count = 0 log_iter = 20000 while True : value = torch.rand(1 ).cuda() if use_cuda else torch.rand(1 ) val += value.requires_grad_() if count % log_iter == 0 : log_device_usage(count, use_cuda) count += 1 if __name__ == "__main__" : leak() 试着运行一下,你就会发现你的内存和显存开始泄露了,内存泄漏的比显存更快一些。过一段时间整个程序就会达到memory的上限卡死,接着被kill掉。作为对比,如果加上去的tensor没有梯度(比如将requires_grad_()删掉或者在后面加上detach()),就可以看到没有泄漏发生的log了。 写完了最小复现之后,同事问了我两个问题,大家可以提前思考一下,这两个问题也是本文想要解释清楚的问题: 首先第二个问题很好理解,因为虽然在概念上,torch中的tensor是在gpu上的,但是也只是数据的storage在gpu上,除了在显存上存储的数据,tensor的一些其他信息(比如shape,stride和output_nr等)肯定也是要占据一定内存的。所以在cuda available的时候,内存和显存都会泄漏。 那么第一个问题是因为啥呢?我一时间也难以想明白,于是我打算直接通过torch的源码去找问题的答案。这个过程略长一些,想要看结论的读者可以直接跳到解惑部分。如果对torch内部的东西稍微感兴趣,可以继续看下去。 因为torch里面有很多code是生成出来的(有机会我们可以讲一讲torch的code gen),所以我们需要先编译一下torch(我用的commit hash是2367face)。因为写torch的cuda extension的时候,要使用Tensor就会需要 include <ATen/ATen.h>,以此为线索我最后定位到了一个叫做TensorBody.h的文件,通过fzf在torch/include/ATen/core下的TensorBody.h文件中找到了inplace add的定义,源码如下(torch中inplace都是在原来的名字后面加_,比如add和add_)。 inline at::Tensor & Tensor::add_(const at::Tensor & other, const at::Scalar & alpha) const { return at::_ops::add__Tensor::call(const_cast <Tensor&>(*this ), other, alpha); } 再通过ag找add__Tensor的定义,最后在torch/csrc/autograd/generated文件夹下面的VariableTypeEverything.cpp文件找到。这个文件其实是由VariableType_{0,1,2,3}.cpp多个文件拼接成的。在VariableType_3.cpp中我们可以找到add__Tensor的具体定义。此处我们精简一下和我们的case相关的code方便理解。 at::Tensor & add__Tensor(c10::DispatchKeySet ks, at::Tensor & self , const at::Tensor & other, const at::Scalar & alpha) { auto& self_ = unpack(self , "self" , 0 ); auto& other_ = unpack(other, "other" , 1 ); auto _any_requires_grad = compute_requires_grad( self , other ); (void)_any_requires_grad; check_inplace(self , _any_requires_grad); c10::optional<at::Tensor> original_self; std::shared_ptr<AddBackward0> grad_fn; if (_any_requires_grad) { grad_fn = std::shared_ptr<AddBackward0>(new AddBackward0(), deleteNode); grad_fn->set_next_edges(collect_next_edges( self , other )); grad_fn->other_scalar_type = other.scalar_type(); grad_fn->alpha = alpha; grad_fn->self_scalar_type = self .scalar_type(); } { at::AutoDispatchBelowAutograd guard; at::redispatch::add_(ks & c10::after_autograd_keyset, self_, other_, alpha); } if (grad_fn) { rebase_history(flatten_tensor_args( self ), grad_fn); } return self ; } 这里我们顺便来看一下add__Tensor函数在干啥,unpack方法是对tensor的一个检查,在完成对于tensor的检查之后,计算一下输入tensor是否需要梯度,如果需要梯度,就会进行图的构建(也就是设置tensor对应的一些属性,比如grad_fn),之后用dispatcher发送add的kernel,完成tensor的加法运算。torch中其他的operator如sub、sigmoid等遵循的是一样的逻辑,而正是因为torch里forward过程创建图的逻辑是完全一样的,不同的算子只是launch的kernel类型不同,这些operator的代码才可以通过特定规则生成出来。 如果我们注释掉grad_fn->set_next_edges(collect_next_edges( self, other )); 或 rebase_history(flatten_tensor_args( self ), grad_fn); 这两行code中的任意一行,那么都不会出现内存/显存泄漏的现象,由此我们有证据怀疑是在构建动态图的过程中产生了内存泄漏的。 又因为rebase_history是后面才被调用的,所以set_next_edges过程肯定只是出现泄漏的一个诱因,真正发生泄漏的位置肯定在后调用的位置,由此我们进一步来看rebase_history的实际代码实现。从源码逻辑来看,大部分是检查和确保一些属性的逻辑,核心在于set_gradient_edge(self, std::move(gradient_edge));这一句。由此,我们来看set_gradient_edges的逻辑,当然,为方便理解,下面的code做了一些精简(全部code的参考链接:set_gradient_edge,materialize_autograd_meta,get_auto_grad_meta) void set_gradient_edge (const Variable& self, Edge edge) auto * meta = materialize_autograd_meta(self); meta->grad_fn_ = std ::move(edge.function); meta->output_nr_ = edge.input_nr; } AutogradMeta* materialize_autograd_meta (const at::TensorBase& self) { auto p = self.unsafeGetTensorImpl(); if (!p->autograd_meta()) { p->set_autograd_meta(std ::make_unique<AutogradMeta>()); } return get_autograd_meta(self); } AutogradMeta* get_autograd_meta (const at::TensorBase& self) { return static_cast <AutogradMeta*>(self.unsafeGetTensorImpl()->autograd_meta()); } 看到这里,基本上熟悉pytorch中对于图定义的同学大概就能知道是什么原因了。关于pytorch中forward过程构建图的原理,可以参考官网的blog,作为一个基础概念,我们只需要了解:动态图就是在forward过程中进行图的“创建”,在backward过程完成图的“销毁”。 现在让我们回到数据结构中Graph(图)的概念。在一个自动求导系统中,我们可以将Graph中的Edge(边)简单地理解为一个tensor,Graph中Node(节点)的概念理解为算子。比如在torch里写 c = a + b,其实就是表示有一个a 表示的Edge和一个b代表的Edge连接到一个add的Node(节点)上,这个Node又会连接到一个叫做c的Edge上(下面是一个用mermaid画的一个示意图,其中Edge用矩形表示,Node用圆表示。不难看出,add就是一个入度为2,出度为1的Node)。 c = a + b的Graph形式
既然我们有了图,那么就需要有一些结构保存一部分基本的图信息,这些基本图信息会在自动求导(autograd)的时候使用。在torch中,AutogradMeta就是包含了诸如tensor的autograd历史、hooks等信息的结构,而导致我们内存/显存泄漏的罪魁祸首也正是这个AutogradMeta。 现在,我们已经知道memory实际上泄漏的是啥了。跳回我们写的code,结合gc机制,想一想问题1你是否知道了答案。
至此,我们基本上就可以把问题1解释清楚了:在Tensor的requires_grad为True的时候,Tensor的每次运算都会导致需要保存一份AutogradMeta信息,对应的Tensor也会被加入到计算图中。即使表面上来看你只是做了一些inplace add的操作,但是其实在torch内部,那个临时的Tensor已经进入到了图里,成为了图的一个Edge,且引用计数 + 1,自然是要占据空间的。如果你的Tensor不requires_grad,那么就是只是进行运算,不会有Meta等信息存在,那个暂时生成的Tensor就会引用计数清0被gc了,自然也不会有内存泄漏了。 除了问题1之外,结合上面介绍的内容,我们也能理解,下面一段非常pythonic的code在pytorch里面并不科学的原因。 total_loss = 0 for data in dataloader: loss = model(data) total_loss += loss total_loss.backward() 现在,让我们从最小复现代码回归到codebase,其实我给出的复现里面的代码中的value就是loss,很多时候炼丹师会想要看一下loss的均值/最大值等统计信息,经常会用一个meter保存历史信息,也就对应了复现代码里面的val。 很多奇怪的现象到此也就说的通了,比如不同模型泄漏速度不一样,就是因为不同的模型loss的数量是不一样的,泄漏的速度自然也是不一样的;再比如增加数据会使得同一个模型在更早的epoch到达OOM状态,是因为当数据增加的时候一个epoch内的iter数就会变多,自然会有在更早的epoch把内存泄漏完的现象;曾经能训练的模型加了数据之后也有可能因此变得无法训练。
也许下面这句话对炼丹师来说听起来有些反直觉,但我觉得还是有必要声明一下:无论python前端中tensor看起来是如何动态地进行运算,概念上计算图中的每个节点都无法被inplace修改。 在理解了本文要介绍的原理后,我们也可以轻易写一些reviewer看起来好像没啥问题的泄漏程序了(逃 def leak () : use_cuda = torch.cuda.is_available() val = torch.rand(1 ).cuda() if use_cuda else torch.rand(1 ) val.requires_grad_() count = 0 log_iter = 20000 log_device_usage(count, use_cuda) while True : val += 1 if count % log_iter == 0 : log_device_usage(count, use_cuda) count += 1 为了更好的表示上述代码在执行过程中发生了什么,我用manim写了一个动画来提供更直观的解释,放在结尾也是希望读者能在读完文章后,稍微让头脑休息一下吧:)
猜您喜欢:
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》


 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!