
c# 误区系列(一)
前言
整理很早以前认为的一些误区,准备整理一个系列。新手可以看下,然后大佬指点一下是否哪些地方错了。
正文
值类型存在栈上,引用类型存在堆上
很多人认为用这句话来解释值类型和栈类型的区别,甚至有些文章还公开这样写,把其看做是一种区别。
有这样一个例子,比如说一个类中有一个int类型,请问这个int类型存在堆上还是栈上?
答案是存在堆上。
为什么这么说呢?原因是class的对象是一个引用类型,而类对象的变量的值总是和对象的其他数据在一起,那么就是在堆上。
引用类型在堆上是没有问题的,因为引用类型的确是在堆上建立的。
那么下一个问题,就方法中的值类型存在堆上还是栈上?
存在栈上,那么这个是为什么呢?
因为在代码运行方法里面的程序片段的时候,其实和类对象没有直接关系,间接关系是类对象作为该方法运行的上下文的栈顶。
那么问题来了,是否引用类型可以存在栈上?为什么?
int a=1;a.tostring()和 $"{a}"没有区别?
这个问题是什么时候会发生装箱拆箱问题。
直接能看出装箱和拆箱的就是:object o=a;
那么隐式如何看出呢?
关键就是a 是否调用的是tostring() 是否是int 实现的还是object实现的。
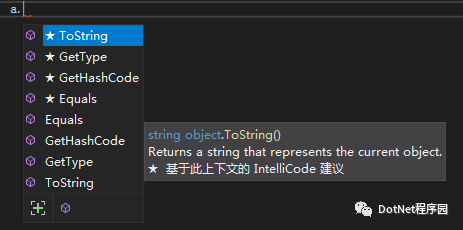
上面这些方法是值得注意的,是调用值类型的方法还是调用的是object 方法,决定是否装箱。
那么问题来了,a+"" 是否发生装箱?
linq中 from 子句中引用的数据源的类型必须为 IEnumerable、IEnumerable<(Of <(T>)>) 或一种派生类型(如 IQueryable<(Of <(T>)>))
其实这个真的不一定,以前我写过一篇。
https://www.cnblogs.com/aoximin/p/13727408.html
如果理解为必须IEnumerable,会陷入一个误区,那就是比如说为了一些对象为了兼容linq,而去实现IEnumerable,这些是完全没有必要。
然后还要一个问题就是,做排序sort用IComparer。IComparer之所以出现,是因为当时需要规范化,里面可以去调用对应的方法进行比较。
但是随着泛型和lambda的出现,一般都是这样写IEnumerable.sort((x,y)=>{
return x.age>y.age;
});
这样的代码更好维护,因为你不比再去关心IComparer(比较器)的修改。IComparer当然具有存在的价值,比如说复杂的比较,复用性也好一点。
属性是变量?
初学的时候,可能有的有吧属性当做变量。
比如说
class person{public stirng Name{get;set;}}
因为可以像调用变量一样使用,所有会对属性产生一些误解。
那么看下历史吧:
第一版:
class person{private string name;private string Name{get{return name;}set{name=value;}}}
然后就是:
class person{private string name;private string Name{get;set;}}
命名的规范就去掉了一些不必要的操作。
然后就是:
class person{public stirng Name{get;set;}}
他们的本质没有变化。
那么为什么使用属性呢?而不是直接使用变量,这其实是编程思维的一个很大的变化。
属性其实是一个接口,是这个对象暴露出去的,而不是直接操作了该对象,体现其封装性。
也就是说该对象是一个盒子,而不是一个可直接操作的东西,任何操作都是在该对象允许的情况下:
下面可以提现其接口性:
class person{public stirng Name{get;private set;}}
可以设置set 为私有来关闭修改,提现了对象的主导性,而不是调用者的主导性。
结
持续更新中,应该有挺多的。