
Python 的切片为什么不会索引越界?

作者:豌豆花下猫
切片(slice)是 Python 中一种很有特色的特性,在正式开始之前,我们先来复习一下关于切片的知识吧。
切片主要用于序列对象中,按照索引区间截取出一段索引的内容。
切片的书写形式:[i : i+n : m] ;其中,i 是切片的起始索引值,为列表首位时可省略;i+n 是切片的结束位置,为列表末位时可省略;m 可以不提供,默认值是 1,不允许为 0,当 m 为负数时,列表翻转。
切片的基本含义是:从序列的第 i 位索引起,向右取到后 n 位元素为止,按 m 间隔过滤 。
下面是一些很有代表性的例子,基本涵盖了切片语法的使用要点:
# @Python猫
li = [1, 4, 5, 6, 7, 9, 11, 14, 16]
# 以下写法都可以表示整个列表,其中 X >= len(li)
li[0:X] == li[0:] == li[:X] == li[:] == li[::] == li[-X:X] == li[-X:]
li[1:5] == [4,5,6,7] # 从1起,取5-1位元素
li[1:5:2] == [4,6] # 从1起,取5-1位元素,按2间隔过滤
li[-1:] == [16] # 取倒数第一个元素
li[-4:-2] == [9, 11] # 从倒数第四起,取-2-(-4)=2位元素
li[:-2] == li[-len(li):-2] == [1,4,5,6,7,9,11] # 从头开始,取-2-(-len(li))=7位元素
# 步长为负数时,列表先翻转,再截取
li[::-1] == [16,14,11,9,7,6,5,4,1] # 翻转整个列表
li[::-2] == [16,11,7,5,1] # 翻转整个列表,再按2间隔过滤
li[:-5:-1] == [16,14,11,9] # 翻转整个列表,取-5-(-len(li))=4位元素
li[:-5:-3] == [16,9] # 翻转整个列表,取-5-(-len(li))=4位元素,再按3间隔过滤
# 切片的步长不可以为0
li[::0] # 报错(ValueError: slice step cannot be zero)
像 C/C++、Java 和 JavaScript 等语言,虽然也支持某些“切片”功能,例如截取数组或字符串的片段,但是,它们并没有一种在语法层面上的通用性支持。
根据维基百科资料,Fortran 是最早支持切片语法的语言(1966),而 Python 则是最具代表性的语言之一。
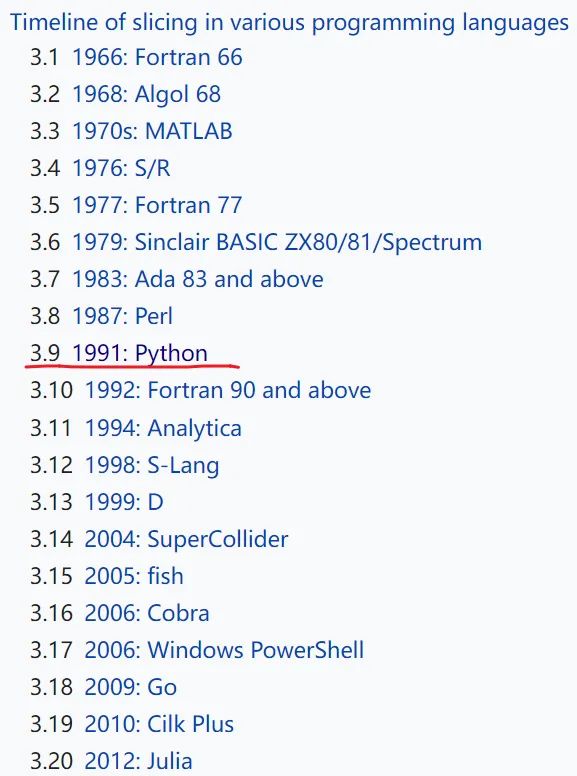
另外,像 Perl、Ruby、Go 和 Rust 等语言,虽然也有切片,但都不及 Python 那样灵活和自由(因为它支持 step、负数索引、缺省索引)。
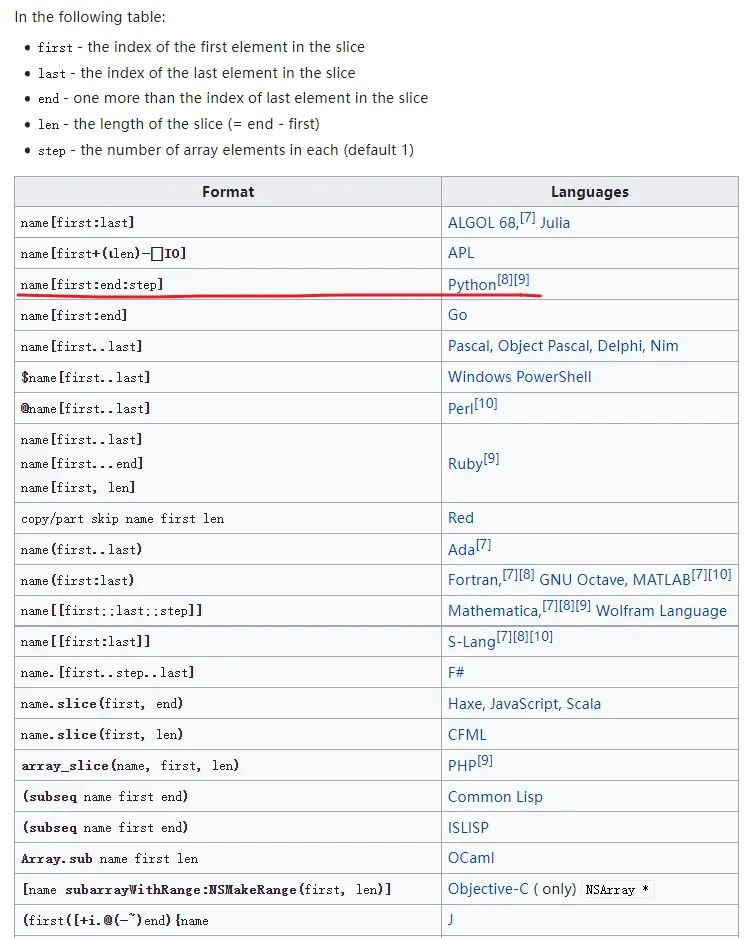
切片的基本用法就能够满足大部分的需求,但是,Python 切片还有一些进阶的用法,例如:切片占位符用法(可实现列表的赋值、删除与拼接操作)、自定义对象实现切片功能、迭代器切片(itertools.islice())、文件对象切片等等。关联阅读:Python进阶:全面解读高级特性之切片!
关于切片的介绍与温习,就到这里了。
下面进入文章标题的问题:Python 的切片语法为什么不会出现索引越界呢?
当我们根据单个索引进行取值时,如果索引越界,就会得到报错:“IndexError: list index out of range”。
>>> li = [1, 2]
>>> li[5]
Traceback (most recent call last):
File "" , line 1, in
IndexError: list index out of range
对于一个非空的序列对象,假设其长度为 length,则它有效的索引值是从 0 到(length - 1)。如果把负数索引也考虑进去,则单个索引值的有效区间是 [-length, length - 1] 闭区间。
但是,当 Python 切片中的索引超出这个范围时,程序并不会报错。
>>> li = [1, 2]
>>> li[1:5] # 右索引超出
[2]
>>> li[5:6] # 左右索引都超出
[]
其实,对于这种现象,官方文档中有所介绍:
The slice of s from i to j is defined as the sequence of items with index k such that
i <= k < j. If i or j is greater thanlen(s), uselen(s). If i is omitted orNone, use0. If j is omitted orNone, uselen(s). If i is greater than or equal to j, the slice is empty.
也就是说:
当左或右索引值大于序列的长度值时,就用长度值作为该索引值; 当左索引值缺省或者为 None 时,就用 0 作为左索引值; 当右索引值缺省或者为 None 时,就用序列长度值作为右索引值; 当左索引值大于等于右索引值时,切片结果为空对象。
对照上面的例子,可以得到:
>>> li = [1, 2]
>>> li[1:5] # 等价于 li[1:2]
[2]
>>> li[5:6] # 等价于 li[2:2]
[]
归结起来一句话:Python 解释器把可能导致索引越界的操作给屏蔽了,你的写法可以很自由,但是最终的结果会被死死限制在合法的索引区间内。
对于这个现象,我其实是有点疑惑的,为什么 Python 不直接报索引越界呢,为什么要修正切片的边界值,为什么一定要返回一个值呢,即便这个值可能是个空序列?
当我们使用“li[5:6]”时,至少在字面意义上想表达的是“取出索引从 5 到 6 所对应的值”,就像是在说“取出书架上从左往右数的第 6 和 7 本书”。
如果程序是如实地遵照我们的指令的话,它就应该报错,就应该说:对不起,书架上的书不够数。
实话说,我并没有查到这方面的解释,这篇文章也不是要给大家科普 Python 在设计上有什么独到的见解。恰恰相反,这篇文章的主要目的之一是希望得到大家的回复解答。
在 Go 语言中,遇到同样的场景时,它的做法是报错“runtime error: slice bounds out of range”。
在 Rust 语言中,遇到同样的场景时,它的做法是报错“byte index 5 is out of bounds of ......”。
在其它支持切片语法的语言中,也许还有跟 Python 一样的设计。但是,我还不知道有没有(学识浅薄)……
最后,继续回到标题中的问题“Python 的切片为什么不会索引越界”。我其实想问的问题有两个:
当切片语法中的索引超出边界时,为什么 Python 还能返回结果,返回结果的计算原理是什么? 为什么 Python 的切片语法要允许索引超出边界呢,为什么不设计成抛出索引错误?
对于第一个问题的回答,官方文档已经写得很明白了。
对于第二个问题,本文暂时没有答案。
也许我很快就能找到答案,但是,也可能需要很久。不管如何,本文先到此为止了。
如果你喜欢研究 Python 设计上的小细节,感兴趣探求“为什么”问题的解答,欢迎关注“Python为什么”系列文章。
推荐阅读最受大家喜欢的往期话题:
(3)Python 之父为什么嫌弃 lambda 匿名函数?
(5)Python 疑难问题:[] 与 list() 哪个快?为什么快?快多少呢?
(6)Python 为什么不支持 i++ 自增语法,不提供 ++ 操作符?
本文属于“Python为什么”系列(Python猫出品),该系列主要关注 Python 的语法、设计和发展等话题,以一个个“为什么”式的问题为切入点,试着展现 Python 的迷人魅力。所有文章将会归档在 Github 上,项目地址:https://github.com/chinesehuazhou/python-whydo
