
一张图解释清楚大数据技术架构
我们先来看看这张图,这是某公司使用的大数据平台架构图,大部分公司应该都差不多:
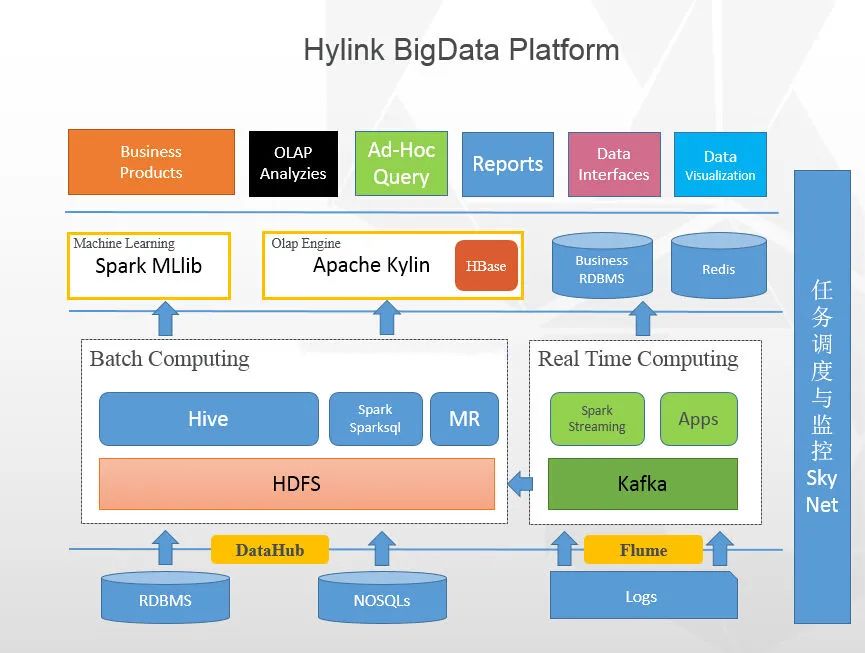
从这张大数据的整体架构图上看来,大数据的核心层应该是:数据采集层、数据存储与分析层、数据共享层、数据应用层,可能叫法有所不同,本质上的角色都大同小异。
所以我下面就按这张架构图上的线索,慢慢来剖析一下,大数据的核心技术都包括什么。
一、数据采集
网站日志
业务数据库

来自于Ftp/Http的数据源
其他数据源
二、数据存储与分析

Spark是这两年非常火的,经过实践,它的性能的确比MapReduce要好很多,而且和Hive、Yarn结合的越来越好,因此,必须支持使用Spark和SparkSQL来做分析和计算。因为已经有Hadoop Yarn,使用Spark其实是非常容易的,不用单独部署Spark集群。
三、数据共享
另外,一些实时计算的结果数据可能由实时计算模块直接写入数据共享。
四、数据应用
业务产品(CRM、ERP等)
报表(FineReport、业务报表)
即席查询
即席查询的用户有很多,有可能是数据开发人员、网站和产品运营人员、数据分析人员、甚至是部门老大,他们都有即席查询数据的需求;
这种即席查询通常是现有的报表和数据共享层的数据并不能满足他们的需求,需要从数据存储层直接查询。
OLAP
其它数据接口
这种接口有通用的,有定制的。比如:一个从Redis中获取用户属性的接口是通用的,所有的业务都可以调用这个接口来获取用户属性。
五、实时计算
六、任务调度与监控
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)
评论