
【数据竞赛】NLP竞赛中99%上升的技巧!
强化Transformer的语意表示的策略

在诸多NLP等的问题中,我们会使用预训练模型并在其最后一层进行微调,例如我们就会经常采用下面的微调方式:
在Transformer之后为下游任务或模型的后面部分添加一个额外的输出层,并使用该模型最后一层的表示作为默认输入。
然而,由于Transformer经常是多层的结构,不同的层可以捕获到不同的表示信息。可以学习到更为丰富的语言信息层次,即:
最下层的表面特征; 中间层的句法特征; 更高层的语义特征。
BERT的作者通过将不同的向量组合作为输入特征输入到命名实体识别任务的BiLSTM,并观察结果F1分数,来测试单词嵌入的策略。最后四层的连接产生了最好的结果
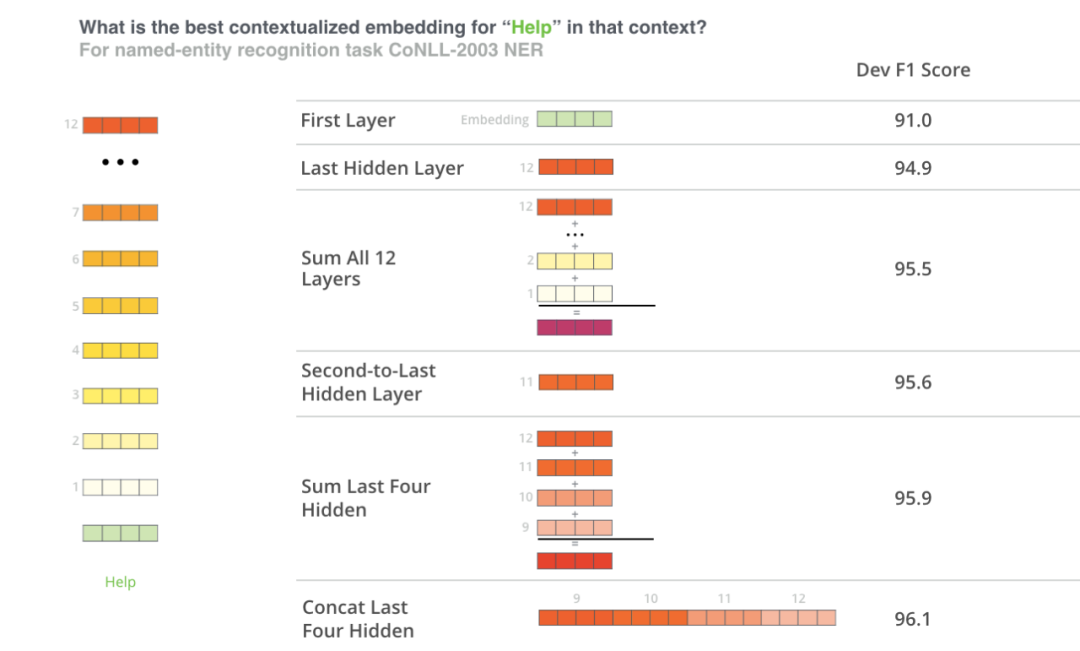
也就是说,如果我们处理NLP的相关问题时:
我们应该将后续的多层输出结果一起进行拼接用作后续的输入可以拿到比任何某层更好的效果。
代码摘自:https://towardsdatascience.com/my-first-gold-in-kaggle-tips-and-tricks-for-an-nlp-competition-cec48dda5895
class AttentionHead(nn.Module):
def __init__(self, h_size, hidden_dim=512):
super().__init__()
self.W = nn.Linear(h_size, hidden_dim)
self.V = nn.Linear(hidden_dim, 1)
def forward(self, features):
att = torch.tanh(self.W(features))
score = self.V(att)
attention_weights = torch.softmax(score, dim=1)
context_vector = attention_weights * features
context_vector = torch.sum(context_vector, dim=1)
return context_vector
class CLRPModel(nn.Module):
def __init__(self,transformer,config):
super(CLRPModel,self).__init__()
self.h_size = config.hidden_size
self.transformer = transformer
self.head = AttentionHead(self.h_size*4)
self.linear = nn.Linear(self.h_size*2, 1)
self.linear_out = nn.Linear(self.h_size*8, 1)
def forward(self, input_ids, attention_mask):
transformer_out = self.transformer(input_ids, attention_mask)
all_hidden_states = torch.stack(transformer_out.hidden_states)
cat_over_last_layers = torch.cat(
(all_hidden_states[-1], all_hidden_states[-2], all_hidden_states[-3], all_hidden_states[-4]),-1
)
cls_pooling = cat_over_last_layers[:, 0]
head_logits = self.head(cat_over_last_layers)
y_hat = self.linear_out(torch.cat([head_logits, cls_pooling], -1))
return y_hat在NLP所有用到预训练模型的问题中,我们都应该尝试将最后几层一起拼接使用的策略。
http://jalammar.github.io/illustrated-bert/ https://towardsdatascience.com/my-first-gold-in-kaggle-tips-and-tricks-for-an-nlp-competition-cec48dda5895
往期精彩回顾 本站qq群955171419,加入微信群请扫码:
评论