
再见 CSV,速度提升 150 倍!
大家好,我是宝器!
为什么要和CSV再见?
CSV再见。其实也谈不上彻底再见吧,日常还是要用的,这里再介绍一个更加高效的数据格式。Python处理数据时保存和加载文件属于日常操作了,尤其面对大数据量时我们一般都会保存成CSV格式,而不是Excel。一是因为Excel有最大行数1048576的限制,二是文件占用空间更大,保存和加载速度很慢。CSV没有行数限制,相对轻便,但是面对大数据量时还是略显拉夸,百万数据量储存加载时也要等好久。。不过很多同学都借此机会抻抻懒腰、摸摸鱼,充分利用时间也不错 。
。CSV 并不是唯一的数据存储格式。今天和大家介绍一个速度超快、更加轻量级的二进制格式保存格式:feather。Feather是什么?
Feather 是一种用于存储数据帧的数据格式。它最初是为了 Python 和 R 之间快速交互而设计的,初衷很简单,就是尽可能高效地完成数据在内存中转换的效率。Feather 也不仅限于 Python 和 R 了,基本每种主流的编程语言中都可以用 Feather 文件。不过,要说明下,它的数据格式并不是为长期存储而设计的,一般的短期存储。如何在Python中操作Feather?
Python 中,可以通过 pandas 或 Feather 两种方式操作。首先需要安装feather-format。# pip
pip install feather -format
# Anaconda
conda install -c conda-forgefeather-format
Feather、Numpy 和 pandas 来一起配合。数据集有 5 列和 1000 万行随机数。import feather
import numpy as np
import pandas as pd
np.random.seed = 42
df_size = 10000000
df = pd.DataFrame({
'a': np.random.rand(df_size),
'b': np.random.rand(df_size),
'c': np.random.rand(df_size),
'd': np.random.rand(df_size),
'e': np.random.rand(df_size)
})
df.head()
csv的操作难度一个水平线,非常简单。DataFrame 直接to_feather 的 Feather 格式:df.to_feather('1M.feather')
Feather 库执行相同操作的方法:feather.write_dataframe(df, '1M.feather')
pandas加载:df = pd.read_feather('1M.feather')
Feather 加载:df =feather.read_dataframe('1M.feather')
和CSV的区别
feather和csv的差距有多大。下图显示了上面本地保存 DataFrame 所需的时间: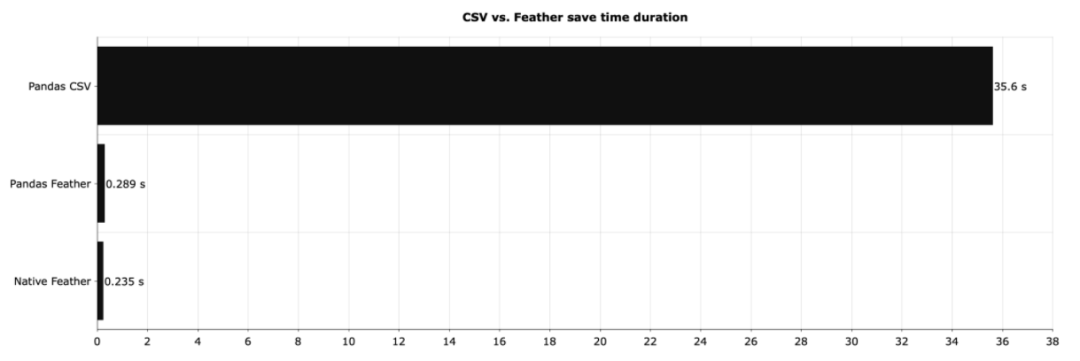
Feather(图中的Native Feather)比 CSV 快了将近 150 倍左右。如果使用 pandas 处理 Feather 文件并没有太大关系,但与 CSV 相比,速度的提高是非常显著的。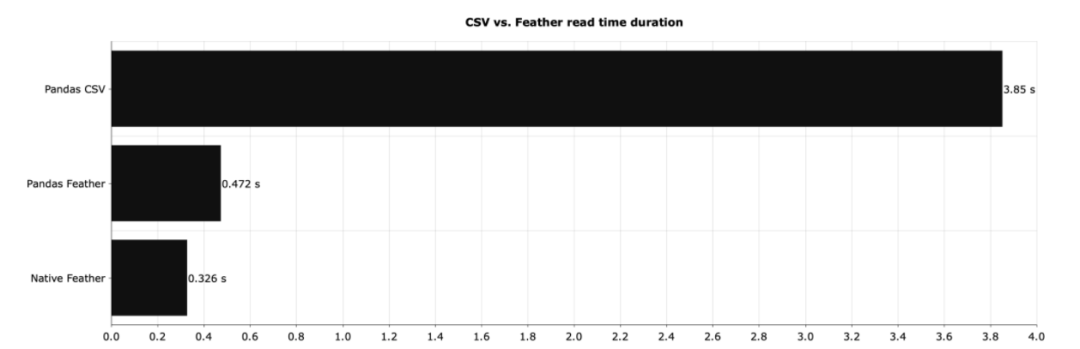
CSV 的读取速度要慢得多。并且CSV占用的磁盘空间也更大。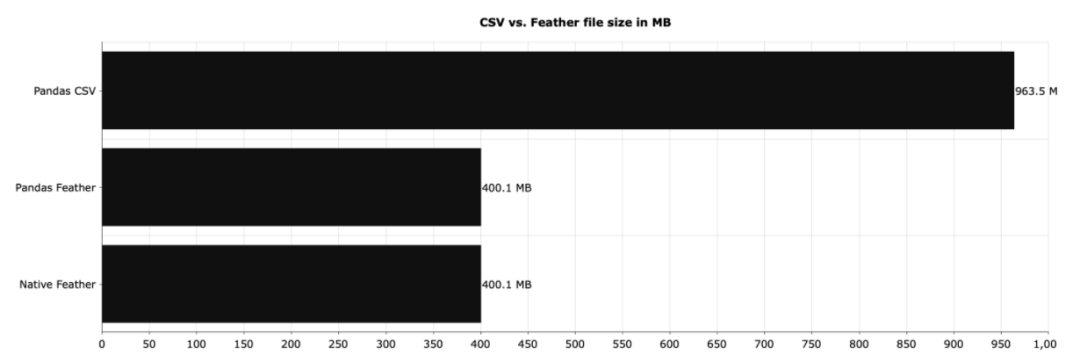
CSV 文件占用的空间是 Feather 文件占用的空间的两倍多。假如我们每天存储千兆字节的数据,那么选择正确的文件格式至关重要。Feather 在这方面完全碾压了 CSV。Parquet,也是一个可以替代CSV 的格式。结语
 。 这个东西怎么说呢
。 这个东西怎么说呢 ,当你需要它时,它就有用,如果日常没有速度和空间的强烈需求,还是老老实实
,当你需要它时,它就有用,如果日常没有速度和空间的强烈需求,还是老老实实CSV吧。CSV已经用惯了,改变使用习惯还是挺难的。评论