
再见,CSV!这种文件格式快150倍!

导读:本文介绍了一种运行速度大大提高的数据格式。

# Pip
pip install feather-format
# Anaconda
conda install -c conda-forge feather-formatimport feather
import numpy as np
import pandas as pd
np.random.seed=42
df_size = 10_000_000
df = pd.DataFrame ({
‘a’: np.random.rand (df_size),
‘b’: np.random.rand (df_size),
‘c’: np.random.rand (df_size),
‘d’: np.random.rand (df_size),
‘e’: np.random.rand (df_size)
})
df.head ()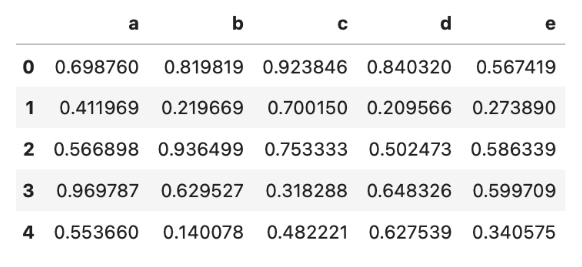
df.to_feather('1M.feather')feather.write_dataframe(df, '1M.feather')
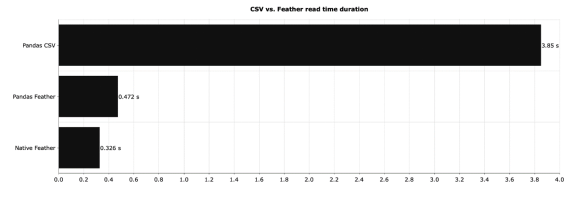
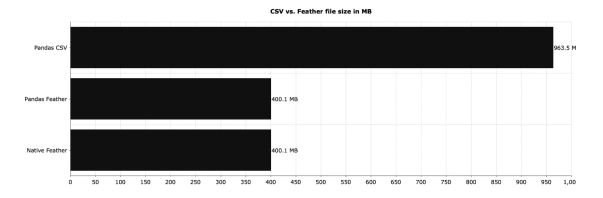
df = pd.read_feather('1M.feather')
df = feather.read_dataframe('1M.feather')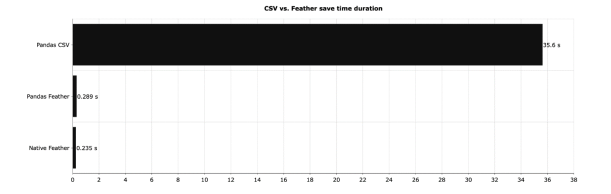

延伸阅读👇

《利用Python进行数据分析》(原书第2版)
干货直达👇
评论