
AI都会写灵魂Rap了?Transformer跨界说唱,节奏、流畅度都不在话下

来源:机器之心 本文约1900字,建议阅读5分钟
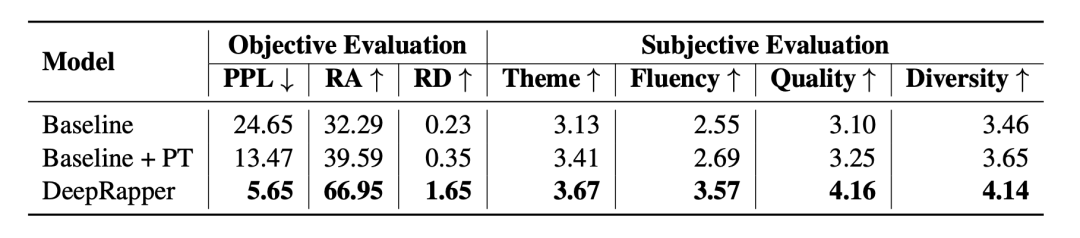
Rapper 要酝酿一整天的歌词,AI 或许几分钟就能写出来。





论文链接:
https://arxiv.org/pdf/2107.01875.pdf
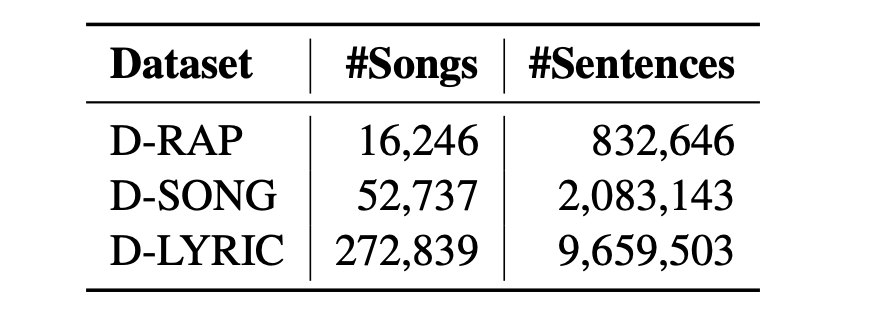
节拍对齐的非说唱歌曲,它可以比说唱数据集更大,因为非说唱歌曲比说唱歌曲更通用;
纯歌词,同样比非说唱歌曲数据集更大。


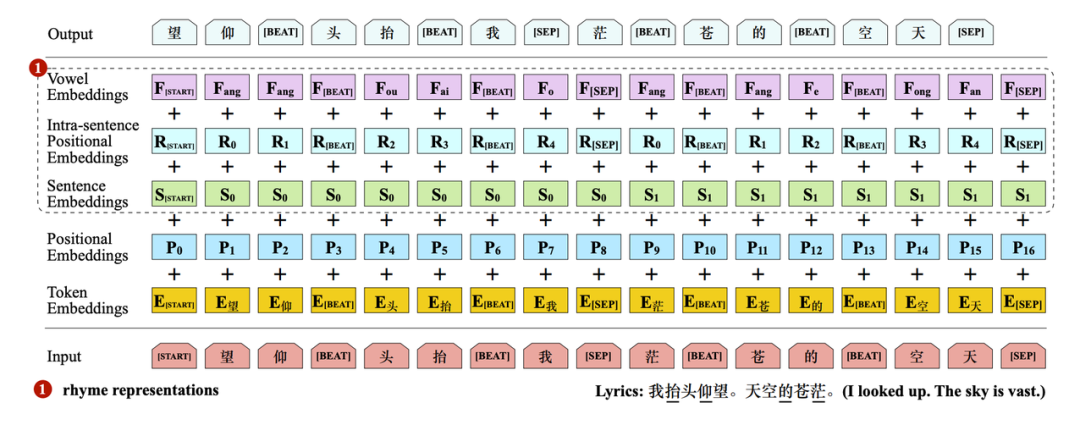
为了更好地建模韵律,该模型从左到右生成歌词句子,这是因为押韵字通常位于句子结尾;
如前所述,节奏对于 rap 效果至关重要,因而插入了一个特殊的 token [BEAT]来进行显式节拍建模;
与仅有词嵌入和位置嵌入的原始 Transformer 不同,研究者添加了多个额外嵌入以更好地建模韵律和节奏。

编辑:王菁
校对:林亦霖
评论