
(附代码)别动不动就画折线图了,教你4种酷炫可视化方法
点击左上方蓝字关注我们

转载自 | 小白学视觉
# Importing libs
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Create a random dataset
data = pd.DataFrame(np.random.random((10,6)), columns=["Iron Man","Captain America","Black Widow","Thor","Hulk", "Hawkeye"])
print(data)
# Plot the heatmap
heatmap_plot = sns.heatmap(data, center=0, cmap= gist_ncar )
plt.show()
# Importing libs
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import skewnorm
# Create the data
speed = skewnorm.rvs(4, size=50)
size = skewnorm.rvs(4, size=50)
# Create and shor the 2D Density plot
ax = sns.kdeplot(speed, size, cmap="Reds", shade=False, bw=.15, cbar=True)
ax.set(xlabel= speed , ylabel= size )
plt.show()
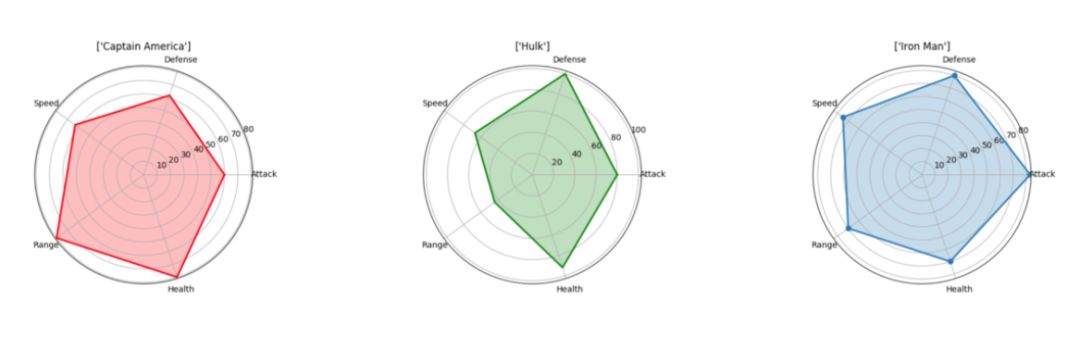
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array(["Attack","Defense","Speed","Range","Health"])
stats=df.loc[0,labels].values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, o- , linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title([df.loc[0,"Name"]])
ax.grid(True)
plt.show()
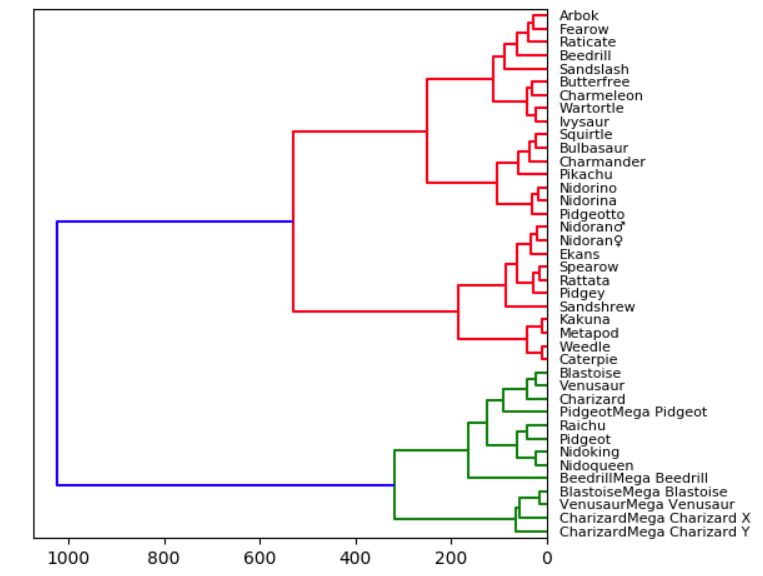
# Import libs
import pandas as pd
from matplotlib import pyplot as plt
from scipy.cluster import hierarchy
import numpy as np
# Read in the dataset
# Drop any fields that are strings
# Only get the first 40 because this dataset is big
df = pd.read_csv( Pokemon.csv )
df = df.set_index( Name )
del df.index.name
df = df.drop(["Type 1", "Type 2", "Legendary"], axis=1)
df = df.head(n=40)
# Calculate the distance between each sample
Z = hierarchy.linkage(df, ward )
# Orientation our tree
hierarchy.dendrogram(Z, orientation="left", labels=df.index)
plt.show()
END
点赞三连,支持一下吧↓
评论