
尝鲜!微软首个AI量化投资开源平台Qlib上手体验!

近日,微软亚洲研究院正式发布了业内首个AI量化投资开源平台Qlib,发布一个月以来已经在GitHub收获2.3k+star!
值得关注的一点就是这套量化系统的框架分为多层,每层由多个松散耦合的模块组成,因此每个模块用户都可以自行修改、定制、使用,如下图所示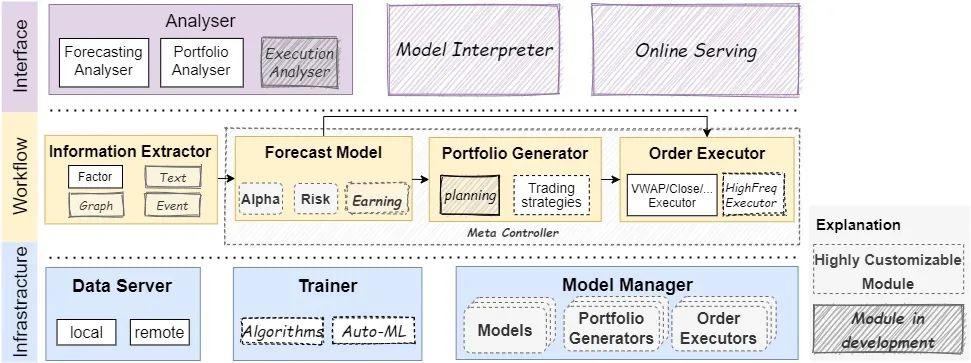
通过这样的方式,可以让用户更快的了解整个工作流程,并灵活的进行调整,同时也支持在线和离线两种模式,嗯,本地取数据、本地跑策略,隐私上也有一定的提升。
更多的宣传点,本文不再过多介绍,下面将从用户使用的角度讲解如何安装配置Qlib并构建一个量化交易模型。
安装
安装Qlib其实和其他第三方库安装类似,但毕竟要跑模型,并且依赖较多,所以可能会由于不同机器环境的问题,导致不同的错误,首先还是尝试直接pip安装
pip install pyqlib
当然我建议从GitHub上把源码拉下来安装
git clone https://github.com/microsoft/qlib.git && cd qlib
pip install .
我分别在macOS Big Sur和centos7下测试,在配置anaconda环境下,均出现不同的报错,如果出现任何类似如下报错
Failed building wheel for xxx
command 'x86_64-apple-darwin13.4.0-clang' failed with exit status 254
大概率是gcc编译出现问题,可以先在shell中用gcc -v查看gcc的版本信息,之后在mac下可以尝试检查Xcode是否安装并升级GCC版本之后尝试如下代码
export CC=gcc
export CXX=g++
如果提示任何与PyYAML包安装失败相关的报错,可以尝试自己手动卸载sudo pip uninstall PyYAML这个包再重新安装。
为了更好的使用,我们还需要安装配置好redis并启动,此处不做更多讲解,同时一定要注意,对照requires.txt,将版本不对的包进行升级,我就是由于pandas和numpy版本过低,导致无法启动,最后联系开发者才发现问题!
总之安装过程中,可能会出现不同的问题,我们只要耐下心来,仔细阅读报错代码,一点一点解决,总能成功安装好。
配置数据
下载与初始化
在安装好pyqlib后,我们还需要准备数据,官方提供了从Yahoo Finance爬数据的方法,可以在命令行进入之前从GitHub拉下来的文件夹后执行如下命令
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn

等待一会即可,之后我们可以进入~/.qlib/qlib_data/目录下检查数据是否被正确存储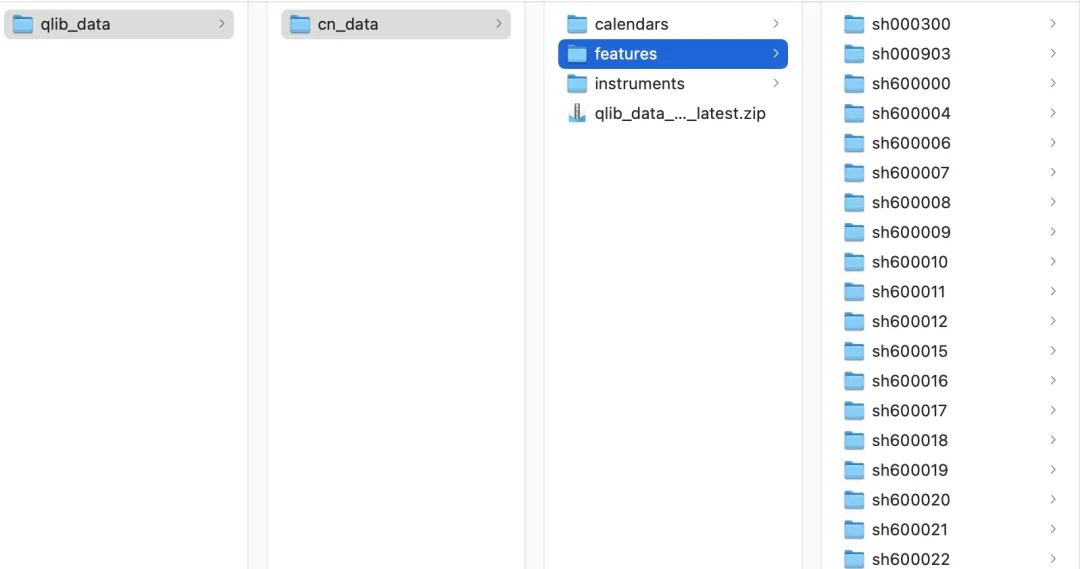
在搞定数据之后,在使用之前还需要进行初始化,进入Python后执行如下命令
import qlib
# region in [REG_CN, REG_US]
from qlib.config import REG_CN
provider_uri = "~/.qlib/qlib_data/cn_data" # target_dir
qlib.init(provider_uri=provider_uri, region=REG_CN)
数据查询
在上一步我们成功下载并配置好数据之后,现在可以进行一些基本的查询,我们可以启动jupyter notebook,首先还是初始化
import qlib
qlib.init(provider_uri='~/.qlib/qlib_data/cn_data')
之后可以像pandas一样,创建指定格式的时间序列
from qlib.data import D
D.calendar(start_time='2010-01-01', end_time='2017-12-31', freq='day')[:5]
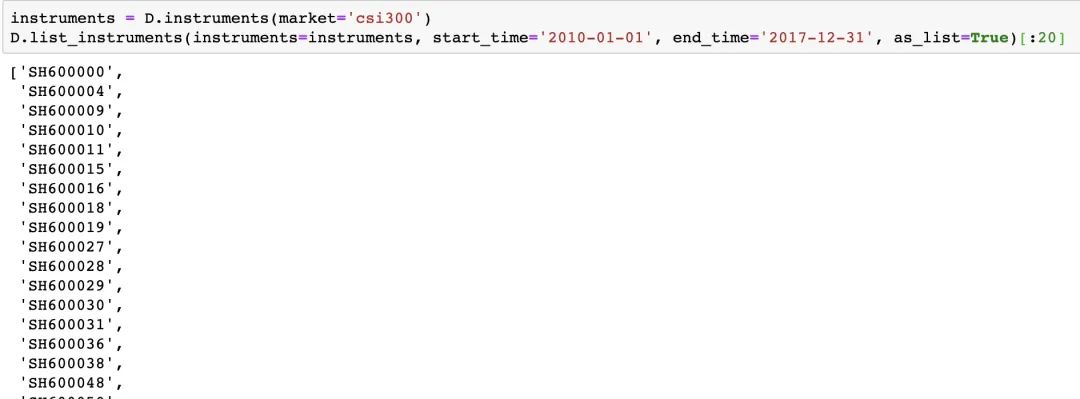
 提取指定时间范围内沪深300的股票代码
提取指定时间范围内沪深300的股票代码
instruments = D.instruments(market='csi300')
D.list_instruments(instruments=instruments, start_time='2010-01-01', end_time='2017-12-31', as_list=True)[:20]
 也可以根据名称动态过滤加载数据
也可以根据名称动态过滤加载数据
更多有关数据查询的操作本文就不再一一示例,感兴趣的话可以查阅官方数据API!
工作流
基本介绍
现在,终于来到最核心的部分——workflow,我们只需要在工作流中构建数据集,训练模型,回测和评估,之后就可以使用qrun自动运行整个工作流程,并在jupyter notebook中给出图形报告分析。
在一个完整的工作流中应包含以下几个部分
“
”
数据
加载数据
处理数据
数据切片
模型
训练与推导
保存与加载
评价
预测信号分析
回测
下面我们来看一个完整的最典型的工作流部分代码,之后进行解读
qlib_init:
provider_uri: "~/.qlib/qlib_data/cn_data"
region: cn
market: &market csi300
benchmark: &benchmark SH000300
data_handler_config: &data_handler_config
start_time: 2008-01-01
end_time: 2020-08-01
fit_start_time: 2008-01-01
fit_end_time: 2014-12-31
instruments: *market
port_analysis_config: &port_analysis_config
strategy:
class: TopkDropoutStrategy
module_path: qlib.contrib.strategy.strategy
kwargs:
topk: 50
n_drop: 5
backtest:
verbose: False
limit_threshold: 0.095
account: 100000000
benchmark: *benchmark
deal_price: close
open_cost: 0.0005
close_cost: 0.0015
min_cost: 5
task:
model:
class: LGBModel
module_path: qlib.contrib.model.gbdt
kwargs:
loss: mse
colsample_bytree: 0.8879
learning_rate: 0.0421
subsample: 0.8789
lambda_l1: 205.6999
lambda_l2: 580.9768
max_depth: 8
num_leaves: 210
num_threads: 20
dataset:
class: DatasetH
module_path: qlib.data.dataset
kwargs:
handler:
class: Alpha158
module_path: qlib.contrib.data.handler
kwargs: *data_handler_config
segments:
train: [2008-01-01, 2014-12-31]
valid: [2015-01-01, 2016-12-31]
test: [2017-01-01, 2020-08-01]
record:
- class: SignalRecord
module_path: qlib.workflow.record_temp
kwargs: {}
- class: PortAnaRecord
module_path: qlib.workflow.record_temp
kwargs:
config: *port_analysis_config
现在我们来看一下这部分代码,读懂最简单的之后才方便后面构建自己的模型。
初始化
首先是初始化部分,和之前一致,主要是对数据进行配置,
qlib_init:
provider_uri: "~/.qlib/qlib_data/cn_data"
region: cn
market: &market csi300
benchmark: &benchmark SH000300
provider_uri是数据存放位置,region代表地区
cn表示Qlib将以中国股票模式初始化
us表示Qlib将以美国股票模式初始化
market参数指定市场为沪深300
接下来一直到task之前,就是对数据、资产、策略等信息的详细配置,这部分和大多数量化平台的方法类似,本文不做过多叙述。
任务task
现在来到最关键的部分task,其中包含三个不同的主要参数Model,Dataset和Record。
在model中我们需要指定使用的模型及相关参数
model:
class: LGBModel
module_path: qlib.contrib.model.gbdt
kwargs:
loss: mse
colsample_bytree: 0.8879
learning_rate: 0.0421
subsample: 0.8789
lambda_l1: 205.6999
lambda_l2: 580.9768
max_depth: 8
num_leaves: 210
num_threads: 20
在dataset部分中,需要指定数据来源已经数据如何切分成训练集、测试集等
dataset:
class: DatasetH
module_path: qlib.data.dataset
kwargs:
handler:
class: Alpha158
module_path: qlib.contrib.data.handler
kwargs: *data_handler_config
segments:
train: [2008-01-01, 2014-12-31]
valid: [2015-01-01, 2016-12-31]
test: [2017-01-01, 2020-08-01]
最后是record部分,它主要负责跟踪训练过程和结果,并记录相关重要的指标信息,方便之后进行展示与评估,下面是record的配置模版
record:
- class: SignalRecord
module_path: qlib.workflow.record_temp
kwargs: {}
- class: PortAnaRecord
module_path: qlib.workflow.record_temp
kwargs:
config: *port_analysis_config
现在只需要将以上代码保存为configuration.yaml,并进入对应目录下执行以下命令
qrun configuration.yaml
就可以执行我们的策略。以上每一个部分的详细配置在官方文档中都非常丰富的介绍与示例,本文不再过多介绍,感兴趣的读者可以自己查阅!
启动
运行单个模型
在写完模型之后,启动方式一共有三种:
“
”
使用Qilb内置的qrun运行上面的workflow
参考examples中workflow_by_code脚本,在Notebook中执行
参考run_all_model.py,写一个Python脚本,从命令行中使用python run_all_model.py --models=lightgbm执行
运行多个模型
在Qlib中,我么可以使用run_all_model.py运行多个模型进行多次迭代,不过当前只能在Linux下执行,并且该脚本将为每个模型创建一个唯一的虚拟环境,并在训练后删除该环境。使用如下命令即可执行
python run_all_model。py 10一个例子
最后,让我们运行一个官方提供的示例策略,位置于examples目录下 可以看到,官方对常见的算法都提供了示例代码,我们选择跑一个LightGBM,在命令行执行
可以看到,官方对常见的算法都提供了示例代码,我们选择跑一个LightGBM,在命令行执行
qrun /Users/liuhuanshuo/Downloads/qlib-main/examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
启动瞬间,风扇就开始转了
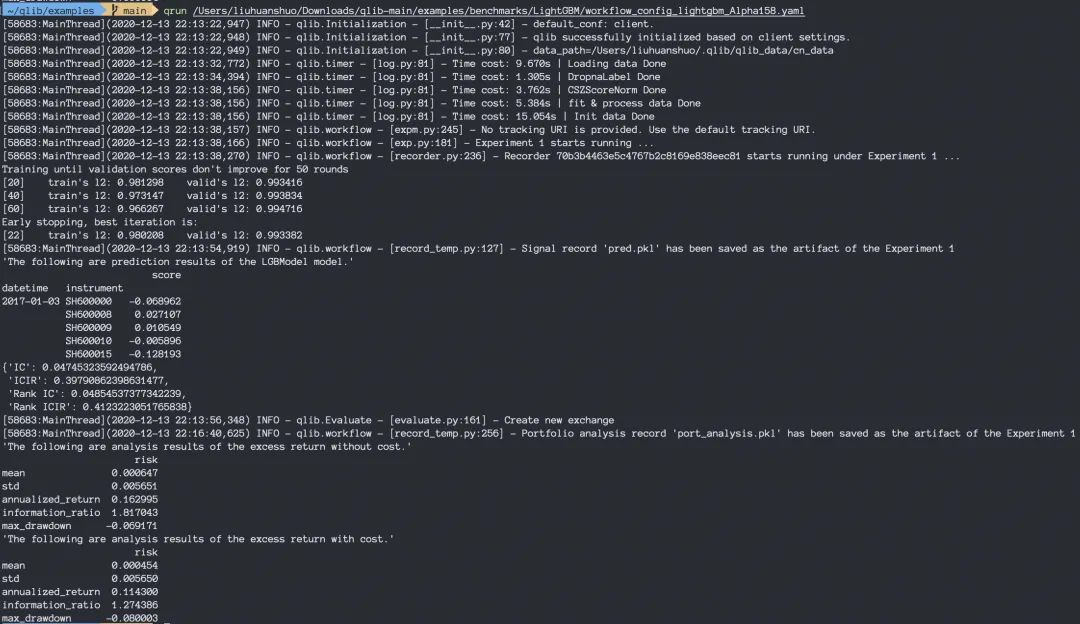 经过一段时间等待后,终端会打印出执行过程中的关键参数与一些日志,除了命令行输出的这些信息之外,更多的过程信息会被写入主目录下的
经过一段时间等待后,终端会打印出执行过程中的关键参数与一些日志,除了命令行输出的这些信息之外,更多的过程信息会被写入主目录下的workflow_by_code.ipynb,我们启动Jupyter Notebook看一下
可以看到,模型建立、执行、预测等全部内容都已经准备好了,我们只需要按照顺序执行一遍,就能看到更丰富的报告,比如回测、回报率、信息指数等?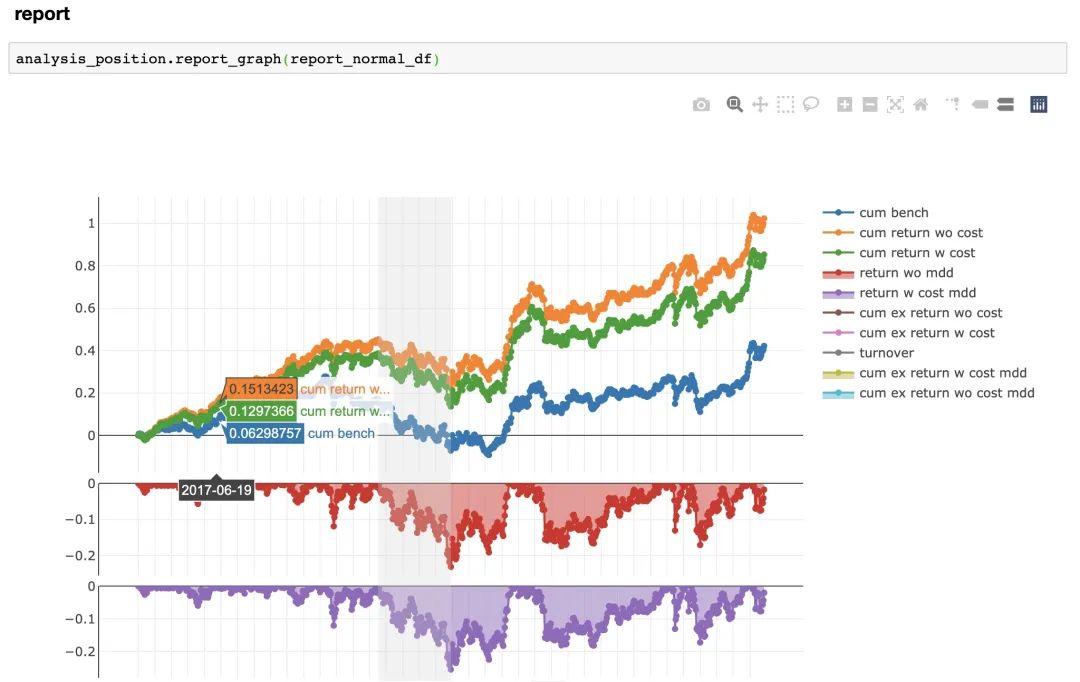

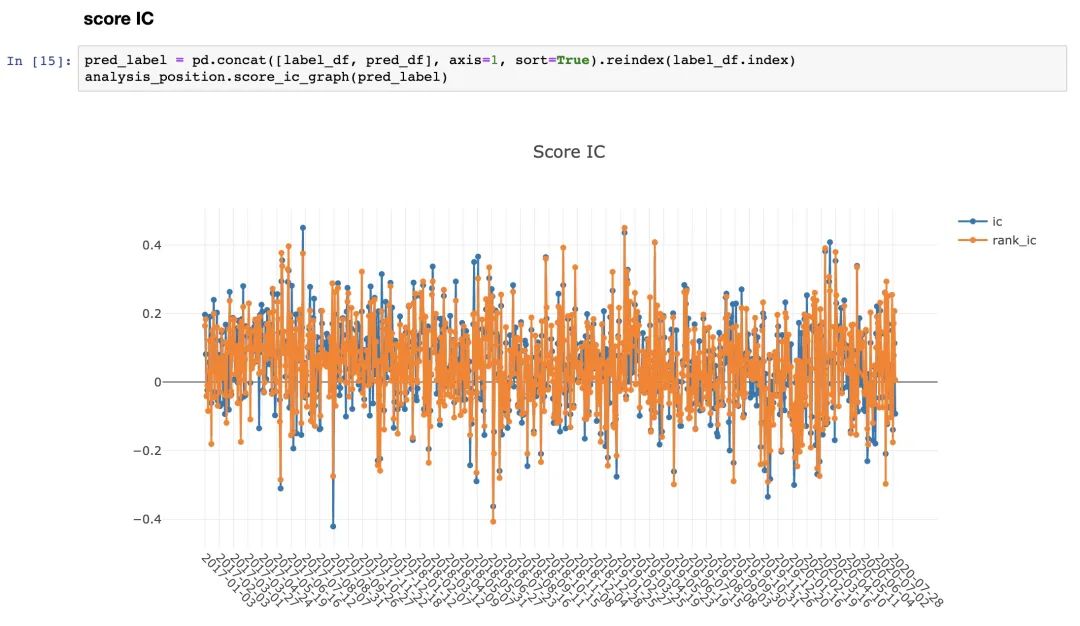

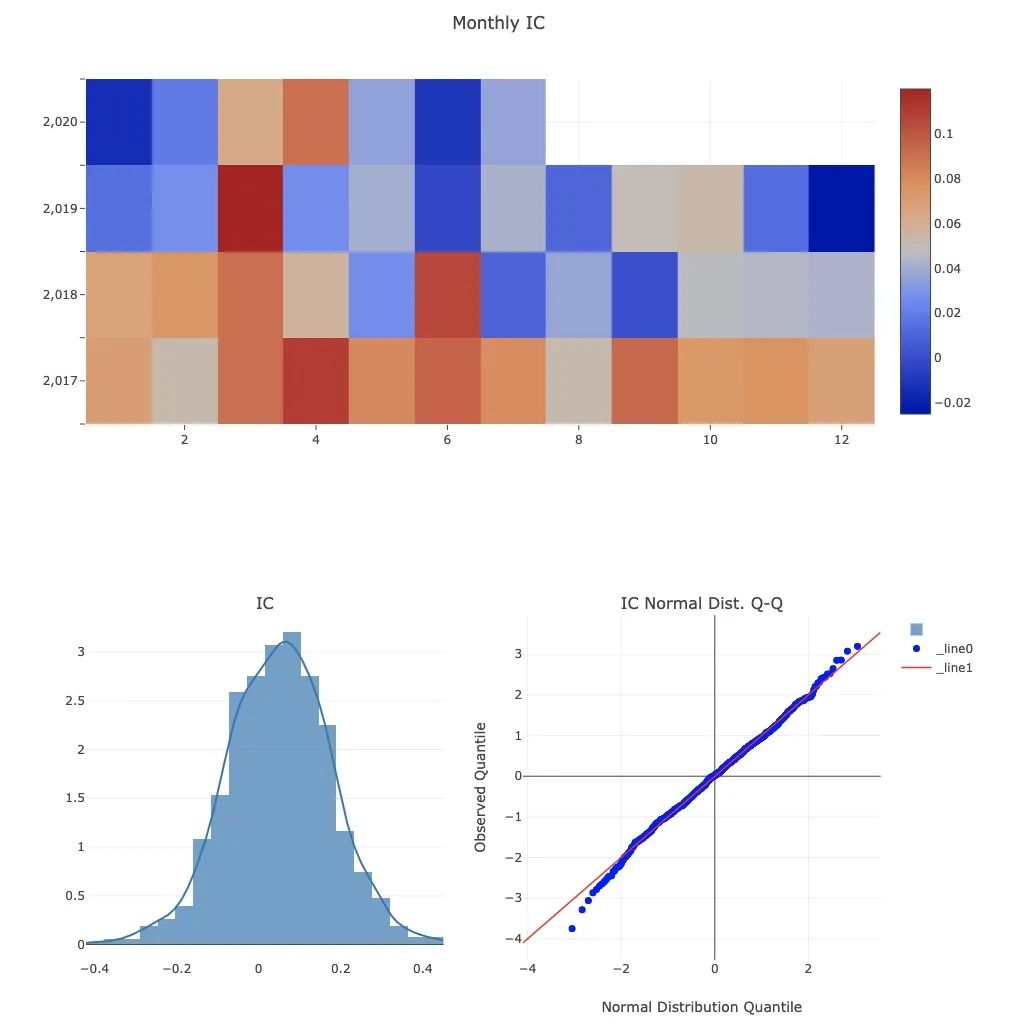
以上只是部分过程(结果),实际给出的评估指标非常多,并且全部用plotly进行可视化,可以进行交互式查看!
离线模式
Qib的另一个特点是可以部署为离线或者在线模式,默认是使用离线模式启动,在此模式下,数据将在本地部署。如果使用在线模式,数据将会部署在服务器,根据官方文档,使用在线模式会有以下好处
集中管理数据。用户不必管理不同版本的数据
减少缓存占用
使数据可以通过远程方式访问
这一块我没有具体研究,毕竟Qlib和其他量化平台相比,支持离线模式就很香了,如果想进一步学习可以查阅官方文档。
本文的分享就到此为止,其实自发布以来关于Qlib的评价目前也褒贬不一,但AI量化注定是趋势,大家可以自己上手体验一下方能做出对比与选择!
参考资料
[1]
Qlib: https://github.com/microsoft/qlib
[2]Qlib docs: https://qlib.readthedocs.io/en/latest/index.html
[3]微软也搞AI量化平台?还是开源的1:https://mp.weixin.qq.com/s/47bP5YwxfTp2uTHjUBzJQQ
-END-
文末推荐一本书Python高手修炼之道,本书系统介绍了如何入门Python并利用Python进行数据处理与机器学习实战。本书从Python的基础安装开始介绍,系统梳理了Python的入门语法知识,归纳介绍了图像处理、数据文件读写、数据库操作等Python基本技能;然后详细讲解了NumPy、Matplotlib、Pandas、Scipy、Scikit-learn等在数据处理、机器学习领域的应用。点击下方小程序可以查看详情,给早起投稿可以直接获得本书(详情点击阅读原文)!