
一文概览神经网络优化算法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

一、机器学习的优化
机器学习的优化(目标),简单来说是:搜索模型的一组参数 w,它能显著地降低代价函数 J(w),该代价函数通常包括整个训练集上的性能评估(经验风险)和额外的正则化(结构风险)。与传统优化不同,它不是简单地根据数据的求解最优解,在大多数机器学习问题中,我们关注的是测试集(未知数据)上性能度量P的优化。
对于模型,测试集是未知,我们只能通过优化训练集的性能度量P_train,在独立同分布基础假设下,期望测试集也有较好的性能(泛化效果),这意味并不是一味追求训练集的最优解。 另外,有些情况性能度量P(比如分类误差f1-score)并不能高效地优化,在这种情况下,我们通常会优化替代损失函数 (surrogate loss function)。例如,负对数似然通常用作 0 − 1 分类损失的替代。
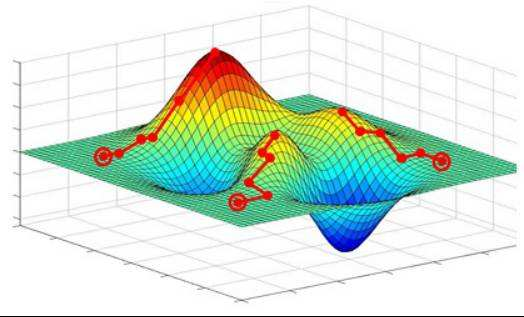
当我们机器学习的学习目标是极大化降低(经验)损失函数,这点和传统的优化是比较相似的,那么如何实现这个目标呢?我们第一反应可能是直接求解损失函数最小值的公式/解析解(如最小二乘法),获得最优的模型参数。但是,通常机器学习模型的损失函数较复杂,很难直接求最优解。幸运的是,我们还可以通过优化算法(如遗传算法、梯度下降算法、牛顿法等)有限次迭代优化模型参数,以尽可能降低损失函数的值,得到较优的参数值(数值解)。上述去搜索一组最\较优参数解w所使用的算法,即是优化算法。下图优化算法的总结:(图与本文内容较相符,摘自@teekee)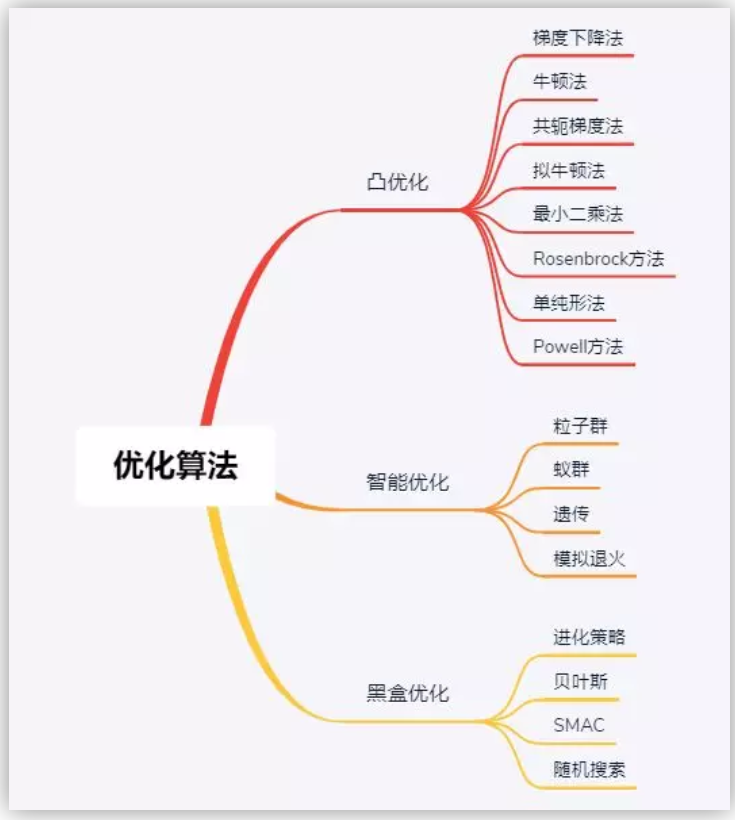
二、优化算法盘点
最小二乘法
最小二乘法常用在机器学习回归模型求解析解(对于复杂的深度神经网络无法通过这方法求解),其几何意义是高维空间中的一个向量在低维子空间的投影。
如下以一元线性回归用最小二乘法求解为例。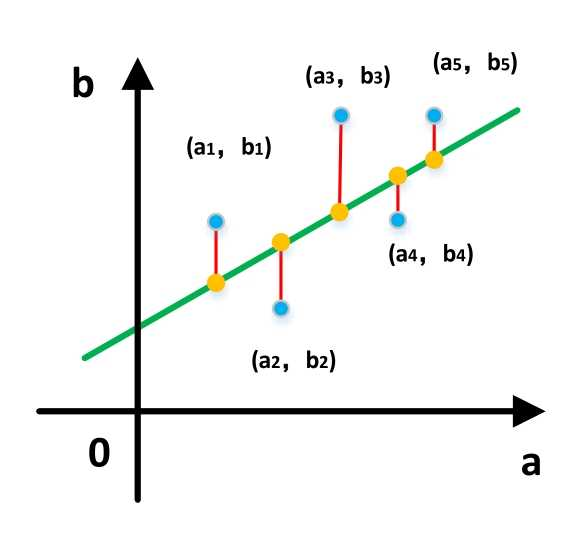
其损失函数mse为: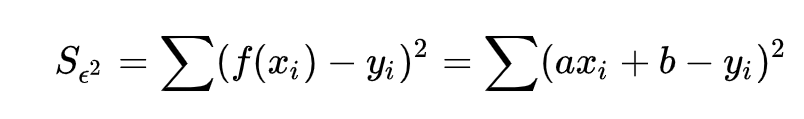 对损失函数求极小值,也就是一阶导数为0。通过偏导可得关于参数a及偏置b的方程组:
对损失函数求极小值,也就是一阶导数为0。通过偏导可得关于参数a及偏置b的方程组: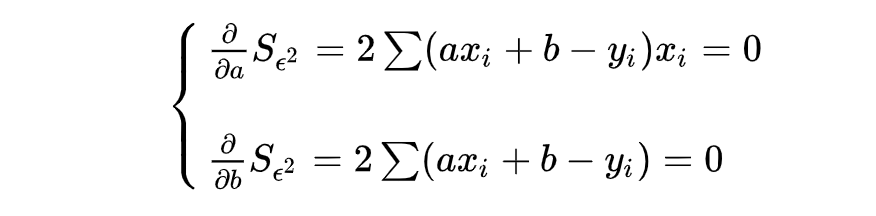 代入数值求解上述线性方程组,可以求解出a,b的参数值。也就是求解出上图拟合的那条直线ax+b。
代入数值求解上述线性方程组,可以求解出a,b的参数值。也就是求解出上图拟合的那条直线ax+b。
遗传算法
注:神经网络优化算法以梯度下降类算法较为高效,也是主流的算法。而遗传算法、贪心算法、模拟退火等优化算法用的比较少。
遗传算法(Genetic Algorithms,GA)是模拟自然界遗传和生物进化论而成的一种并行随机搜索最优化方法。与自然界中“优胜略汰,适者生存”的生物进化原理相似,遗传算法就是在引入优化参数形成的编码串联群体中,按照所选择的适应度函数并通过遗传中的选择、交叉和变异对个体进行筛选,使适应度好的个体被保留,适应度差的个体被淘汰,新的群体既继承了上一代的信息,又优于上一代。这样反复循环迭代,直至满足条件。
梯度下降(GD)
梯度下降算法可以直观理解成一个下山的方法,将损失函数J(w)比喻成一座山,我们的目标是到达这座山的山脚(即求解出最优模型参数w使得损失函数为最小值)。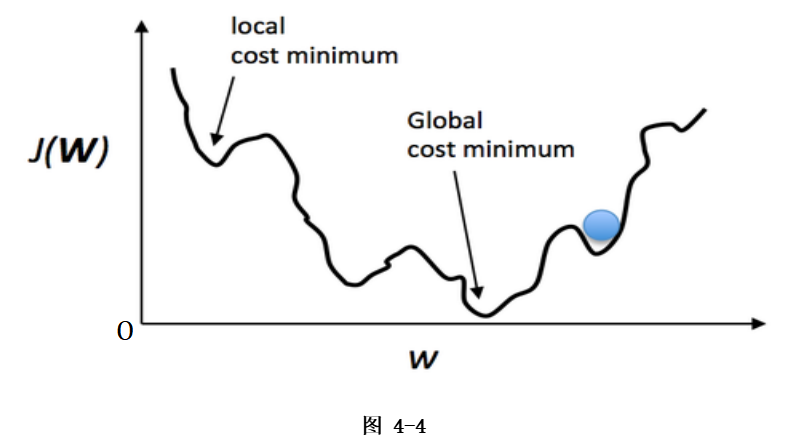
下山要做的无非就是“往下坡的方向走,走一步算一步”,而在损失函数这座山上,每一位置的下坡的方向也就是它的负梯度方向(直白点,也就是山的斜向下的方向)。在每往下走到一个位置的时候,求解当前位置的梯度,向这一步所在位置沿着最陡峭最易下山的位置再走一步。这样一步步地走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不是走到山脚(全局最优,Global cost minimun),而是到了某一个的小山谷(局部最优,Local cost minimun),这也后面梯度下降算法的可进一步调优的地方。对应的算法步骤,直接截我之前的图: 梯度下降是一个大类,常见的梯度下降算法及优缺点,如下图:
梯度下降是一个大类,常见的梯度下降算法及优缺点,如下图: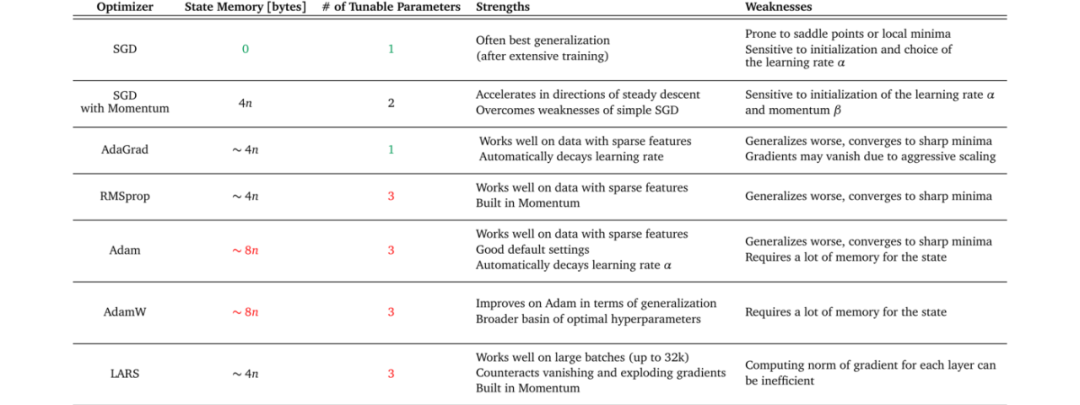
随机梯度下降(SGD)
对于深度学习而言“随机梯度下降, SGD”,其实就是基于小批量(mini-batch)的随机梯度下降,当batchsize为1也就是在线学习优化。
随机梯度下降是在梯度下降算法效率上做了优化,不使用全量样本计算当前的梯度,而是使用小批量(mini-batch)样本来估计梯度,大大提高了效率。原因在于使用更多样本来估计梯度的方法的收益是低于线性的,对于大多数优化算法基于梯度下降,如果每一步中计算梯度的时间大大缩短,则它们会更快收敛。且训练集通常存在冗余,大量样本都对梯度做出了非常相似的贡献。此时基于小批量样本估计梯度的策略也能够计算正确的梯度,但是节省了大量时间。
对于mini-batch的batchsize的选择是为了在内存效率(时间)和内存容量(空间)之间寻找最佳平衡。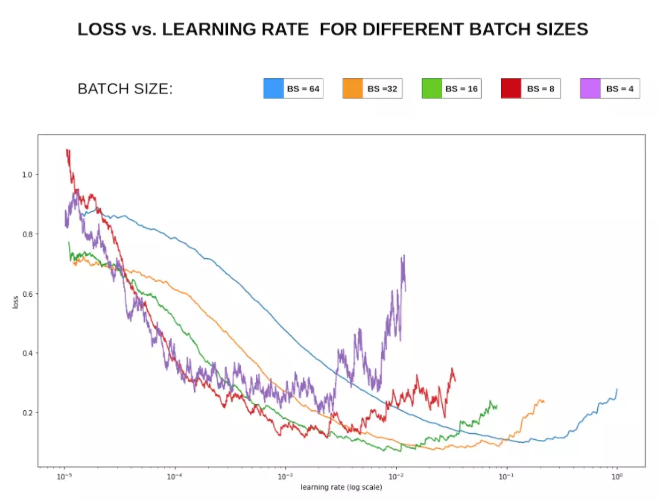
batchsize 不能太大。较大的batch可能会使得训练更快,但可能导致泛化能力下降。更大的batch size 只需要更少的迭代步数就可以使得训练误差收敛,还可以利用大规模数据并行的优势。但是更大的batch size 计算的梯度估计更精确,它带来更小的梯度噪声。此时噪声的力量太小,不足以将参数带出一个尖锐极小值的吸引区域。这种情况需要提高学习率,减小batch size 提高梯度噪声的贡献。
batchsize不能太小。小的batchsize可以提供类似正则化效果的梯度噪声,有更好的泛化能力。但对于多核架构来讲,太小的batch并不会相应地减少计算时间(考虑到多核之间的同步开销)。另外太小batchsize,梯度估计值的方差非常大,因此需要非常小的学习速率以维持稳定性。如果学习速率过大,则导致步长的变化剧烈。
还可以自适应调节batchsize,参见《Small Batch or Large Batch? Peifeng Yin》
Momentum动量算法
Momentum算法在梯度下降中加入了物理中的动量的概念,模拟物体运动时候的惯性,即在更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度对之前的梯度进行微调,这样一来,可以在一定程度上增加稳定性,从而学习的更快,并且有一定的摆脱局部最优的能力。
该算法引入了变量 v 作为参数在参数空间中持续移动的速度向量,速度一般可以设置为负梯度的指数衰减滑动平均值。对于一个给定需要最小化的代价函数,动量可以表达为:更新后的梯度 = 折损系数γ动量项+ 学习率ŋ当前的梯度。
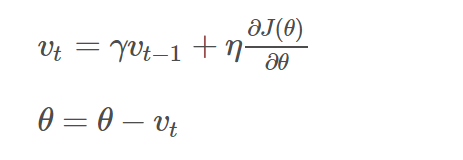
其中 ŋ 为学习率,γ ∈ (0, 1] 为动量系数,v 是速度向量。一般来说,梯度下降算法下降的方向为局部最速的方向(数学上称为最速下降法),它的下降方向在每一个下降点一定与对应等高线的切线垂直,因此这也就导致了 GD 算法的锯齿现象。加入动量法的梯度下降是令梯度直接指向最优解的策略之一。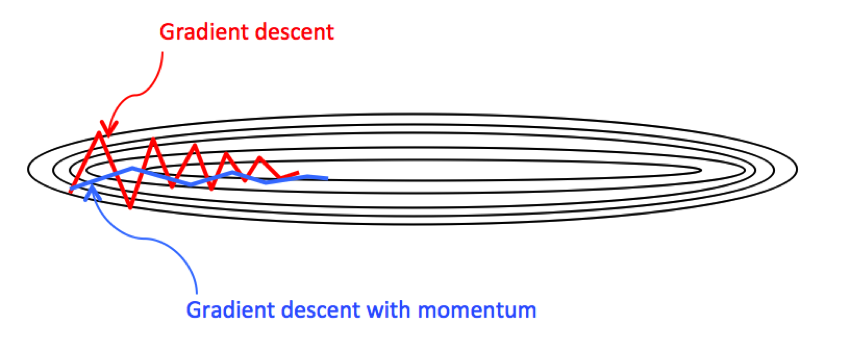
Nesterov
Nesterov动量是动量方法的变种,也称作Nesterov Accelerated Gradient(NAG)。在预测参数下一次的位置之前,我们已有当前的参数和动量项,先用(θ−γvt−1)下一次出现位置的预测值作为参数,虽然不准确,但是大体方向是对的,之后用我们预测到的下一时刻的值来求偏导,让优化器高效的前进并收敛。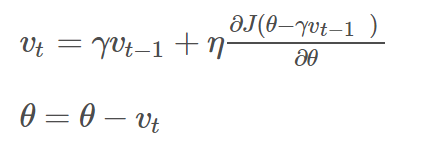
在平滑的凸函数的优化中,对比批量梯度下降,NAG 的收敛速度超出 1/k 到 1/(k^2)
Adagrad
Adagrad 亦称为自适应梯度(adaptive gradient),允许学习率基于参数进行调整,而不需要在学习过程中人为调整学习率。Adagrad 根据不常用的参数进行较大幅度的学习率更新,根据常用的参数进行较小幅度的学习率更新。然而 Adagrad 的最大问题在于,在某些情况,学习率变得太小,学习率单调下降使得网络停止学习过程。
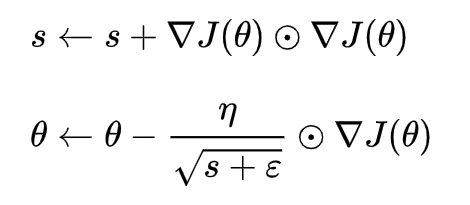
其中是梯度平方的积累量s,在进行参数更新时,学习速率要除以这个积累量的平方根,其中加上一个很小值是ε为了防止除0的出现。由于s 是逐渐增加的,那么学习速率是相对较快地衰减的。
RMSProp
RMSProp 算是对Adagrad算法的改进,主要是解决学习速率过快衰减的问题,它不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数γ 来控制历史信息的获取多少。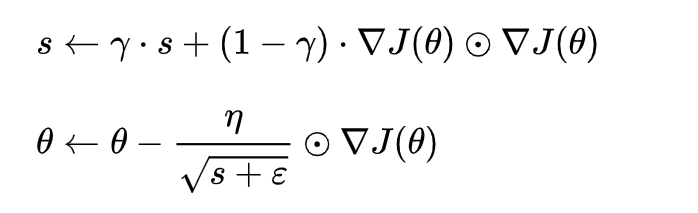
Adam
Adam 算法为两种随机梯度下降的优点集合:
适应性梯度算法(AdaGrad)为每一个参数保留一个学习率以提升在稀疏梯度(即自然语言和计算机视觉问题)上的性能。 均方根传播(RMSProp)基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能。
Adam 算法同时获得了 AdaGrad 和 RMSProp 算法的优点,像RMSprop 一样存储了过去梯度的平方 v的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 m 的指数衰减平均值:
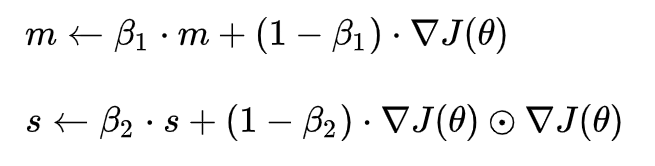
如果 m 和 v被初始化为 0 向量,那它们就会向 0 偏置,所以做了偏差校正放大它们: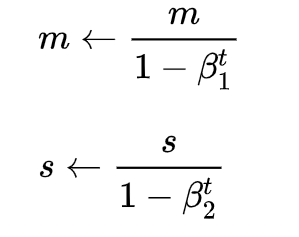
梯度更新能够从梯度均值及梯度平方两个角度进行自适应地调节,而不是直接由当前梯度决定。
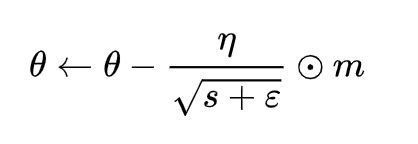
牛顿法
牛顿法和梯度下降法相比,两者都是迭代求解,不过梯度下降法是梯度求解(一阶优化),而牛顿法是用二阶的海森矩阵的逆矩阵求解。相对而言,使用牛顿法收敛更快(迭代更少次数),但是每次迭代的时间比梯度下降法长(计算开销更大,实际常用拟牛顿法替代)。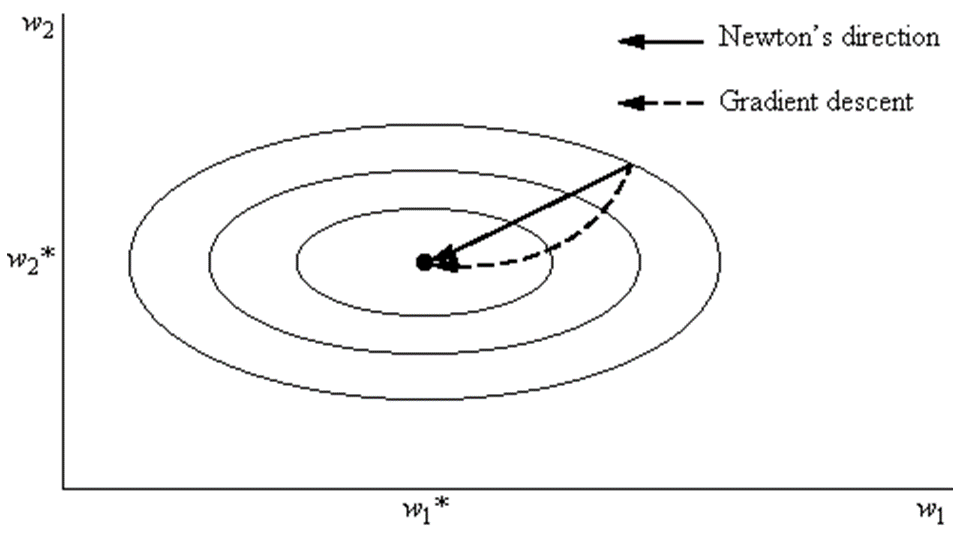
通俗来讲,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,后面坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。但是,牛顿法对初始值有一定要求,在非凸优化问题中(如神经网络训练),牛顿法很容易陷入鞍点(牛顿法步长会越来越小),而梯度下降法则更容易逃离鞍点(因此在神经网络训练中一般使用梯度下降法,高维空间的神经网络中存在大量鞍点)。
综上, 对于神经网络的优化,常用梯度下降等较为高效的方法。梯度下降算法类有SGD、Momentum、Adam等算法可选。对于大多数任务而言,通常可以直接先试下Adam,然后可以继续在具体任务上验证不同优化器效果。
(End)
文章首发公众号“算法进阶”,更多原创文章敬请关注
个人github:https://github.com/aialgorithm
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~