
GPT 的野望

新智元推荐
新智元推荐
来源:安迪的写作间
作者:安迪的写作间

GPT:始于微末,偏居一方
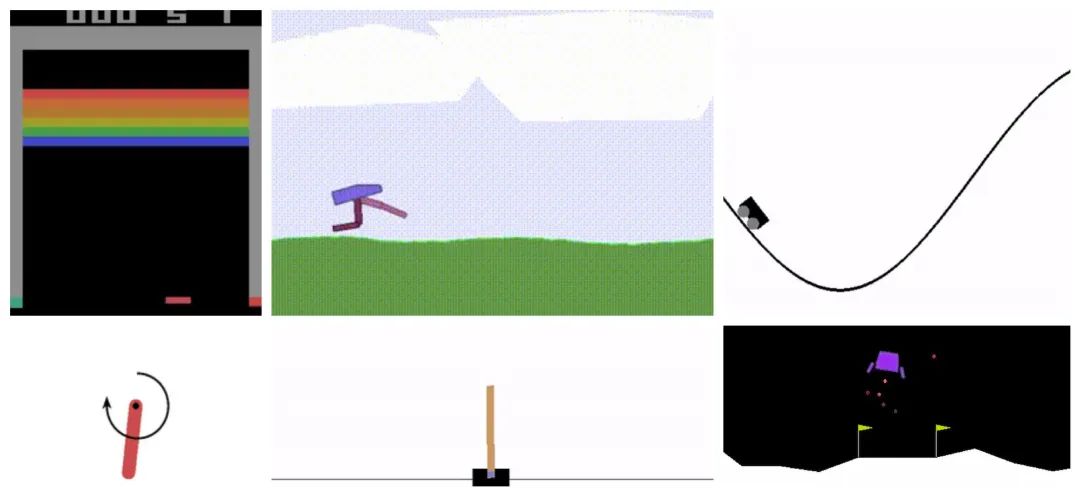




there is significant room for improvement using the well-validated approach of more compute and data. 如果适当的用更多算力和数据的话,还有很大的提升空间。
GPT2:Too Dangerous To Release,一战惊天下

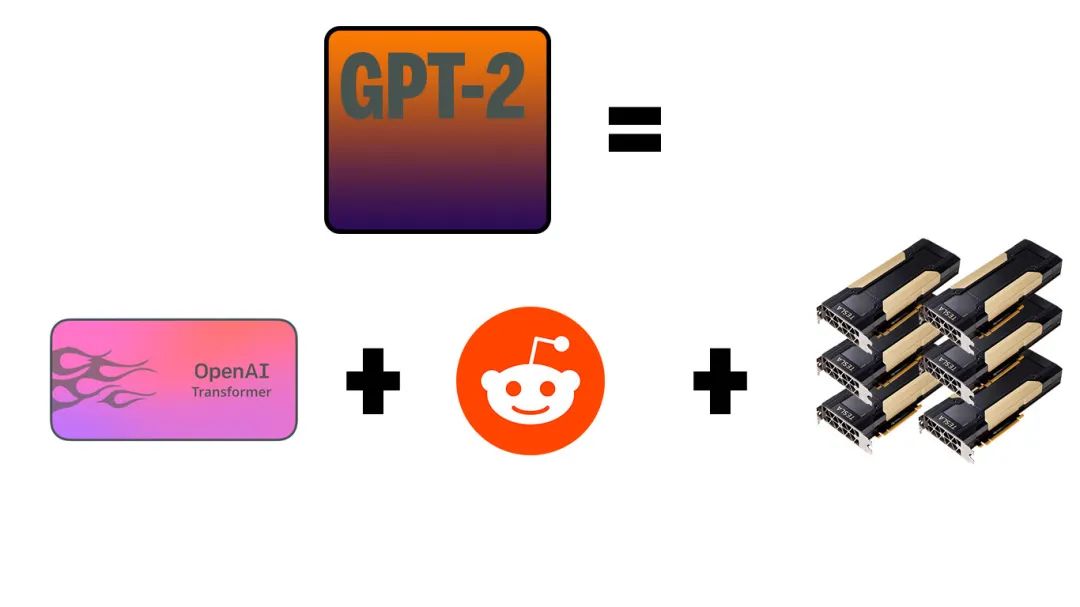



练兵屯粮:OpenAI LP,Sparse Transformer... All For Scaling!
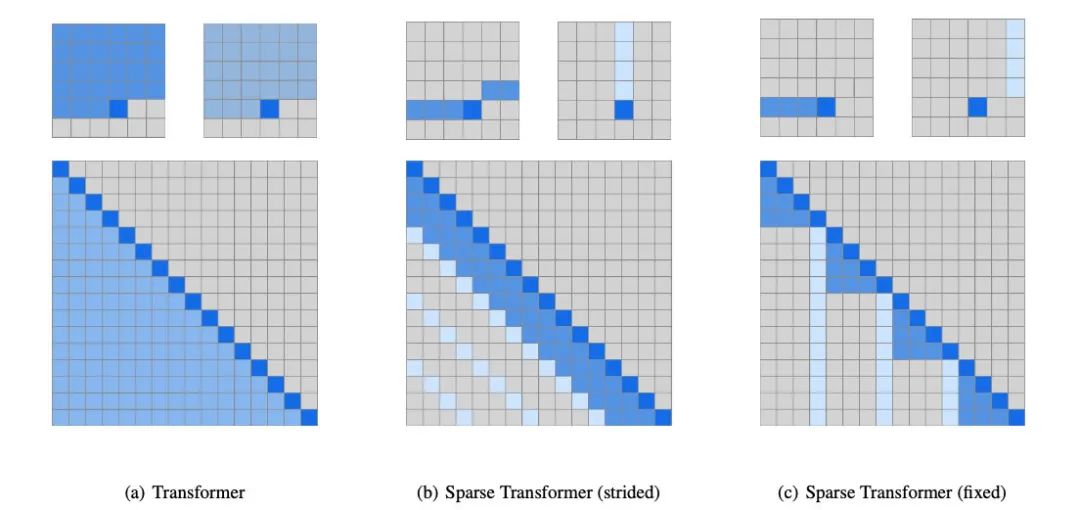
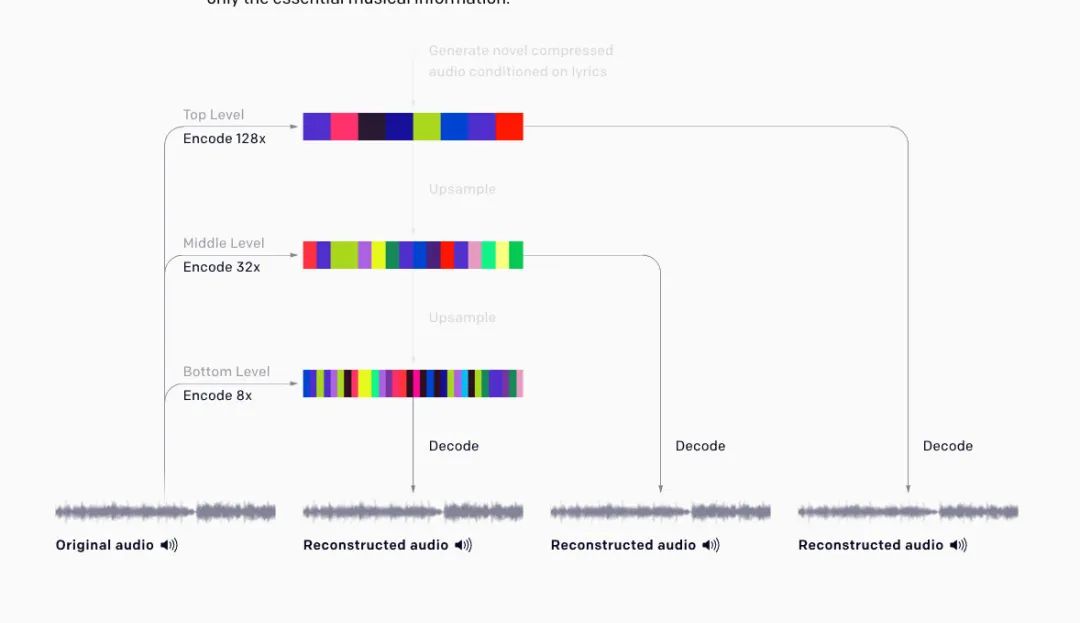
进击:音频之音乐生成


还带有各种元信息,乐器作曲家等,这样就能加入乐器 Token 和作曲家 Token 来让模型分清不同乐器和作曲家风格,之后生成也就更可控。
bach piano_strings start tempo90 piano:v72:G1 piano:v72:G2 piano:v72:B4 piano:v72:D4 violin:v80:G4 piano:v72:G4 piano:v72:B5 piano:v72:D5 wait:12 piano:v0:B5 wait:5 piano:v72:D5 wait:12 piano:v0:D5 wait:4 piano:v0:G1 piano:v0:G2 piano:v0:B4 piano:v0:D4 violin:v0:G4 piano:v0:G4 wait:1 piano:v72:G5 wait:12 piano:v0:G5 wait:5 piano:v72:D5 wait:12 piano:v0:D5 wait:5 piano:v72:B5 wait:12

将 MIDI 输入变成了 32-bit 44.1kHz 的纯音频输入,加入了编码解码方案来将音频 token 化,以及还原
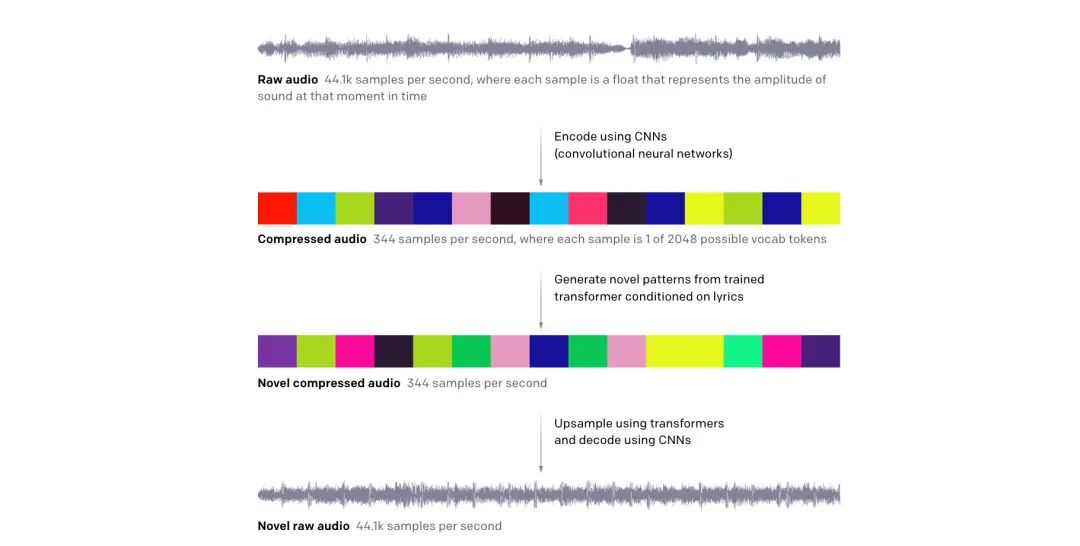
可基于文本(歌词)进行声音的输出
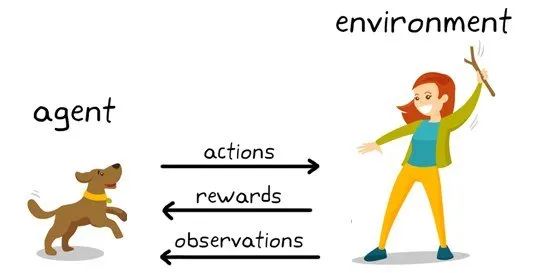
进击:强化学习之加入人反馈的文本生成

最重要的还是在于标注质量的提高,之前出的问题是模型会经常只 copy 片段用于摘要,但这是由于标注导致的。所以这次 OpenAI 吸取教训,不再用众包,直接雇了 80 个标注合约工,不按件计费了,要注重质量。此外,还对每个人进行了详细的面试入职,开发专门的标注界面,还有专门的聊天室来咨询问题,还会一对一打视频电话对... 非常用心了这次,因此才能获得比上次质量高很多的标注。
其次用到了真正意义上的强化学习算法 PPO,而 reward 不再是人直接给了,而是先用上面的高质量标注训练一个好的 reward 模型,之后再用这个 reward 模型来优化生成策略。
整个过程就如下图:

先收集高质量人类标注 再用标注训练 reward 模型 最后用 reward 模型来训练生成策略,进行摘要生成
进击:图像之图像生成





商业化:GPT3 君临
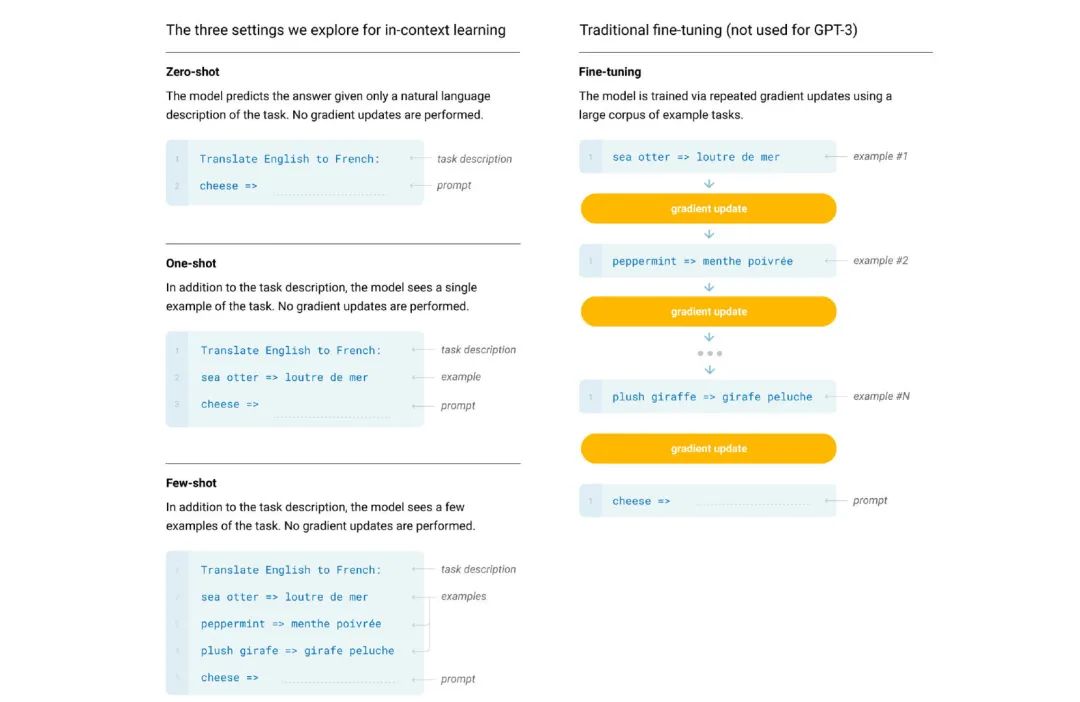
未来

时间线

Reference

评论