
实战:基于深度学习和几何的3D边界框估计
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

3D 对象检测问题在需要决策或与现实世界中的对象交互的机器人应用中尤为重要,3D 对象检测从图像中恢复对象的 6 DoF 姿态和尺寸。虽然最近开发的 2D 检测算法能够处理视点和杂波的较大变化,但准确的 3D 对象检测在很大程度上仍然是一个悬而未决的问题。
文章[1] 提出了一种从单个图像进行 3D 对象检测和姿态估计的方法,他们首先使用深度卷积神经网络回归相对稳定的 3D 对象属性,然后将这些估计与 2D 对象边界框提供的几何约束相结合,以生成完整的 3D 边界框。

给定估计的方向和尺寸以及 3D 边界框的投影,与 2D 检测窗口紧密匹配的约束,它们恢复平移和对象的 3D 边界框。
为了从数学上研究这篇文章,我们需要一个坐标系。坐标系主要有两种,一种是相机坐标系,一种是世界坐标系。
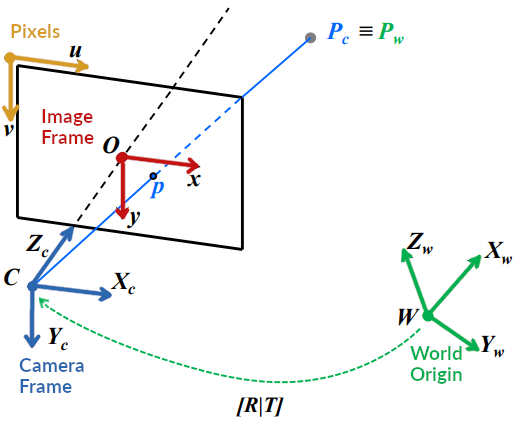
在相机坐标系取摄像机的光学中心作为原点,X轴是水平方向,y轴是垂直方向,以及Z轴指向由照相机观察到的方向。世界坐标系的原点可以任意选择,与相机的具体位置无关。
相机模型中经常涉及到四个坐标系:
图像像素坐标系
成像平面坐标系
相机坐标系
世界坐标系
在环境中选择一个参考坐标系来描述相机和物体的位置,该坐标系称为世界坐标系。相机坐标系和世界坐标系之间的关系可以用旋转矩阵R和平移向量t来描述。假设世界坐标系中P的坐标为(X,Y,Z)_w,则相机坐标系与世界坐标系之间存在如下转换关系:
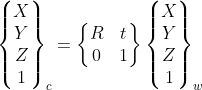
这里使用齐次坐标,R和t代表这两个坐标系之间的变换。
相机坐标系如下图所示:
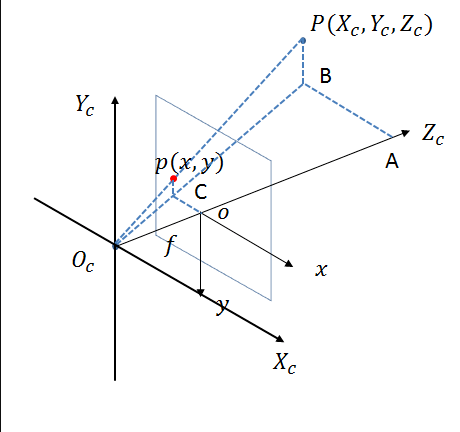
相机坐标系的原点是光心,Xc和Yc轴平行于像素坐标系的u轴和v轴,Zc轴是相机的光轴。从光学中心到像素平面的距离是焦距f。
从图中可以看出,相机坐标系上的点与成像平面坐标系上的点之间存在透视投影关系。假设p对应的相机坐标系中P点的坐标为(Xc,Yc,Zc),则成像平面坐标系与相机坐标系之间存在如下转换关系:
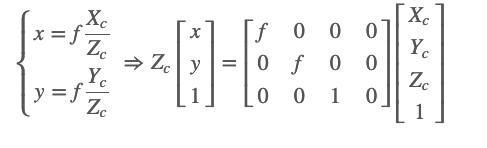
图像像素坐标系通常简称为图像坐标系或像素坐标系,如下所示。
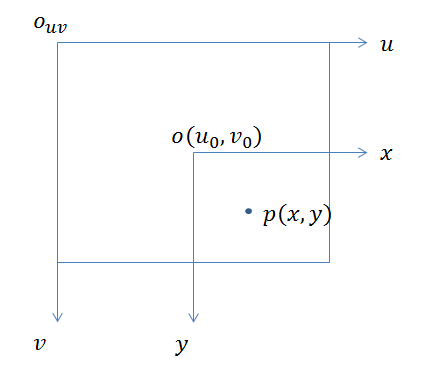
像素坐标系的平面就是相机的成像平面,原点在图像的左上角,u轴在右,v轴在下。像素坐标系的单位是像素,也就是我们常说的分辨率。
成像平面坐标系与像素坐标系在同一平面上,原点为相机光轴与成像平面的交点,通常为成像平面的中点或主点。单位是物理单位,例如毫米。因此,成像平面坐标系和像素坐标系只是原点和测量单位不同,两个坐标系的区别在于缩放比例和原点平移。
假设p对应的成像平面的坐标为(x,y),dx和dy代表成像平面中图像中每个像素的物理尺寸,即上面提到的缩放比例。成像平面原点在像素坐标系中的坐标为(u_0, v_0),那么像素坐标系与成像平面坐标系之间的转换公式如下:
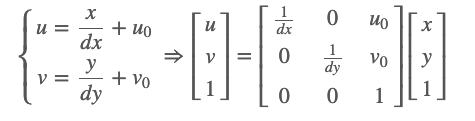
世界坐标系和像素坐标系的转换可以通过以上四个坐标系来实现,如下图:
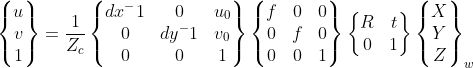
可以写成:
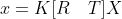
相机的内参矩阵K通常是已知的和固定的,而外参矩阵[R T]往往需要求解。
我们假设 2D 对象检测器已经过训练,可以生成与投影 3D 框的边界框相对应的框。3D 边界框由其中心 T = [t_x, t_y, t_z] 、尺寸 D = [d_x, d_y, d_z] 和方向 R(θ, φ, α) 描述,此处由方位角、仰角和滚转参数化角度。
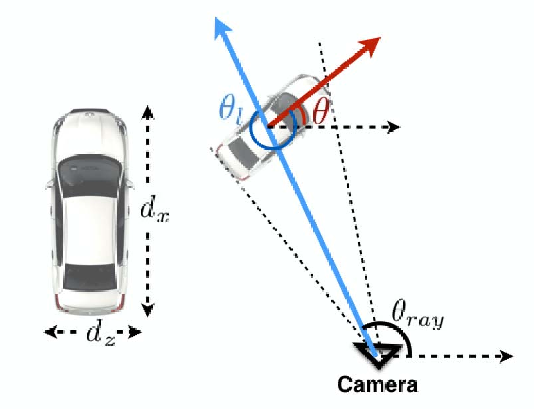
左:汽车尺寸,汽车的高度等于 dy。右图:局部方向 θl 和汽车 θ 的全局方向的图示。局部方向是相对于穿过作物中心的光线计算的。
假设物体坐标系的原点在 3D 边界框的中心,并且物体尺寸 D 已知,那么 3D 边界框顶点的坐标可以简单地描述为
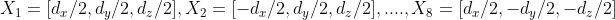
3D 边界框与 2D 检测窗口紧密配合的约束要求 2D 边界框的每一侧都被至少一个 3D 框角的投影所触及。
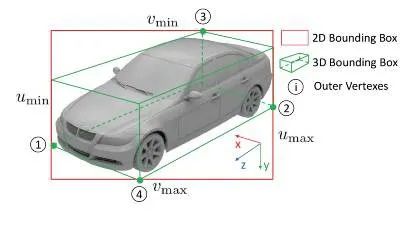
例如,考虑一个 3D 角的投影
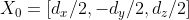
它接触坐标 x_{min} 的 2D 边界框的左侧,这个点对边对应约束导致等式:
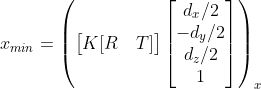
其中 (.)_x 指的是透视投影的 x 坐标,可以为剩余的 2D 盒边参数 x_{max} , y_{min} , y_{max} 推导出类似的方程。
2D 边界框的边总共为 3D 边界框提供了四个约束。第一步,得到一个二维矩形后,利用回归学习估计方位角θ和物体尺寸D=[d_x,d_y,d_z],这里忽略仰角和翻转角(φ=α=0)。直接估计全局方位角θ非常困难,通常选择的是估计物体相对于相机的旋转角的局部角θ_l。
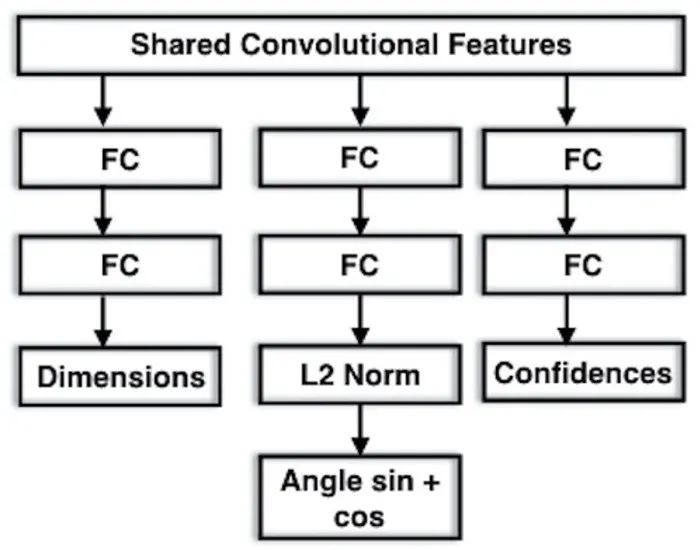
用于方向和维度估计的 MultiBin 估计的建议架构。它由三个分支组成,左分支用于估计感兴趣对象的尺寸,其他分支用于计算每个 bin 的置信度,并计算每个 bin 的 cos(Δθ) 和 sin(Δθ)。
与Faster-RCNN为目标位置设置anchor位置类似,局部角度θ_l的估计也采用离散划分。该方法首先分为n个不同的区间,将预测目标转化为第i个角度区间的概率c_i以及角度偏差cos(Δθ_i)和sin(Δθ_i)的余弦值和正弦值。
在 KITTI 数据集中,车辆大致分为 4 个类别,类别实例的对象维度分布是低方差和单峰的。因此,他们没有使用像上面的 MultiBin 损失那样的离散连续损失,而是直接使用 L2 损失。按照标准,对于每个维度,他们估计相对于在训练数据集上计算的平均参数值的残差。维度估计的损失 L_{dims} 计算如下:
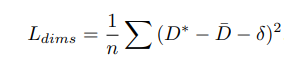
其中 D* 是基准大小,D¯ 是某个类别对象的平均维度,δ 是相对于网络预测的均值的估计残差。
使用 CNN 和 2D 检测框的 3D 框的回归尺寸和方向,我们可以求解平移 T,从而最小化相对于初始 2D 检测框约束的重投影误差。2D 检测框的每一边可以对应于 3D 框的八个角中的任何一个,这导致 8^4 = 4096 个配置,每种不同的配置都涉及求解一个过约束的线性方程组,该系统计算速度快,可以并行完成。
他们在具有挑战性的 KITTI 对象检测基准上评估了他们的方法,包括 3D 方向估计的官方度量以及获得的 3D 边界框的准确性。尽管概念上很简单,但所提出的方法优于利用语义分割、实例级分割和平坦先验和子类别检测的更复杂且计算成本高的方法。
1.Arsalan Mousavian,Dragomir Anguelov,John Flynn.3D Bounding Box Estimation Using Deep Learning and Geometry
2.Peiliang Li, Tong Qin, Shaojie Shen .Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~