
你所要知道的音视频--02
共 2138字,需浏览 5分钟
·
2022-02-09 17:34

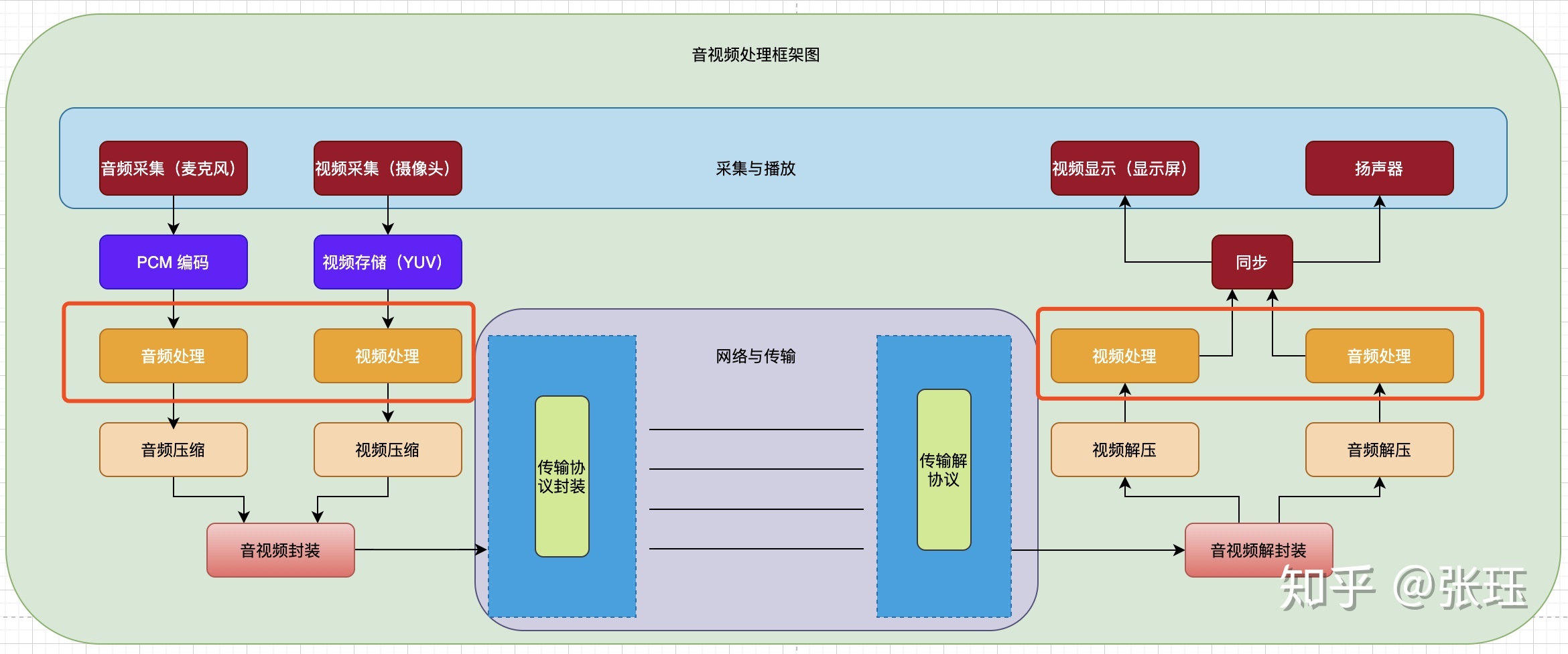
上一期我们主要介绍了音视频的采集与播放。对于采集到的原始音视频,或者准备播放的原始音视频,一般来说我们还可以做一定的处理。目前AI对于音视频领域的研究也是主要集中在这一块。本文主要介绍常用的音视频处理方案,以及常见的一些开源库,并穿插着介绍一些作者曾经做过的,或者是研究过的应用场景。
概论
在软件处理中,音视频的处理算法的原始数据,都是以数字化的数据为主的。一般都是处在采集之后、压缩之前(采集发送端),或者解压之后,播放之前(接收播放端)。开发者可以根据这里的软件特色,选择其中的一端或者两端进行处理。
音频的处理
常见的音频处理有:混音,变音,3A算法,DTMF,语音识别,AI去噪算法等。
混音
其实就是是把多种来源的声音,整合至一个立体音轨或单音音轨中。在软件算法中的操作一般分为:音频切片、音频数据叠加、音频数据归一化。其中,叠加的时候一定要主要不要出现数据越界了。
变音
由于声音存在可识别性,为了做一些隐私保护,变音就显得十分重要了。变音也包括改变响度、音调、音色三类。
变调:声音可以理解为多种频率正弦波的叠加,而音调就是一段声音的主要频率。改变了主要频率,就是改变了音调,其中提高了主要频率,就是升调,反之亦然。变调算法中又有变速变调,不变速变调算法。具体的可以参考这篇文章:
变速变调原理与方法总结 - WELEN - 博客园音色:关于音色的算法就有很多了,其算法原理都是通过改变基频与泛音的关系来实现的。具体可以参看:
变声总结(声音概念、采集、变声、SoundTouch 和 FMOD 对比等)SoundTouch Sound Processing Library3A算法
第一次系统的接触3A算法是来自于WebRTC,3A算法分别为:回声消除,噪声抑制,音频增益。

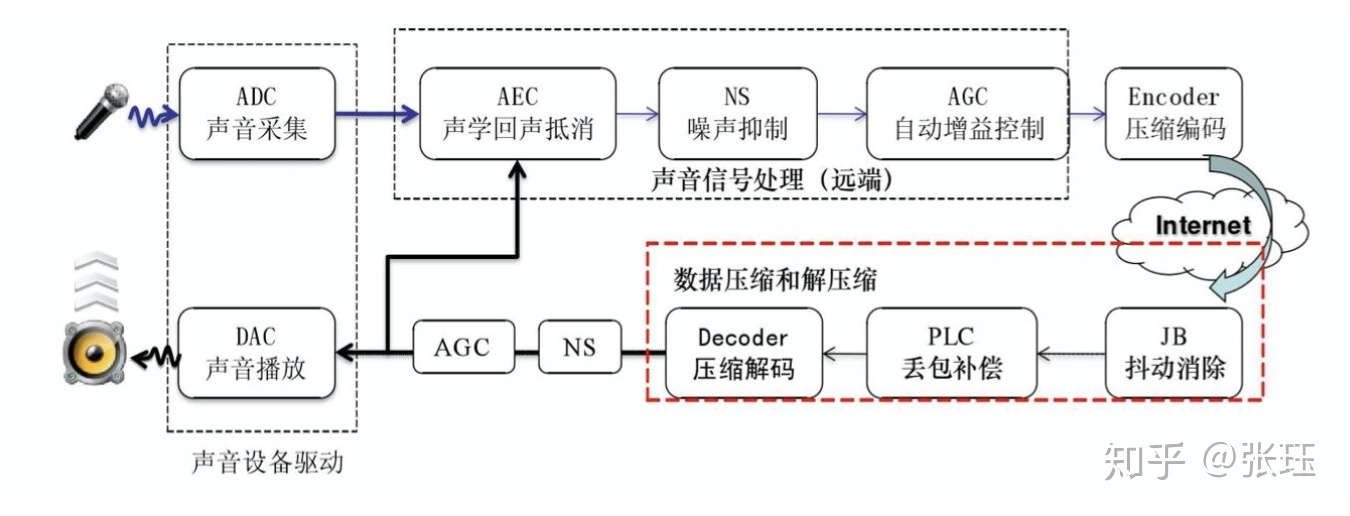
回声消除:
声学回声消除(Acoustic Echo Cancellation)原理与实现,一般大家主要关注其中的间接回声消除。
噪声抑制:核心是噪声估计与噪声消除,最核心的是噪声估计算法。有兴趣的可以拜读相关文献。这里列举一个博客
WebRTC之noise suppression算法音频增益:可以理解成放大声音,我看WebRTC中主要是根据音频数据直方图进行放大处理。
此外还有静音检测,双讲吞音问题等。
DTMF
双音多频DTMF(Dual Tone Multi Frequency),高低频群各包含4个频率。一个高频信号和一个低频信号叠加组成一个组合信号,代表一个数字。DTMF信号有16个编码。分别代表0-9、*、#、A、B、C、D,是传统电话中的主要的输入控制方式,电话中的拨号音也是该原理。
当初还有一个故事,某位大学生通过媒体拨号给周鸿祎的拨号音,通过软件处理得到了周鸿祎的电话号码,从而与周鸿祎取得了联系。相信有这个故事为铺垫,以后采访大佬的电话声音至少会做一定的变音处理了吧!
在WebRTC中,发送DTMF信号有单独的DTMF Sender负责,如果是SIP通话机制,有两种方案可以实现DTMF,一个是DTMF Sender,一个是发送SIP INFO包,但一般都选择前者。用Wireshark抓到语音包的时候可以发现,其中的DTMF是包含了5个RTP包的。
语音识别与AI去噪
这一块我研究的不多,知名的公司有科大讯飞,知名的开源软件有:RNNoise
RNNoise Git视频的处理
首先,视频是由一幅幅的图像帧构成的,所以所以的图像处理都能在视频处理中被应用,另外视频还有其自己独特的和时间序列相关的处理方式。
视频的处理非常多,这里只列举笔者接触过的一些方案:FFmpeg和OpenCV是两个非常好的开源库。其中OpenCV主要集中在图像处理中。其中包含了,各种图像处理的算法,人脸检测算法等。图像处理的算法非常多,建议大家有兴趣的话,可以去看一下OpenCV3.0版本之后的书籍。
和用户相关的视频处理算法主要有:图像分类、车牌识别、人脸识别(大火)、步态识别、图像水印(这个算法就非常多了)、图像融合、图像去噪(图像的噪声也分为很多种)、图像美化、图像趣玩(加头像啊之类的)。具体算法需要具体的研究。
图像质量评估(Image Quality Assessment, IQA)
图像质量评估分为:主观评价,客观评价,其中客观评价又分为有参考评价,无参考评价。
这里有一位之前的美图小哥的文章讲的挺不错的: 图像质量评估
视频质量评估(Video Quality Assessment, VQA)
视频质量评估目前还主要是借鉴图像质量评估为主,我研究的不多。援引wiki 百科的简单解释吧。
张珏:后话
图像处理是一门非常有意思的技术,我本硕期间玩的挺多的,有很多可以玩的方向。新手可以用matlab刷刷传统算法,如去噪、融合、增强、边缘检测、水印算法、CT图像的处理、小波变换等等。
进阶的话,可以用OpenCV系统的玩一遍各种算法,然后接触一下人脸识别,车牌识别,前景检测等等,现在OpenCV也集成了很多AI算法,也可以玩玩。
再次进阶的话,就可以玩玩FFmpeg了,这一块目前我玩的不多,也才开始。就不班门弄斧了。
另外,未来我非常看好音视频领域的发展!
更多有趣的内容,欢迎关注我的个人公众号:《穷人的思考》