
你所要知道的音视频--01
共 3098字,需浏览 7分钟
·
2022-02-09 17:34

每天躺尸的生活,让我深感无聊,于是突发奇想,打算把自己工作一年多来,对于音视频领域的了解,做一个系统的总结。会以系列博客的形式不断更新。
本人从事的是实时音视频软件开发,目前主要工作集中在Phone模块以及监控系统的搭建。但是本系列的文章会涉及到视频相关部分。由于我的主要工作不在视频,所以主要总结的是自己私下学习的部分,该部分内容会请教一些大牛,但由于管中窥豹,必然会有很多不到位地方。望各位读者见谅,各位大神多多指点。
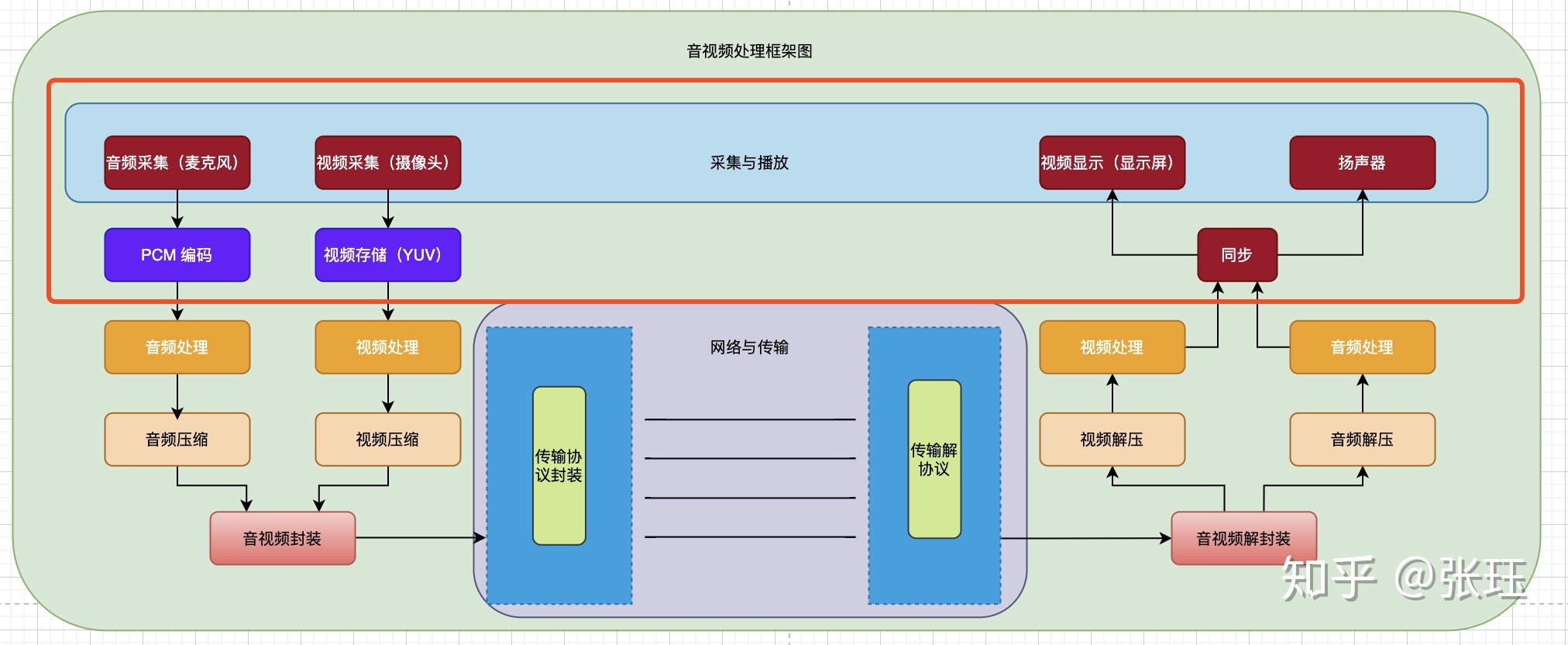
音视频的采集与播放
音视频的采集与存储
今天总结的内容,主要集中在音视频的采集与播放部分,大部分从事音视频软件开发的人员,实际工作较少涉及这一部分。一般是硬件开发商,驱动软件开发人员涉及该部分较多。由于我是一个纯软件开发从业者,因此我对这方面的总结会相对偏理论一些。
首先看看音视频涉及的硬件设备
音频采集设备:麦克风录制,软件处理生成。
视频采集设备:摄像头录制,屏幕录制,软件处理生成。
音频播放设备:内置播放器(手机),扬声器,耳机,蓝牙,音响,车载蓝牙等。
视频播放器:屏幕显示器,投影仪。
音频采集设备采集到的音频是由一个个正余弦信号组成的音频信号,为了将其转换为可以被计算机所处理的数字信号,首先需要对其进行PCM编码。
为了保证音频能够被重构,必须遵从奈奎斯特抽样(采样)定理,即采样频率必须大于声音带宽的两倍。一般来时,采样率越高,声音的保真度越高,但所采集到的数据量也越大。

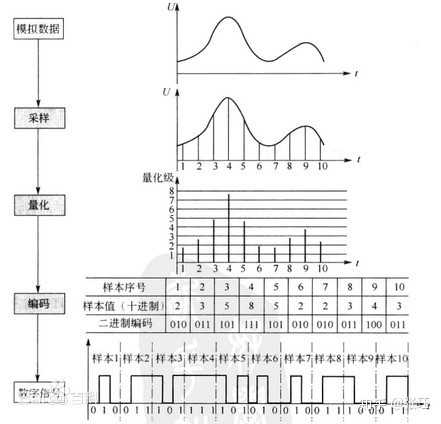
另外,我们还需要对每一个采样点进行量化编码保存,量化所采用的位数越多(8位编码,或者16位编码),才对于单个采样点的分辨率则越高,声音的保真度也越高,当然,代价就是存储的数据量也越大。
音频是有声道一说的,常见的有单声道以及立体声(左右声道),环绕立体声等。一般网络电话采用单声道,音乐播放至少是双声道。声道越多,所需要的数据量越大。
视频,其实是由一幅幅的图片按顺序播放所组成的。每一张按序播放的图片称作视频帧,每秒播放的视频帧数称作帧率,一般帧率越高,画面的连续度越好。当你操作屏幕,或者视频切换的时候的连续度越强。
由于图片是一个平面的,因此有高和宽。对于显示器来说,它其实是一个个像素点组成的平面,我们常用像素点的数量来说明分辨率。比如1920×1080,就代表x轴有1920个像素点,y轴有1080个像素点(本质其实是显示时候的扫描行数)。有兴趣的可以了解一下1080P,1080i的区分和历史。由于视频有宽和高,所以还有有一个宽高比的概念。
那么视频的像素点为什么会有颜色呢?一般我们将电视分为黑白电视,和彩色电视。对于黑白电视,单个像素点只有一个颜色分量,代表亮和暗。而对于彩色电视,单个像素点背后有三个颜色分量,分别代码,R(红色),G(绿色),B(蓝色)三原色。三原色按照不同比例混合就可以显示各种各样的颜色。既然这里采用的是RGB颜色空间,那为什么上图中又提到YUV颜色空间呢?
YUV颜色空间由亮度信号Y和两个色差信号R-Y(即U)、B-Y(即V)组成,由于人眼对于亮度的敏感度高于颜色的敏感度,YUV空间便于我们减少用于存储UV的分量空间,从而提高压缩率。另外一点就是,也利于兼容以前的黑白电视的显示。
换算公式:
Y = 0.299R + 0.587G + 0.114B
U = -0.147R - 0.289G + 0.436B
V = 0.615R - 0.515G - 0.100B
R = Y + 1.14V
G = Y - 0.39U - 0.58V
B = Y + 2.03U视频和音频的播放
这边最最最重要的就是音视频同步了!由于音视频拥有自己独立的轨道(Track),经过了编解码,采集,存储、或者网络传输,等过程,播放的时候可能存在不同步的问题。为了一个更好的体验,播放器必须解决音视频同步的问题。
音视频采集的数据分别来自于麦克风与摄像头,而摄像头与麦克风其实是两个独立的硬件,而音视频同步的原理是相信摄像头与麦克风采集数据是实时的,并在采集到数据时给他们一个时间戳来标明数据所属的时间,而编码封装模块只要不改动音视频时间的相对关系就能保证音频与视频在时间上的对应。如此封装好数据之后,播放端就能够根据音视频的时间戳来播放对应的音视频,从实现音视频同步的效果。
首先,要想做到音视频同步,在采集的时候就需要保证时间线上的一致。一般来说我们需要对音视频的数据包打上一个时间戳,但这个时间戳首先就需要同步。对于音视频都是用同一台设备采集的,我们可以直接使用系统自己的时间系统进行同步就可以,对于不同设备采集的音视频,就需要依赖外部同步设备,或者人工介入调整了。
我没有深入过这方面的研究,但直观猜测过去最好的办法应该是:采用软件采集的时候,根据开启设备的时间,以及设备采集的速率,通过软件直接封装时间戳。
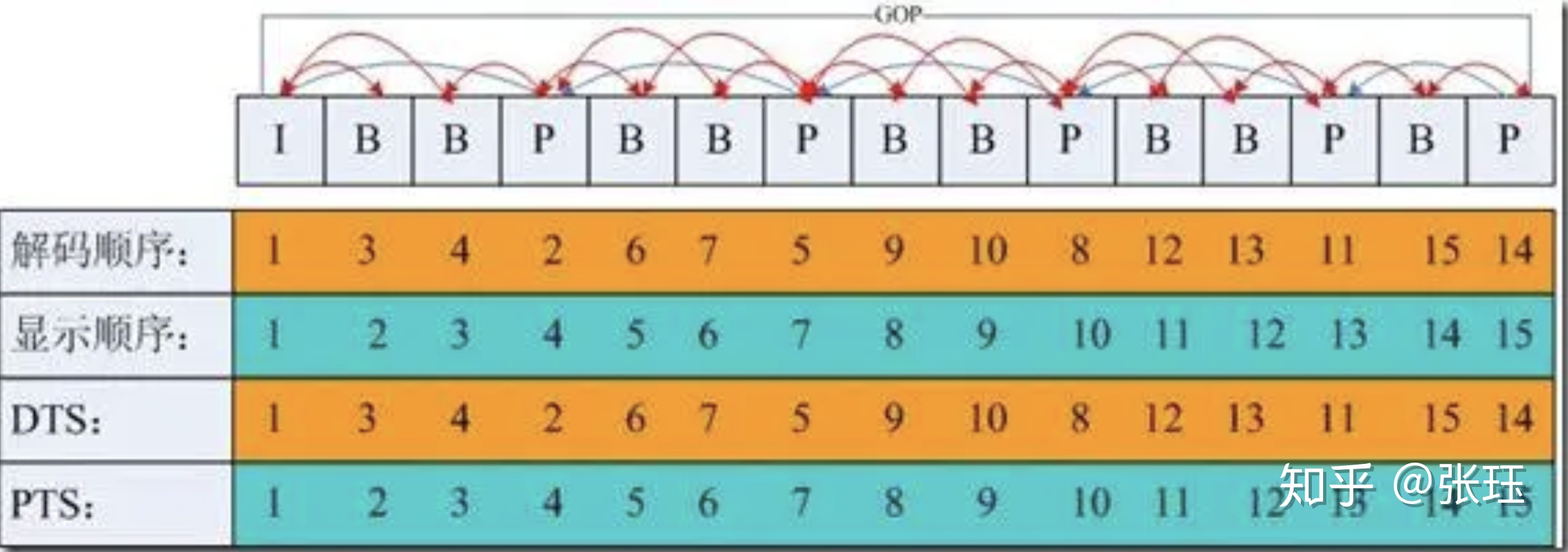
对于FFmpeg中H264编码中的视频帧,有两个很重要的时间戳DTS和PTS。
DTS:Decoding Time Stamp 解码时间戳——告诉解码器packet解码顺序
PTS:Presenting Time Stamp 显示时间戳——从packet中解码出来的数据的显示顺序
为什么需要这两个概念呢?这是因为视频的编码,不仅有帧内编码,还有帧间运动补偿编码。
帧内编码方式,即只利用了单帧图像内的空间相关性,对冗余数据进行编码,达到压缩效果,单靠自身,便能完整解码出一帧画面。
帧间编码,由于视频的特性,相邻的帧之间其实是很相似的,通常是运动矢量的变化。利用其时间相关性,可以通过参考帧运动矢量的变化来预测图像,并结合预测图像与原始图像的差分,便能解码出原始图像。
在H264中有I,P,B帧的概念,分别如下:
- I 帧(Intra coded frames):
I 帧图像采用帧I 帧使用帧内压缩,不使用运动补偿,由于 I 帧不依赖其它帧,可以独立解码。I 帧图像的压缩倍数相对较低,周期性出现在图像序列中的,出现频率可由编码器选择。
- P 帧(Predicted frames):
P 帧采用帧间编码方式,即同时利用了空间和时间上的相关性。P 帧图像只采用前向时间预测,可以提高压缩效率和图像质量。P 帧图像中可以包含帧内编码的部分,即 P 帧中的每一个宏块可以是前向预测,也可以是帧内编码。
- B 帧(Bi-directional predicted frames):
B 帧图像采用帧间编码方式,且采用双向时间预测,可以大大提高压缩倍数。也就是其在时间相关性上,还依赖后面的视频帧,也正是由于 B 帧图像采用了后面的帧作为参考,因此造成视频帧的传输顺序和显示顺序是不同的。

基于时间戳的音视频播放过程中,音视频的播放不一定是横速一致的。因此我们还需要引入一个反馈机制,也就是要将当前数据流速度太快或太慢的状态反馈给源,让源去放慢或加快数据流的速度,从而持续保证播放的同步性。一般人们对于音频的敏感度高于视频,视频放快一点,可能察觉的不是特别明显,但音频加快或减慢,人耳听的很敏感。因此对于音视频同步一般有三个策略。
1: 以音频为基准,同步视频到音频(ffpaly 默认的方式)
- 视频慢了则加快播放或丢掉部分视频帧
- 视频快了则延迟播放
2: 以视频为基准,同步音频到视频
- 音频慢了就加快音频的播放速度,或者直接丢掉一部分音频帧
- 音频快了就放慢音频的播放速度
3: 以外部时钟为准,同步音频和视频到外部时钟
- 根据外部时钟改版音频和视频的播放速度
同步处理完之后,音视频便被送往对应的硬件设备进行播放,这一步,只要你的设备正常,一般就没有啥坑了。
更多有趣的内容,欢迎关注我的个人公众号:《穷人的思考》