
深度学习&计算机视觉常见的29道面试题及解析

极市导读
正值秋招进行时,本文收集了深度学习&计算机视觉方向的相关面试题,涵盖反卷积、神经网络、目标检测等多个方面,内容非常全面。
1.什么是反卷积?
反卷积也称为转置卷积,如果用矩阵乘法实现卷积操作,将卷积核平铺为矩阵,则转置卷积在正向计算时左乘这个矩阵的转置WT,在反向传播时左乘W,与卷积操作刚好相反,需要注意的是,反卷积不是卷积的逆运算。
一般的卷积运算可以看成是一个其中非零元素为权重的稀疏矩阵C与输入的图像进行矩阵相乘,反向传播时的运算实质为C的转置与loss对输出y的导数矩阵的矩阵相乘。
逆卷积的运算过程与卷积正好相反,是正向传播时做成C的转置,反向传播时左乘C
2.反卷积有哪些用途?
实现上采样;近似重构输入图像,卷积层可视化。
3.解释神经网络的万能逼近定理
只要激活函数选择得当,神经元的数量足够,至少有一个隐含层的神经网络可以逼近闭区间上任意一个连续函数到任意指定的精度。
4.神经网络是生成模型还是判别模型?
判别模型,直接输出类别标签,或者输出类后验概率p(y|x)
5.Batch Normalization 和 Group Normalization有何区别?
BN是在 batch这个维度上进行归一化,GN是计算channel方向每个group的均值方差.
6.模型压缩的主要方法有哪些?
从模型结构上优化:模型剪枝、模型蒸馏、automl直接学习出简单的结构
模型参数量化将FP32的数值精度量化到FP16、INT8、二值网络、三值网络等。
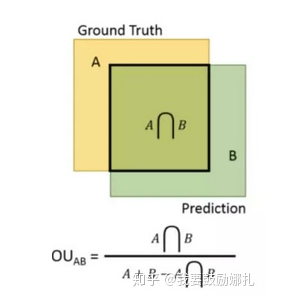
7.目标检测中IOU是如何计算的?
检测结果与 Ground Truth 的交集比上它们的并集,即为检测的准确率 IoU
8.使用深度卷积网络做图像分类如果训练一个拥有1000万个类的模型会碰到什么问题?
提示:内存/显存占用;模型收敛速度等
9.深度学习中为什么不用二阶导去优化?
Hessian矩阵是n*n, 在高维情况下这个矩阵非常大,计算和存储都是问题。
10.深度机器学习中的mini-batch的大小对学习效果有何影响?
mini-batch太小会导致收敛变慢,太大容易陷入sharp minima,泛化性不好。
11.dropout的原理
可以把dropout看成是 一种ensemble方法,每次做完dropout相当于从原网络中找到一个更瘦的网络。
强迫神经元和其他随机挑选出来的神经元共同工作,减弱了神经元节点间的联合适应性,增强泛化能力
使用dropout得到更多的局部簇,同等数据下,簇变多了,因而区分性变大,稀疏性也更大
12.为什么SSD对小目标检测效果不好:
小目标对应的anchor比较少,其对应的feature map上的pixel难以得到训练,这也是为什么SSD在augmentation之后精确度上涨(因为crop之后小目标就变为大目标)
要检测小目标需要足够大的feature map来提供精确特征,同时也需要足够的语义信息来与背景作区分
13.空洞卷积及其优缺点
pooling操作虽然能增大感受野,但是会丢失一些信息。空洞卷积在卷积核中插入权重为0的值,因此每次卷积中会skip掉一些像素点;
空洞卷积增大了卷积输出每个点的感受野,并且不像pooling会丢失信息,在图像需要全局信息或者需要较长sequence依赖的语音序列问题上有着较广泛的应用。
14.Fast RCNN中位置损失为何使用Smooth L1:
表达式为:

作者这样设置的目的是想让loss对于离群点更加鲁棒,相比于L2损失函数,其对离群点、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。
15.Batch Normalization
使用BN的原因是网络训练中每一层不断改变的参数会导致后续每一层输入的分布发生变化,而学习的过程又要使每一层去适应输入的分布,因此不得不降低网络的学习率,并且要小心得初始化(internal covariant shift)
如果仅通过归一化方法使得数据具有零均值和单位方差,则会降低层的表达能力(如使用Sigmoid函数时,只使用线性区域)
BN的具体过程(注意第三个公式中分母要加上epsilon)

注意点:在测试过程中使用的均值和方差已经不是某一个batch的了,而是针对整个数据集而言。因此,在训练过程中除了正常的前向传播和反向求导之外,我们还要记录每一个Batch的均值和方差,以便训练完成之后按照下式计算整体的均值和方差。
另一个注意点:在arxiv六月份的preprint论文中,有一篇叫做“How Does Batch Normalization Help Optimization?”的文章,里面提到BN起作用的真正原因和改变输入的分布从而产生稳定性几乎没有什么关系,真正的原因是BN使对应优化问题的landscape变得更加平稳,这就保证了更加predictive的梯度以及可以使用更加大的学习率从而使网络更快收敛,而且不止BN可以产生这种影响,许多正则化技巧都有这种类似影响。
16.超参数搜索方法
网格搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。
贝叶斯优化:贝叶斯优化其实就是在函数方程不知的情况下根据已有的采样点预估函数最大值的一个算法。该算法假设函数符合高斯过程(GP)。
随机搜索:已经发现,简单地对参数设置进行固定次数的随机搜索,比在穷举搜索中的高维空间更有效。这是因为事实证明,一些超参数不通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。具体方法:核函数,如:高斯核,多项式核等等。
基于梯度:计算相对于超参数的梯度,然后使用梯度下降优化超参数。
17.如何理解卷积、池化等、全连接层等操作
卷积的作用:捕获图像相邻像素的依赖性;起到类似滤波器的作用,得到不同形态的feature map
激活函数的作用:引入非线性因素
池化的作用:减少特征维度大小,使特征更加可控;减少参数个数,从而控制过拟合程度;增加网络对略微变换后的图像的鲁棒性;达到一种尺度不变性,即无论物体在图像中哪个方位均可以被检测到
18.1x1大小的卷积核的作用
通过控制卷积核个数实现升维或者降维,从而减少模型参数
对不同特征进行归一化操作
用于不同channel上特征的融合
19.常见激活函数特点
sigmoid:输入值很大时对应的函数值接近1或0,处于函数的饱和区,导致梯度几乎为0,造成梯度消失问题
Relu:解决梯度消失问题,但是会出现dying relu现象,即训练过程中,有些神经元实际上已经"死亡“而不再输出任何数值
Leaky Relu:f = max(αx, x),解决dying relu问题,α的取值较大时比较小时的效果更好。它有一个衍生函数,parametric Leaky Relu,在该函数中α是需要去学习的
ELU:避免dying神经元,并且处处连续,从而加速SGD,但是计算比较复杂
激活函数的选择顺序:ELU>Leaky Relu及其变体>Relu>tanh>sigmoid
20.训练过程中,若一个模型不收敛,那么是否说明这个模型无效?导致模型不收敛的原因有哪些?
并不能说明这个模型无效,导致模型不收敛的原因可能有数据分类的标注不准确;样本的信息量太大导致模型不足以fit整个样本空间;
学习率设置的太大容易产生震荡,太小会导致不收敛;可能复杂的分类任务用了简单的模型;数据没有进行归一化的操作。
21.深度学习中的不同最优化方式,如SGD,ADAM下列说法中正确的是?
A.在实际场景下,应尽量使用ADAM,避免使用SGD
B.同样的初始学习率情况下,ADAM的收敛速度总是快于SGD方法
C.相同超参数数量情况下,比起自适应的学习率调整方式,SGD加手动调节通常会取得更好效果
D.同样的初始学习率情况下,ADAM比SGD容易过拟合
S: C
22.深度学习:凸与非凸的区别
凸:
指的是顺着梯度方向走到底就一定是最优解 。
大部分传统机器学习问题都是凸的。
非凸:
指的是顺着梯度方向走到底只能保证是局部最优,不能保证是全局最优。
深度学习以及小部分传统机器学习问题都是非凸的。
23.googlenet提出的Inception结构优势有()
A.保证每一层的感受野不变,网络深度加深,使得网络的精度更高
B.使得每一层的感受野增大,学习小特征的能力变大
C.有效提取高层语义信息,且对高层语义进行加工,有效提高网络准确度
D.利用该结构有效减轻网络的权重
S:AD.
24.深度学习中的激活函数需要具有哪些属性?()
A.计算简单
B.非线性
C.具有饱和区
D.几乎处处可微
S: ABC
relu函数在0处是不可微的。
25.关于神经网络中经典使用的优化器,以下说法正确的是
A.Adam的收敛速度比RMSprop慢
B.相比于SGD或RMSprop等优化器,Adam的收敛效果是最好的
C.对于轻量级神经网络,使用Adam比使用RMSprop更合适
D.相比于Adam或RMSprop等优化器,SGD的收敛效果是最好的
S: D
SGD通常训练时间更长,容易陷入鞍点,但是在好的初始化和学习率调度方案的情况下,结果更可靠。如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
26.以下说法错误的是
A.使用ReLU做为激活函数,可有效地防止梯度爆炸
B.使用Sigmoid做为激活函数,较容易出现梯度消失
C.使用Batch Normalization层,可有效的防止梯度爆炸
D.使用参数weight decay,在一程度上可防止模型过拟合
S: C
意思是BN解决的是梯度消失问题?对结果存疑。认为二者皆可防止。
27.以下哪种方法一般不用于在大数据集上训练DNN:
A.SGD B.FTRL C.RMSProp D.L-BFGS
S: D
L-BFGS(Limited-memory BFGS,内存受限拟牛顿法)方法:所有的数据都会参与训练,算法融入方差归一化和均值归一化。大数据集训练DNN,容易参数量过大 (牛顿法的进化版本,寻找更好的优化方向,减少迭代轮数)从LBFGS算法的流程来看,其整个的核心的就是如何快速计算一个Hesse的近似:重点一是近似,所以有了LBFGS算法中使用前m个近似下降方向进行迭代的计算过程;重点二是快速,这个体现在不用保存Hesse矩阵上,只需要使用一个保存后的一阶导数序列就可以完成,因此不需要大量的存储,从而节省了计算资源;重点三,是在推导中使用秩二校正构造了一个正定矩阵,即便这个矩阵不是最优的下降方向,但至少可以保证函数下降。
FTRL(Follow-the-regularized-Leader)是一种适用于处理超大规模数据的,含大量稀疏特征的在线学习的常见优化算法,方便实用,而且效果很好,常用于更新在线的CTR预估模型;FTRL在处理带非光滑正则项(如L1正则)的凸优化问题上表现非常出色,不仅可以通过L1正则控制模型的稀疏度,而且收敛速度快;
28.下列关于深度学习说法错误的是
A.LSTM在一定程度上解决了传统RNN梯度消失或梯度爆炸的问题
B.CNN相比于全连接的优势之一是模型复杂度低,缓解过拟合
C.只要参数设置合理,深度学习的效果至少应优于随机算法
D.随机梯度下降法可以缓解网络训练过程中陷入鞍点的问题
S: C.
29.多尺度问题怎么解决?
实际上,现在有很多针对小目标的措施和改良,如下:
最常见的是Upsample来Rezie网络输入图像的大小;
用dilated/astrous等这类特殊的卷积来提高检测器对分辨率的敏感度;(空洞卷积是针对图像语义分割问题中下采样会降低图像分辨率、丢失信息而提出的一种卷积思路。利用添加空洞扩大感受野,让原本3 x3的卷积核,在相同参数量和计算量下拥有5x5(dilated rate =2)或者更大的感受野,从而无需下采样。在保持参数个数不变的情况下增大了卷积核的感受野)
有比较直接的在浅层和深层的Feature Map上直接各自独立做预测的,这个就是我们常说的尺度问题。
用FPN这种把浅层特征和深层特征融合的,或者最后在预测的时候,用浅层特征和深层特征一起预测;
SNIP(Scale Normalization for Image Pyramids)主要思路:
在训练和反向传播更新参数时,只考虑那些在指定的尺度范围内的目标,由此提出了一种特别的多尺度训练方法。
推荐阅读
