计算机视觉专业术语解析
前言:
backbone、head、neck和fine-tune

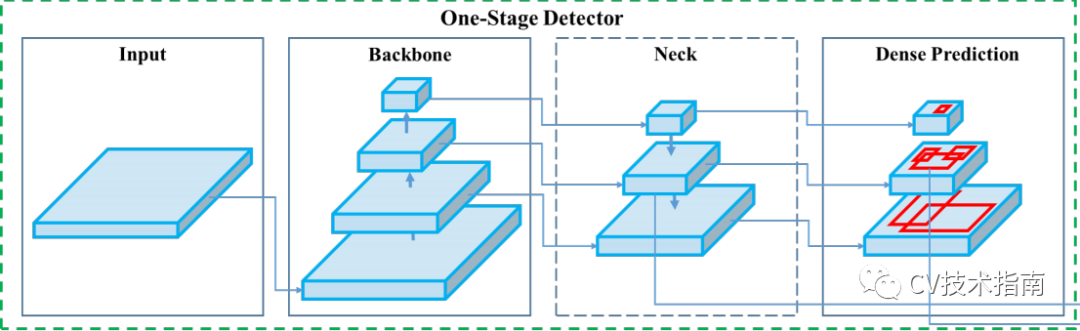
Preprocess和Postprocess
先验知识
《特征金字塔技术总结》

embedding
feature map
池化
语义信息
总结
—版权声明—
来源:CV技术指南
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
评论
 下载APP
下载APP前言:
《特征金字塔技术总结》
—版权声明—
来源:CV技术指南
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!