
零信任实践分享




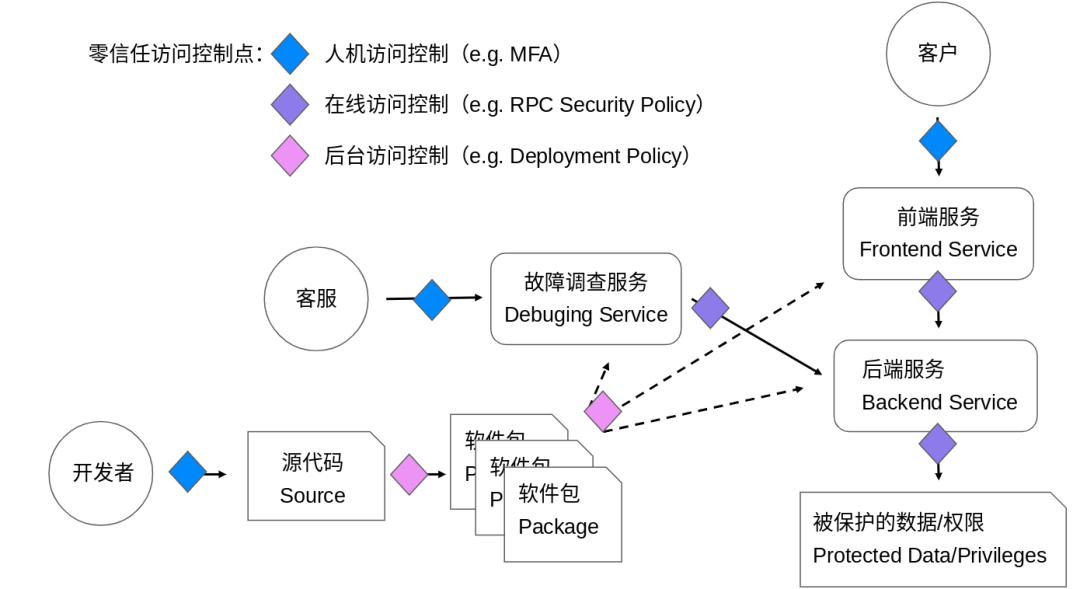
数据加密和密钥管理(Encryption and Key Management)
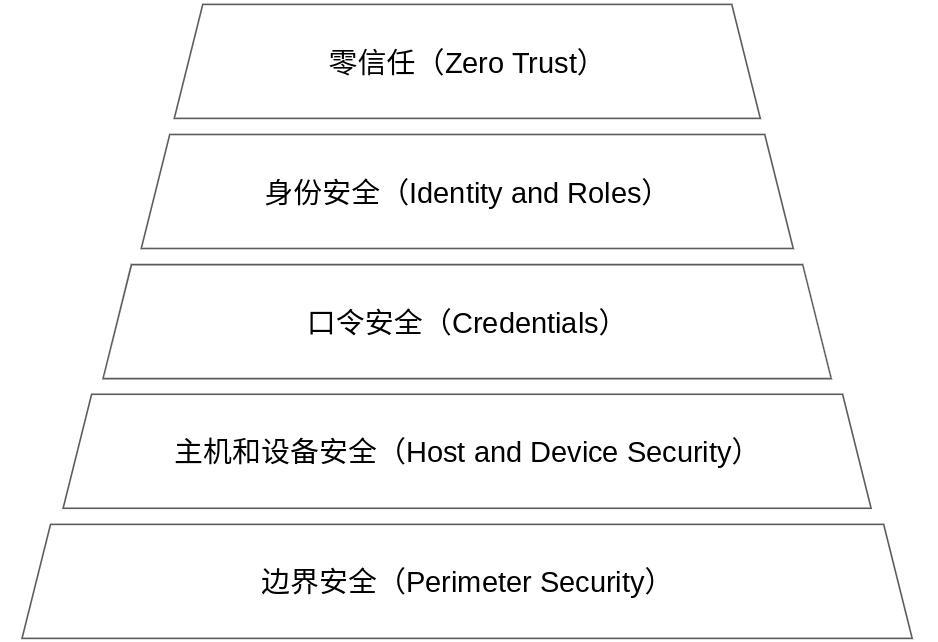
身份和访问管理(Identity and Access Management)
数字化人力资源管理(Digital Human Resource)
数字化设备管理(Digital Device Management)
数据中心安全(Data Center Security)
网络安全(Network Security)
主机安全(Host Security)
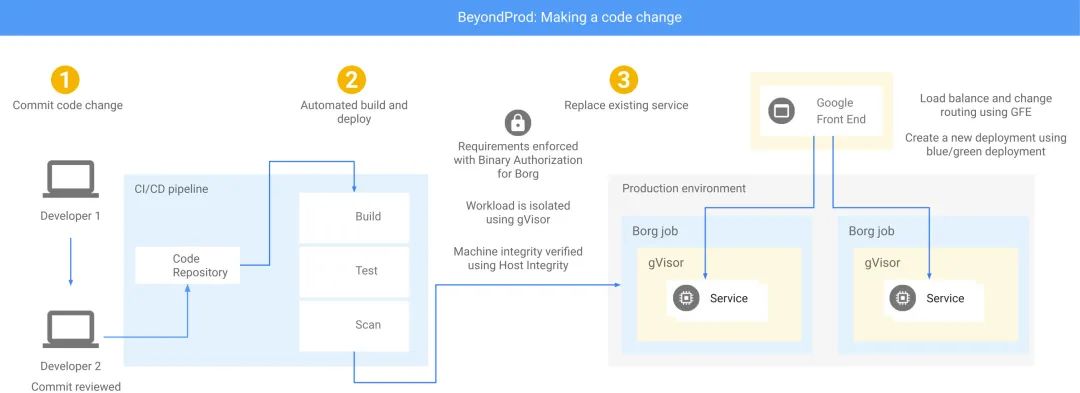
容器隔离(Container Isolation,gVisor)
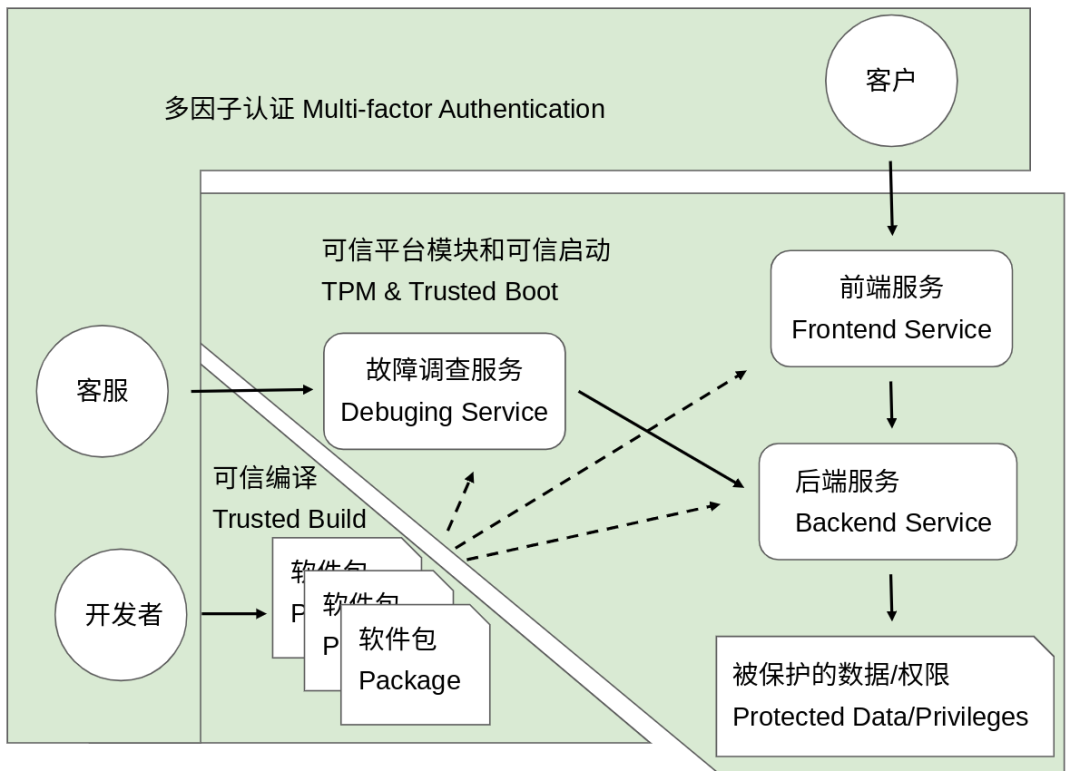
可信启动(Trusted Boot)
可验证编译(Verifiable Build)
软件完整性验证(Software Integrity Verification)
双向TLS(mTLS)
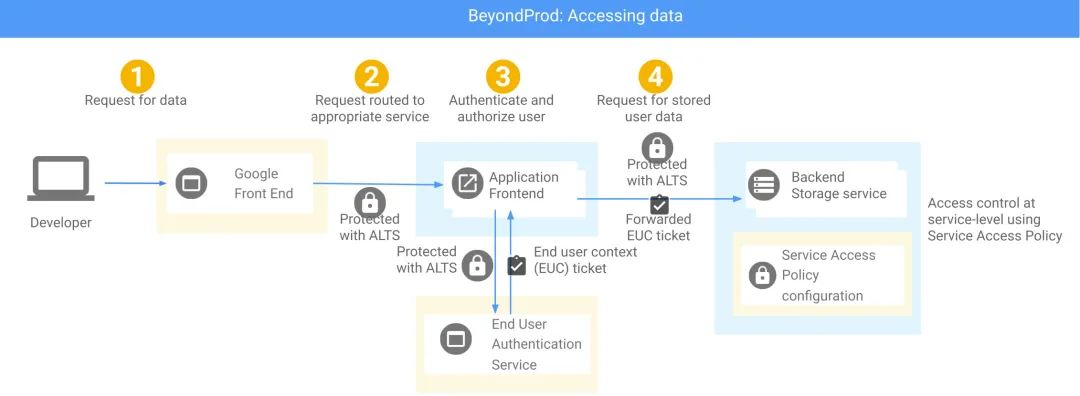
基于服务的访问策略(Service Access Policy)
终端用户令牌(End User Context Tokens)
配置即代码(Configuration as Code)
标准化开发和部署(Standard Development and Deployment)
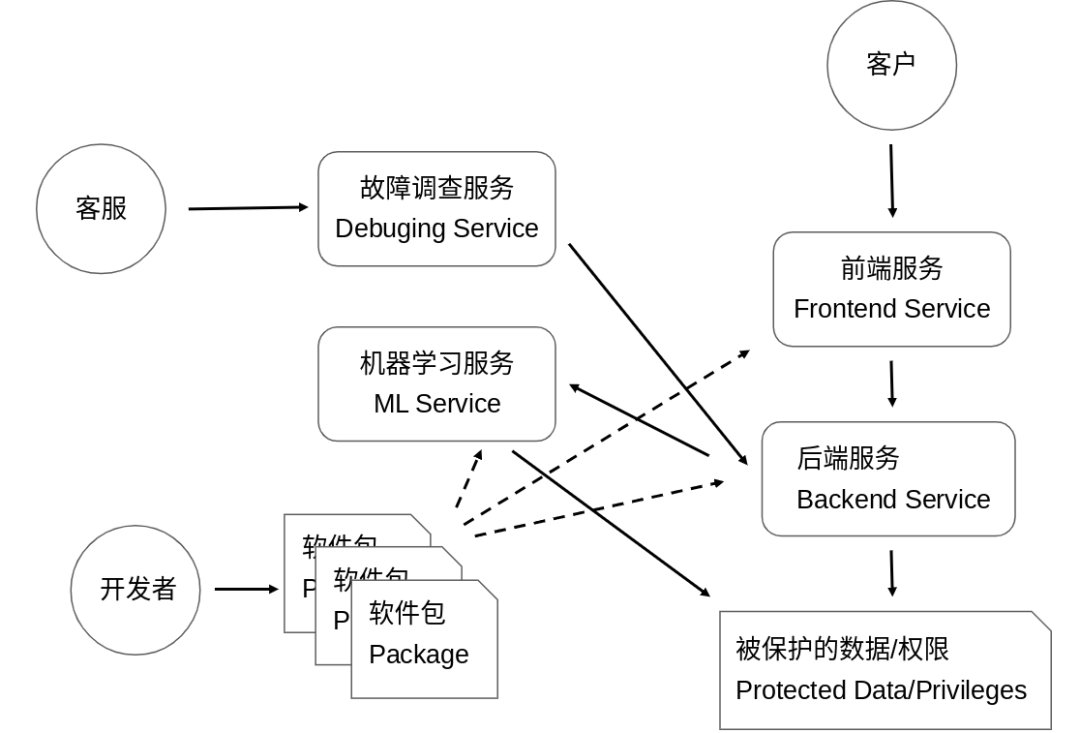
https://cloud.google.com/security/beyondprod
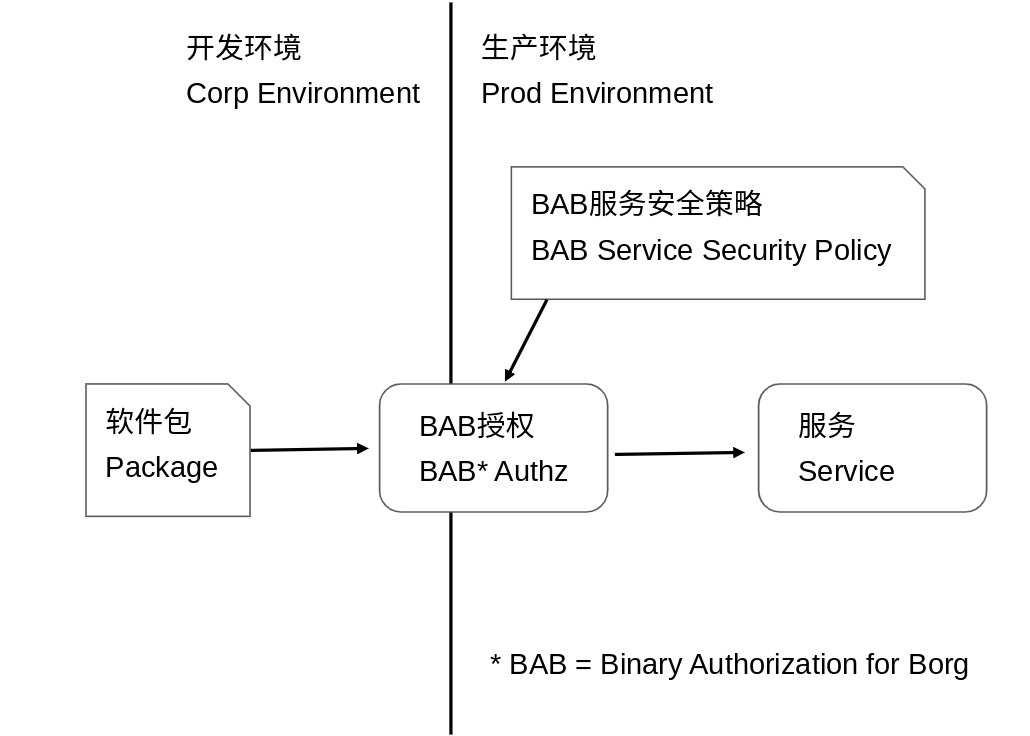
https://cloud.google.com/security/binary-authorization-for-borg
https://github.com/slsa-framework/slsa
https://sre.google/books/building-secure-reliable-systems/
https://www.youtube.com/watch?v=zCVwc3ocYfQ
https://www.usenix.org/conference/srecon19emea/presentation/czapinski
https://cloud.google.com/security/encryption-in-transit/application-layer-transport-security
https://cloud.google.com/security/beyondprod
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)