
分享前端覆盖率最佳实践
点击上方 全栈前端精选,关注公众号
回复【1】,加入前端技术交流群
来源:i.m.t
https://juejin.cn/post/6959147556295180324
前述
今天开一个新坑,讲讲前端覆盖率:Istanbul。
谈到前端覆盖率,早在18年就有接触,但由于种种原因,并没有去具体的落地。仅有的也只是了解了这是个什么,用来干什么!
最终这个应该怎么做?如何落地?并没有深究探索。想起来略有遗憾。
但这次一定!这篇文章,将讲述如何使用 Istanbul 去收集前端覆盖率、对源码的解析、如何贴合业务理解对源码做相应的修改、覆盖率一键上报等。
写在前面
在写之前,先贴一下我参考过的四篇文章,个人认为,是关于前端覆盖率写的很好的文章:
基于 Istanbul 优雅地搭建前端 JS 覆盖率平台
聊聊前端代码覆盖率 (长文慎入)
React Native 代码覆盖率获取探索
覆盖率实时统计工具
以及相关的GitHub开源:
babel-plugin-istanbul
istanbul-middleware
nyc
code-coverage
好了,搬好小板凳,我们开始吧~
正文
前端 web 覆盖率统计
首先前端覆盖率,在当下的业务场景中,包含了 web 和 mobile ,那么很多情况下,如果mobile中不是用native原生写的,大都都是内嵌H5页面的形式存在。如果你所涉及到的业务,大部分都是用 webview。
那就直接整web端的就可以了。当然如果情况不同,那在上面的链接中也给到了,一个RN的设计链接,也可以进行参考~
当然了,相信现在前端都是用 vue 或者 React 居多了,如果还是用jQuery来做,肯定太落后了。如果你们的前端项目是使用 vue 或者 React 来构建的,那么接下来的文章,对你们来说,或多或少能得到一些帮助。
反之,我个人建议不用花时间看下去,因为可能没办法很好的落地。但如果你感兴趣,能够看完,那么相信你也能看到一些有价值的东西。严格来讲是互相学习。
插件解释以及选择
按照一些前辈的讲述,以下这块我也不能跳过。如果你是第一次听到前端覆盖率,那么你肯定会好奇,有哪些工具能拿来用,并且哪个工具会更加契合。我不能一上来就告诉你要用什么?这样会叫你囫囵吞枣,云里雾里。
如果这样,我也就没有做好写这篇文章的真正的目的,就是让看的人能够带着思考看完且看懂。

image.png
上面这张图,就是对能拿来做覆盖率的工具的一个汇总,对比,详情。
看完这个,相信大家就能知道,自己所涉及到的业务,需要用什么样的工具去实现覆盖率收集的工作了。
当然,光看这个,你肯定还是不大能知道,就算选择 Istanbul 之后,怎么去用?里面有哪些东西?我该怎么插桩?服务端渲染和客户端渲染这样不同处理的情况下,如何插桩?等等。
显然,已经给你准备好了:
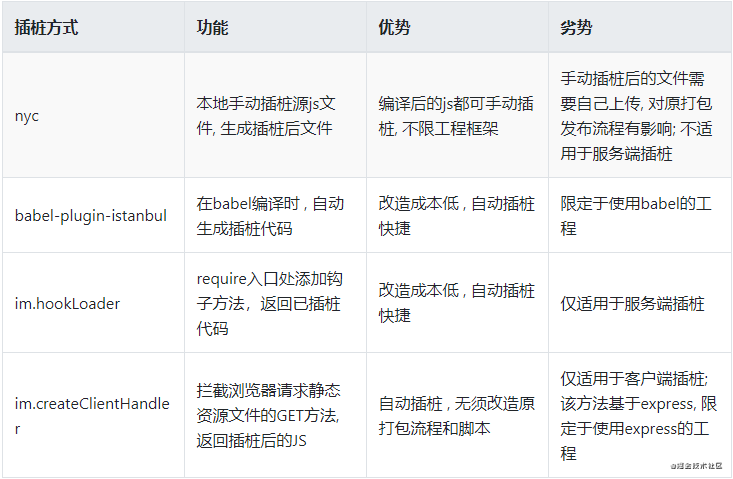
image.png
这里解释一下,nyc 是 Istanbul 的进阶版,解决了很多问题,并且当下一直有很多优秀的人在维护这个开源。当然,这篇文章不讲这个。
看完这两张图,相信大家已经有点知道,做前端覆盖率,为什么选择 Istanbul ,以及 如何选择性的对前端项目进行插桩。
为了方便大家理解,我还是需要拷贝一下这位老师的东西。拷贝的相关原文,在上面列举的文章中。(原谅我如此不要脸...嘤嘤嘤)
运行前插桩
nyc instrument
针对编译之后的JS文件 , 进行手动插桩 , 形成插桩后的新JS文件
babel-plugin-istanbul
istanbul提供的babel插件 , 能够在代码编译打包阶段直接植入插桩代码 适用于使用babel的前端工程,基于react和vue的工程都可以
运行时插桩
**im.hookLoader **
适用于服务端的文件挂载 比如node应用 当应用启动时 , 会在require入口处添加hook方法 , 使得应用启动时加载到的都是插桩后的代码
im.createClientHandler
适用于客户端的JS挂载 ,比如react和vue的js 通过指定root路径,会把所有该路径的js文件请求拦截,返回插桩后的代码,即浏览器请求静态资源的动作 效果与babel-plugin-istanbul类似,区别在于该方法是在浏览器请求js时才会返回插桩代码,是一个动态过程
babel-plugin-istanbul
最上面,我讲到如果项目是用 vue 或者 React 的,可以直接使用插件 babel-plugin-istanbul,我简单说下这个东西是干嘛的,他其实就是一个做好了的npm包,这个包做的事情,就是给你所在的项目进行插桩。那它是在什么时候插桩呢?
⭐就是在你 run 项目的时候
npm install babel-plugin-istanbul 之后,你再去run你的前端项目的时候,会发现,编译的时间会比原来run的时间 稍微的拉长了那么一点。那这一点时间,其实就是它在工作,再给你的项目处理,对你项目里面所设计的文件,进行插桩编译处理。
这里肯定会有疑问,会不会给项目带来什么影响?这个会影响前端项目吗,emmm,并不会。
它只会在你的项目里生成相对应的覆盖率文件(在后面调用的过程中有一个映射关系,后面会说到)。
看下具体的 npm 依赖吧:
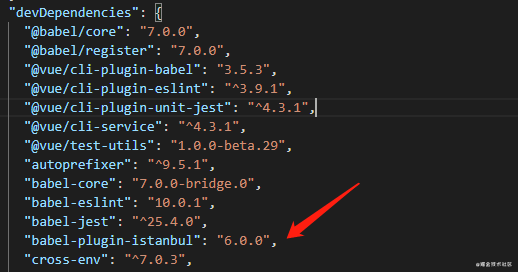
image.png
要注意的是,尽量在dev环境下进行安装此依赖。
文件配置
如果已经 install 完成了,还需要做一件事,就是配置文件做下配置:
babel.config.js
module.exports = {
presets: [
'@vue/app'
],
plugins: [
['babel-plugin-istanbul', {
extension: ['.js', '.vue']
}],
'@babel/plugin-transform-modules-commonjs'
],
env: {
test: {
plugins: [
["istanbul", {
useInlineSourceMaps: false
}]
]
}
}
}
复制代码
.babelrc
{
"presets":["@babel/preset-env"],
"plugins": [
"@babel/plugin-transform-modules-commonjs",
["babel-plugin-istanbul", {
"extension": [".js", ".vue"]
}]
],
"env": {
"test": {
"plugins": [
["istanbul", {
"exclude": [
"**/*.spec.js"
],
"useInlineSourceMaps": false
}]
]
}
}
}
复制代码
这是针对两种不同的文件的不同配置,为了方便大家我就都贴出来了。具体这些配置有什么用?干吗用?
在源码的 source-maps 这一块有讲,看大家需要做自己的处理,但是按照上面的方法去配置,是完全OK的。
然后,这里面细心的同学已经注意到了一个点,就是:'@babel/plugin-transform-modules-commonjs' ,为什么要用这个呢?其他都是些正常的配置。
这里呢,其实在我最上面贴出来的一篇文章中的评论区 reply-169807 有详细的解说,我在这里简单说下就是:使用 babel-plugin-Istanbul 插桩,和 babel-plugin-import 插件不兼容,导致编译失败 。
npm run
如果以上工作你都做好了,那就试试 把你的服务run起来吧。
ok,假设你已经run好了,这个时候,打开你的项目,再打开控制台。执行 window.coverage。
如果你看到的同下面一致,那么恭喜你,你已经成功了第一步
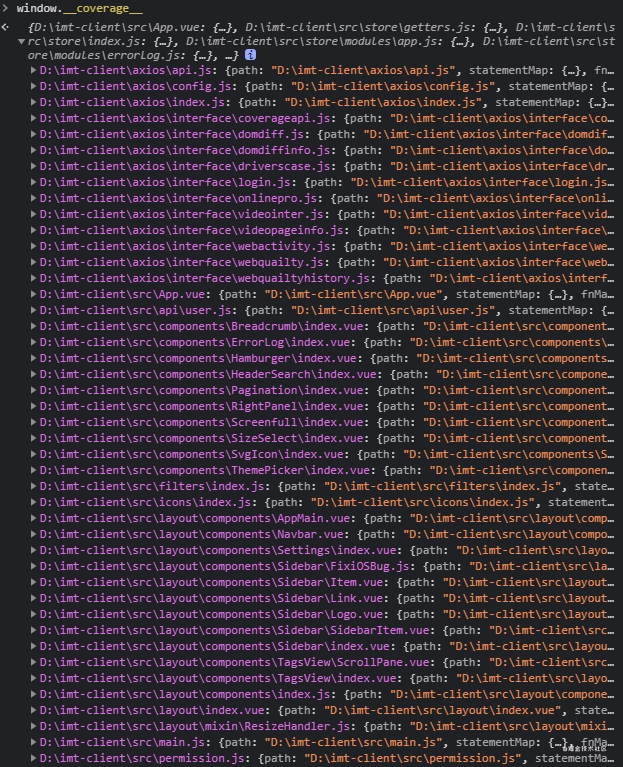
image.png
并且这个时候,你就能欣喜的看到 babel-plugin-istanbul 做的事情了,给你项目只要是涉及到的文件,都做了插桩处理,回传给你这些覆盖率信息。
要是想看具体点,就随便点一个详情,他会清楚的告诉你,所覆盖的行信息,语句,方法等。
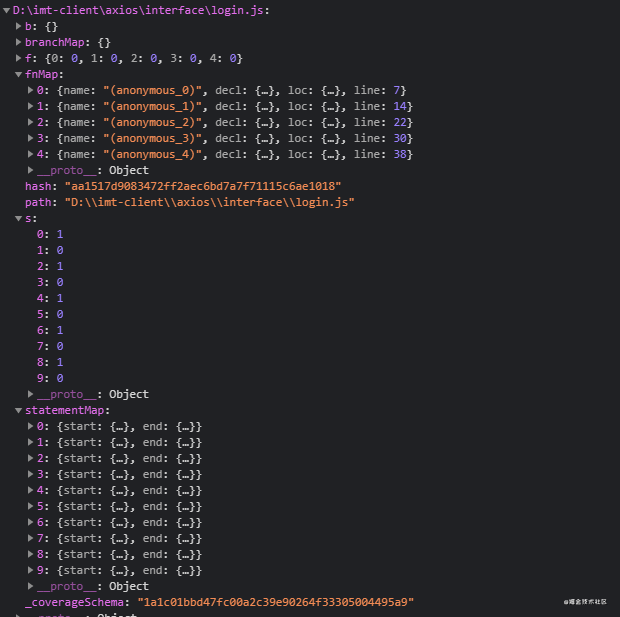
image.png
底层简介
说了这么多,都忘记了覆盖率所应当讲的基本了。大意了,没有闪。
覆盖率维度
Statements: 语句覆盖率,所有语句的执行率;
Branches: 分支覆盖率,所有代码分支如 if、三目运算的执行率;
Functions: 函数覆盖率,所有函数的被调用率;
Lines: 行覆盖率,所有有效代码行的执行率,和语句类似,但是计算方式略有差别
插装详解
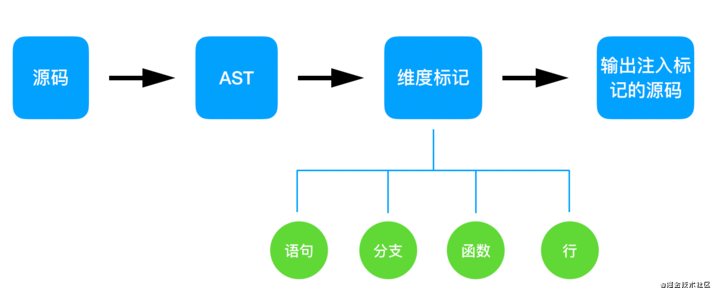
image.png
插装原理
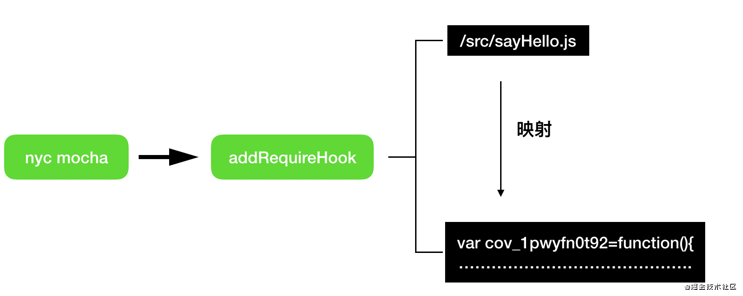
image.png
其实看到这个原理,我觉得大家就能理解,上面我说过 babel-plugin-istanbul 会生成对应的插桩后文件了。其实这些文件,存放在你的项目中,并不会影响你的项目,最多是占用了项目容量。
这个图也清晰的给出了,读取覆盖率数据的原理,就是会根据你当前访问的页面,拿到一对一的映射关系,找到插桩后的文件。我看到这个原理的时候,就大写的一个字,服!
插装前后文件对比
插装前:
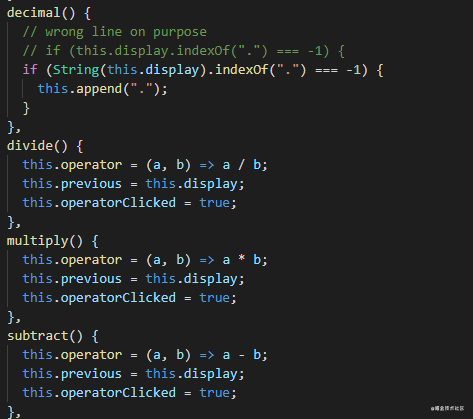
image.png
插装后:
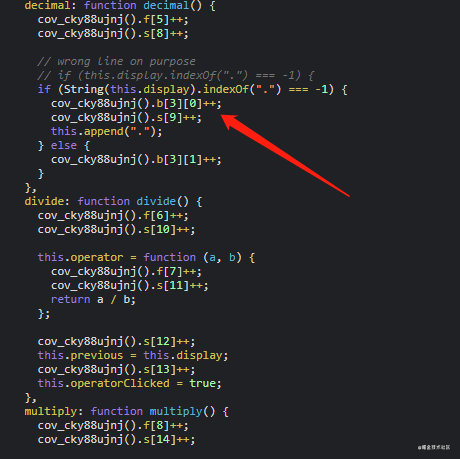
image.png
应该能很明显看到一些计数器。这些就是数据统计用的计数了。
源码解析-istanbul-middleware
大家还记得上面说到了 window.coverage 已经给到了你 覆盖率统计后的相关数据了,但是还没讲怎么收集对不对,接下来就讲收集。
对于 window.coverage 所收集到的这些信息,进行收集处理就要用到另一个伟大的开源,就是最上面给到的:istanbul-middleware ,我这边也给这简称:im。这个主要是干嘛的呢?
具体详情就点这个链接去看了,不赘述咯。主要说下,这个中间件,提供了以下的相关功能。
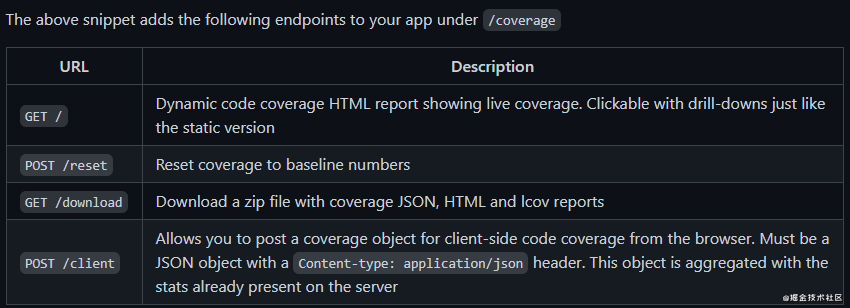
image.png
这是im项目里给到的四个接口,看到这,大家应该就恍然大悟了。也就是说,这个中间件 im 就是提供了四个接口,来对 window.coverage 收集到的数据进行处理啊。
那我们一个个来看,这四个接口分别是什么?
请求全量 / ;
重置 reset ;
下载 download ;
提交 client 。
其实还有一个show接口 展示用的。
ok,知道了这些,就相对完美了,我们就要用这个 client,来提交收集到的数据。关于这四个接口具体怎么用,其实也很简单,就是在本地起一个node服务,这几个接口都写在这个服务下面,直接根据ip来调用就可以了。
具体的可以看这个开源项目中,有一个演示就是在test目录下有个app。这个就是作者给到的一个演示的demo。聪明的你,一看就会。
源码解析-test/app/demo
为了方便大家能迅速上手,我这里给大家整一下这个demo。当然,这里我已经在源码上做了改动,不过影响也不大。
首先进入app这个路径之后,最外层的 index.js 就是这个node服务的入口文件,在readme 中能看到就是说启动的script。node index.js --coverage # start the app with coverage 。他其实给到了四个脚本语句,但是我们只用这一个。
执行完这个之后,服务就启动起来了。这个时候,输入 https://localhost:8988/xxx 。就能看到你的覆盖率收集的数据了。
好,我们再说一处,就是在server下的index.js。为什么要说这个呢,其实在最外层的 index.js 文件中,你能看到一个引用。就是:require('./server').start(port, coverageRequired);。所以其实大概就知道,这个入口中的一些配置项,都是在server下读取的。
const { json } = require('body-parser');
/*jslint nomen: true */
var
// nopt = require('nopt'),
// config = nopt({ coverage: Boolean }),
istanbulMiddleware = require('istanbul-middleware'),
coverageRequired = true,
port = 8988;
if (coverageRequired) {
console.log('server start with coverage !');
istanbulMiddleware.hookLoader(__dirname, { verbose: true });
}
// console.log('Starting server at: http://localhost:' + port);
// if (!coverageRequired) {
// console.log('Coverage NOT turned on, run with --coverage to turn it on');
// }
require('./server').start(port, coverageRequired);
复制代码
这个时候,我们看到server中的index.js 文件的时候,能看到一些东西,端口号啊,以及我们当初启动服务的 --coverage 传参啊,以及express 相关启服务操作等等。
所以,看到这,你就可以根据你自己的喜好,改一些东西。
比方我不喜欢每次启node服务的时候,都是 node index.js --coverage 我想简单点,就直接 node index.js 那其实就能在外面的index文件里面改,直接把coverageRequired 这个参数设置成true就好了。
再比如,新开始的情况下,服务启动起来,如果需要被其他端调,就涉及到跨域,那么就要做跨域的处理。再比如,后面要讲到的覆盖率上报插件,只能识别 https,你本地起的服务,访问都是用 http 访问,那么也需要在这边进行改动等等一系列。
这边我给一下,我在server 下的 index 文件做的处理,大家可以参考:
/*jslint nomen: true */
var path = require('path'),
express = require('express'),
url = require('url'),
publicDir = path.resolve(__dirname, '..', 'public'),
coverage = require('istanbul-middleware'),
bodyParser = require('body-parser');
function matcher(req) {
var parsed = url.parse(req.url);
return parsed.pathname && parsed.pathname.match(/\.js$/) && !parsed.pathname.match(/jquery/);
}
module.exports = {
start: function (port, needCover) {
var app = express();
var http = require('http');
var https = require('https');
var fs = require('fs');
//设置跨域访问
app.all('*', function (req, res, next) {
// console.log('req: ', req)
res.header("Access-Control-Allow-Credentials", "true"); //服务端允许携带cookie
res.header("Access-Control-Allow-Origin", req.headers.origin); //允许的访问域
res.header("Access-Control-Allow-Headers", "Content-Type,XFILENAME,XFILECATEGORY,XFILESIZE"); //访问头
res.header("Access-Control-Allow-Methods", "PUT,POST,GET,DELETE,OPTIONS"); //访问方法
res.header("Content-Security-Policy", " upgrade-insecure-requests");
res.header("X-Powered-By", ' 3.2.1');
if (req.method == 'OPTIONS') {
res.header("Access-Control-Max-Age", 86400);
res.sendStatus(204); //让options请求快速返回.
}
else {
next();
}
});
if (needCover) {
console.log('Turn on coverage reporting at' + '/bilibili/webcoverage');
app.use('/bilibili/webcoverage', coverage.createHandler({ verbose: true, resetOnGet: true }));
app.use(coverage.createClientHandler(publicDir, { matcher: matcher }));
}
app.use('/', express.static(__dirname + ''));
app.use(bodyParser.urlencoded({ extended: true }));
app.use(bodyParser.json());
app.set('view engine', 'hbs');
app.engine('hbs', require('hbs').__express);
app.use(express['static'](publicDir));
// app.listen(port);
var httpServer = http.createServer(app);
var httpsServer = https.createServer({
key: fs.readFileSync('E:/coveragewithweb/app/cert/privatekey.pem', 'utf8'), //app\cert\privatekey.pem app\server\index.js
cert: fs.readFileSync('E:/coveragewithweb/app/cert/certificate.crt', 'utf8')
}, app);
// httpServer.listen(port, function () {
// console.log('HTTP Server is running on: http://localhost:%s', port);
// });
httpsServer.listen(port, function () {
console.log('HTTPS Server is running on: https://localhost:%s', port);
});
}
};
复制代码
源码解析-提交 client
好了,看完服务了,我们来看这个client,既然是提交接口,并且是本地启的node服务,并且,严格声明了请求格式:"Content-Type", "application/json"。
那么简单了,我们来直接把服务启动起来,走一个试试呗。

image.png
很完美,已经提交成功了。那既然提交了,就再看看提交的结果呗。
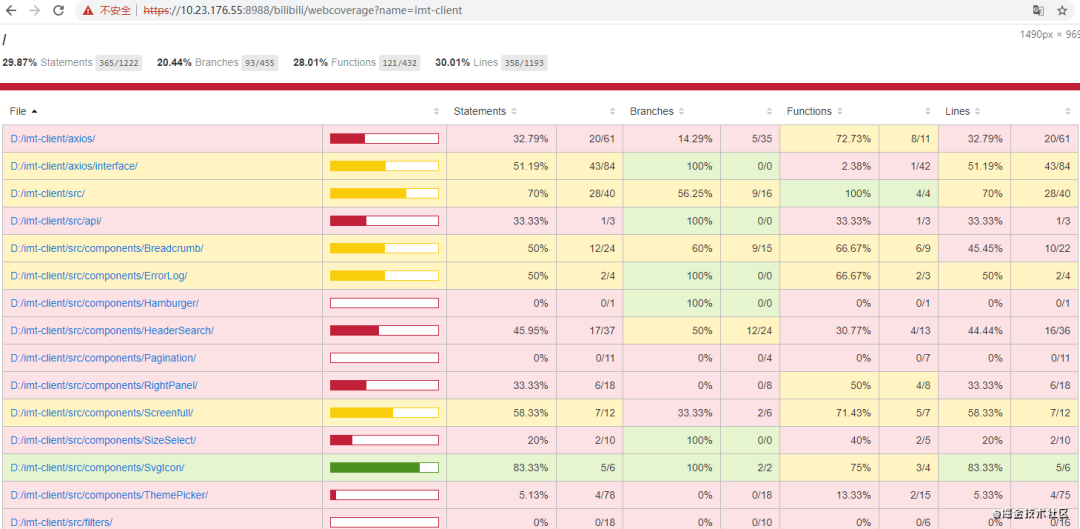
image.png
哇。看到了什么,简直太棒了。
当然了,这边看到的url效果是我处理后的,我等下会一个个讲哦,大家先别急。
既然知道了client 是提交接口,是不是要去看下源码?
定位到源码。是一个叫 handlers.js 的文件,里面很明显能看到我们刚刚看到的四个接口,并且这四个接口,都在一个叫 creatHandler 的对象下面。其实看到这,我才能理解当初看其他老师说,根据自己的业务去改 creatHandler 源码的意思,其实就是说的这边。
这边我们讲client 那就只看这一个,具体的大家可以去源码看
//merge client coverage posted from browser
app.post('/client', function (req, res) {
// console.log('req: ', req)
var body = req.body;
if (!(body && typeof body === 'object')) { //probably needs to be more robust
return res.send(400, 'Please post an object with content-type: application/json');
}
core.mergeClientCoverage(body);
res.send({ success: '上报成功' });
});
复制代码
可以看到client,底层是调用的 core.mergeClientCoverage() 这个方法,并且将我们通过client 传进来的 覆盖率信息 作为参数传进去。
那么好了,我们直接去看 mergeClientCoverage() 这个就可以了,这个就在 handlers.js 的同一层级下的 core.js 中。我们把源码贴出来
function mergeClientCoverage(obj) { // resolve coverage datas 这边传进来的就是 coverage的 window.coverage 信息
var coverage = getCoverageObject(); // 初始状态下的coverage 覆盖信息
Object.keys(obj).forEach(function (filePath) {
var original = coverage[filePath], // filepath = key 即文件路径 || original 是已经存在的数据
added = obj[filePath], // added 最新的覆盖率信息数据
result; // 定义一个预备内存
if (original) {
result = utils.mergeFileCoverage(original, added);
} else {
result = added;
}
coverage[filePath] = result; // 最终的覆盖率信息 存放到临时内存!getCoverageObject()
}
});
// coverage 是最终的覆盖率信息,每次进行存储,用key值来关联,key指向业务版本
}
复制代码
这段源码中,其实可以看到他是怎么处理的,首先是调用 getCoverageObject() 去拉取最初始的覆盖率信息,给一个初始定义 coverage。
Object.keys(obj).forEach(function (filePath) {} 这个就是遍历处理传进来的新的覆盖率对象了。
original 定义的是,覆盖率服务原本就已经存在的数据。
added 则是去处理新进来的覆盖率数据。
最后定义一个临时内存存储 result 。
在后面的便利过程中,会有一个merge的过程,就是去判断 original 是否存在,如果存在就是存在原始数据,就需要将新数据和原始数据 进行merge合并,即:result = utils.mergeFileCoverage(original, added);,如果没有,那就直接新增就好了 result = added;
最后全部的覆盖率数据都给到了result 这个对象,最后,直接将最后的结果,再放到先开始定义的 coverage 中,就完成了整个覆盖率合并的操作。
其实大家可以在往深了看,就是这个 utils.mergeFileCoverage(original, added) 做了什么事。这边我就不一一讲述了。
那么为什么要把这些拿出来看呢,其实这块需要做的处理有几个,一个就是,我在文章最初给到的那些老师的文章中有说到,就是根据自己的业务逻辑去设计自己的覆盖率数据采集。
这里我又要不要脸了,我要去copy了。
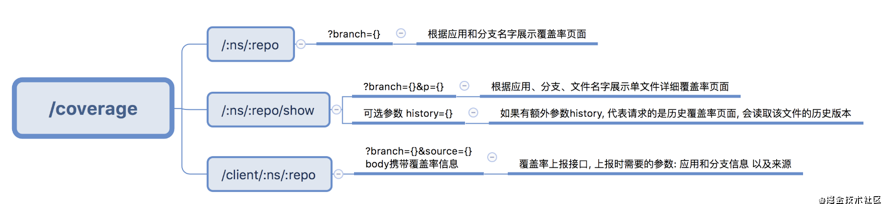
image.png
也就是说,如果你有好几个业务,你不能一下子不分版本,分支,项目名的都传进来进行处理。你需要跟你的项目的分支,版本,业务名等等进行自己的处理,再传进来进行收集。
另一个就是,这里启的node服务,都是占用的临时内存。需要我们去将这些收集到的覆盖率数据采集完成之后,再去落库。存储起来,不然服务挂了,什么都没了。这是多可怕的一件事。
还有一个最终的要就是,你需要在这里去处理不同机器上的文件统计。
这里是什么意思呢,大家可能很好奇。其实这个就是我踩过的坑。就是比方说,一个项目发布到了一个机器上去,这里简称这台服务为A,而你的覆盖率统计的这个node服务,部署再你的另一台机器上,我们简称B。
那么这个时候,你拿到A的覆盖率数据信息,就不能被B所解析,这里的解析的意思就是,回传过来的哪些覆盖率数据,B服务器上,没有文件能对的上,因为B服务上没有发布过你的那个项目啊。你A服务上的覆盖率信息,可以通过,window.coverage 上报回来。但是我本地没有文件能跟你匹配。
所以就会报错,如果你的B服务上的node服务,后期自己不去写的健壮一些,可能就会因为找不到,服务挂了。
所以,你需要在这里,去将A服务上的项目,同步一份到B服务上,并且,你需要去更改收集到的覆盖率信息中的 key 关键字,以及 每个子对象下的path 路径为B服务的key 以及 路径。
emmm 不知道大家能不能看懂,要是没明白,再联系我细讲吧。
源码解析-提交 show
好了,花了大的篇幅,讲client。差不多也讲完了。
那就再来看看 show 吧。一样的,先看源码:
//merge client coverage posted from browser
//show page for specific file/ dir for /show?file=/path/to/file
app.get('/show', function (req, res) {
var origUrl = url.parse(req.originalUrl).pathname
u = url.parse(req.url).pathname,
pos = origUrl.indexOf(u), // show 起使位置
file = req.query.p; // p的参数值
if (pos >= 0) {
origUrl = origUrl.substring(0, pos);
}
if (!file) {
res.setHeader('Content-type', 'text/plain');
return res.end('[p] parameter must be specified');
}
// console.log('res: ', res)
core.render(file, res, origUrl);
});
复制代码
其实这边也可以清楚的看到,这个show,其实也是调用的底层的 core.render(file, res, origUrl); 只不过在调用之前,给他传了 show 后面跟的参数,返回,origUrl。
话不多说,直接去看 render()。
function render(filePath, res, prefix) {
var collector = new istanbul.Collector(),
treeSummary,
pathMap,
linkMapper,
outputNode,
report,
coverage,
fileCoverage;
// coverage = getCoverageObject(); // 查询已经处理后的覆盖率信息
// 这边的覆盖率信息可以从库中读取,指定访问地址,查询校验 webvideopakageistanbul-1.0
try {
coverage = getCoverageObject()
if (!(coverage && Object.keys(coverage).length > 0)) {
res.setHeader('Content-type', 'text/plain');
return res.end('No coverage information has been collected'); //TODO: make this a fancy HTML report
}
prefix = prefix || '';
if (prefix.charAt(prefix.length - 1) !== '/') { // 处理路径,路径后面跟目录路径指示
prefix += '/';
}
utils.removeDerivedInfo(coverage);
collector.add(coverage); // 覆盖率收集容器
treeSummary = getTreeSummary(collector); // 处理覆盖率的树信息,filepath,filename,fileinfo ...
pathMap = getPathMap(treeSummary); // 处理每个不同路下的覆盖信息 将全部的分类,收集存入数组
filePath = filePath || treeSummary.root.fullPath(); // 如果没有指定路径查找相关的覆盖信息,就展示全量的数据
outputNode = pathMap[filePath]; // 如果有具体的搜索参数,则在数组中找对应的对象 返回node节点信息
if (!outputNode) { // 查询路径下不存在相关信息 处理
res.statusCode = 404;
return res.end('No coverage for file path [' + filePath + ']');
}
linkMapper = {
hrefFor: function (node) {
return 'https://10.23.176.55:8988' + prefix + 'show?p=' + node.fullPath();
},
fromParent: function (node) {
return this.hrefFor(node);
},
ancestor: function (node, num) {
var i;
for (i = 0; i < num; i += 1) {
node = node.parent;
}
return this.hrefFor(node);
},
asset: function (node, name) { // 资源文件处理 resource files
return 'https://10.23.176.55:8988' + prefix + 'asset/' + name;
}
};
report = Report.create('html', { linkMapper: linkMapper }); // 处理最终的报告
res.setHeader('Content-type', 'text/html');
if (outputNode.kind === 'dir') {
report.writeIndexPage(res, outputNode);
} else {
fileCoverage = coverage[outputNode.fullPath()];
utils.addDerivedInfoForFile(fileCoverage);
report.writeDetailPage(res, outputNode, fileCoverage);
}
return res.end();
} catch (e) {
res.send({ '查找失败,错误详情: ': e });
}
}
var collector = new istanbul.Collector() 首先看这个,这个具体是干嘛用的呢,我理解下来,他其实就是一个覆盖率收集容器,主要做的工作,就是根据你show 后面带进来的参数,去解析相关的数据给你展示。
coverage = getCoverageObject() 这个眼熟不,他还是去拿覆盖率数据用的,但是这里的coverage,其实要根据你自己的业务,进行修改,这个 getCoverageObject() 永远都是初始的数据,或者就是你服务目前收集到的数据。绝对不能一直这样用。
后面你需要跟你你自己落库的覆盖率数据,进行修改。将coverage = xxxx 替换成你自己的东西。
emmm。不知道你们能不能看懂,看不懂没关系,后面问我。
treeSummary = getTreeSummary(collector); 这个其实是处理覆盖率的树信息,能看到我们收集道德数据,都是一个json的树结构,这个就是将那些数据做一个数据化处理。
pathMap = getPathMap(treeSummary); // 处理每个不同路下的覆盖信息 将全部的分类,收集存入数组
filePath = filePath || treeSummary.root.fullPath(); // 如果没有指定路径查找相关的覆盖信息,就展示全量的数据
linkMapper 这个具体是干嘛用的呢,细心看的化,就会发现,这个其实就是在展示覆盖率数据,所需要的资源文件,其中包含了 css 以及 js。自带属性。
utils.addDerivedInfoForFile(fileCoverage); report.writeDetailPage(res, outputNode, fileCoverage);
这两个就是判断到访问的数据存在之后,进行文件整合,就是在上面 treeSummary pathMap filePath 处理完之后,进行全量数据吞吐。report 就是讲数据进行文本处理,最终展示html即可。
同样的来分析这快源码的意义是什么呢?
这块的处理相对而言就较为简单,上面client 说到,需要根据不同的业务,对不同的项目,不同的分支等等进行落库处理,那么这里其实就是,你在show 后面 的p参数值,拿到之前存储的数据进行展示的时候,进行一对一处理用。
其实这块还可以往下再看,就比方说,getTreeSummary() 这个方法做了哪些事,等等,如果想彻底搞清楚,可以再接着往下读。我这边就不详细叙述了。
插件上报
上面将istanbul 相关的源码都解读了,相信大家都能看懂,甚至能看的比我都深。那再来说下关于数据的上报吧。
数据上报这块,在其他老师的文章中可以看到,有两种方法:chrome插件 和 fiddler。其实还有一种方法 就是 sidebar,容器边车模式。这个也是我请教了以为大佬。给到的方案。但是我没有搞透彻。要是你知道,可以私我。我想请教一二。
那这边我只讲一下,插件上报。即 chrome插件。首先需要说一下,就是我们的覆盖率数据,是存在与当前页的,如果当前页的 window 对象下面是有coverage集合的,就可以通过 window.coverage 进行获取,再调用client 进行上报。
那么如果使用chrome 插件 就需要 chrome插件 能读到 你当前页的window对象。不然就获取不到下面的coverage集合。
如果有写过chrome 插件的,肯定是知道,content_script.js 是可以与当前页面进行dom交互,但是会有一个问题,就是拿不到当前页的window对象。
所以我这边做了一个处理:就是再覆盖率的node服务上,单独写一个文件,通过 content_script.js 写到 当前页的dom中。代码如下:
test.js
setTimeout(() => {
if (window.__coverage__) {
localStorage.setItem('coveragecollect', JSON.stringify(window.__coverage__))
}
}, 3000)
content_script.js
setTimeout(function () {
var ss = document.createElement('script')
ss.src = "https://10.23.176.55:8988/test.js"
document.body.appendChild(ss)
}, 3000)
为了方便,先写到local中,然后,再使用插件的当前页的js 执行一段executeScript,植入另一个脚本,与 content_script.js 进行交互。这样就解决了无法获取的问题:
popup.js
let changeColor = document.getElementById('changeColor');
changeColor.onclick = function (element) {
let color = element.target.value;
chrome.tabs.query({ active: true, currentWindow: true }, function (tabs) {
chrome.tabs.executeScript(
tabs[0].id,
{ file: 'js/test.js' });
});
};
interact.js
setTimeout(function () {
var aa = localStorage.getItem('coveragecollect')
if (aa) {
console.log('存在')
var data = aa;
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
xhr.addEventListener("readystatechange", function () {
if (this.readyState === 4) {
alert(this.responseText);
}
});
xhr.open("POST", "https://10.23.176.55:8988/bilibili/webcoverage/client");
xhr.setRequestHeader("Content-Type", "application/json");
xhr.send(data);
} else {
console.log('不存在')
}
}, 3000);
详细代码请见coverage-chrome。
插件的具体使用可以参考我之前写的一篇chrome插件
结尾
后面我将持续开坑关于前端覆盖率之自动化集成,引用 code-coverage,另一个优秀的开源。
好了,以上就是本文要讲的全部内容了,要是你有更高的见地,很欢迎与我交流,我们互相学习。