
使用 Python 构建图片搜索引擎
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自:AI算法与图像处理

我们经常使用搜索引擎。当我们需要查询时,我们可以使用像 Google 这样的搜索引擎来检索最相关的答案。
大多数查询格式是基于文本的。但并不是大多数时候,文本对于找到相关的答案是非常有用的。
例如,你想在互联网上搜索一个产品,在这种情况下,是一件 t 恤,但你不知道它的名字。你怎么能找到他们?你可以把那件衬衫的描述写下来。
使用描述的问题是你会得到各种各样的产品。更糟糕的是,它们与你想要搜索的产品并不相似,所以你需要一个更好的方法来检索它们。
为了解决这个问题,我们可以使用产品的图像,提取其特征,并利用这些特征检索相似的产品。我们称这个概念为基于内容的图像检索。
在本文中,我将向您展示如何使用 Python 构建图像搜索引擎。
基于内容的图像检索
在我向您解释如何使用 Python 构建图像检索之前,让我向您解释基于内容的图像检索的概念。
基于内容的图像检索(CBIR)是一种基于给定图像的相关图像检索系统。该系统由图像查询和图像数据库两部分组成。
该系统首先对所有图像进行特征提取,无论是查询图像还是图像数据库图像,使用特征提取算法。然后,系统将计算查询与数据库中所有图像之间的相似性。最后,系统将检索所有与查询有很大相似性的图像。
图1描述了 CBIR 的流程。
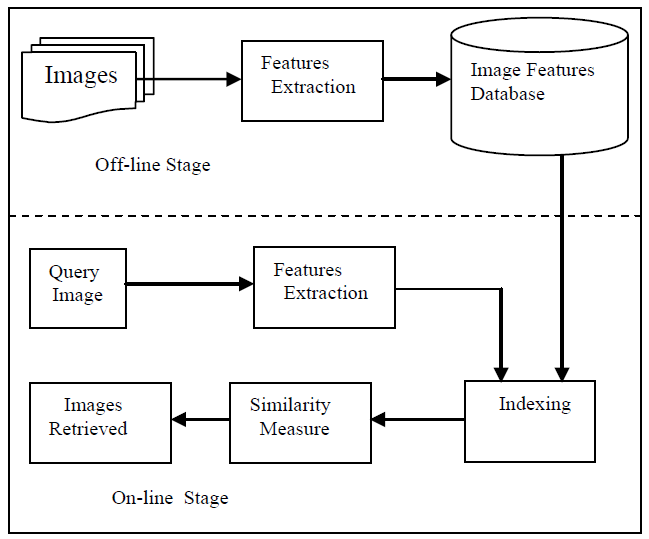
图一 CBIR 的流程
卷积神经网络
要提取特征,有许多选项可供选择。在这种情况下,我们可以使用卷积神经网络(CNN)来提取这些特征。
由于该模型的卷积层能够捕获每个数据实例的特征,因此它比其他算法具有更强的模式捕获能力。
卷积神经网络由很多层网络组成,例如卷积层用于特征提取,池层用于特征采样,完全连接层用于预测。
在这种情况下,我们忽略了大部分的完全连接层,只关注特征提取的结果。
图2显示了卷积神经网络架构的示例,即 LeNet-5。
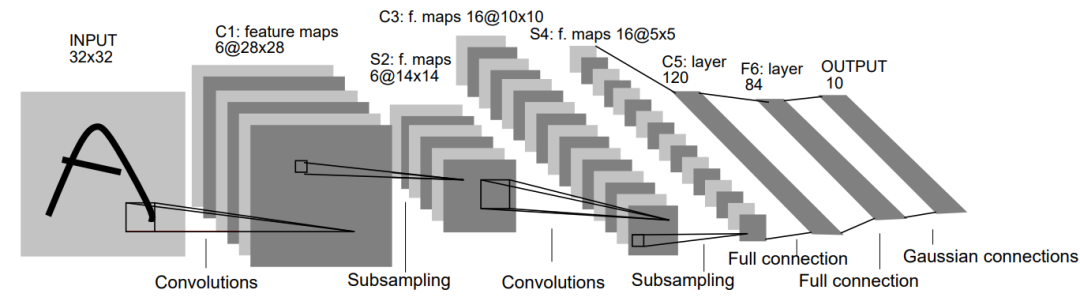
图2. LeNet-5架构
欧几里得度量
提取特征后,计算查询与所有图像之间的距离。为了做到这一点,我们可以使用欧几里得度量或 l 2标准来衡量它。如果数字越来越小,那么这一对图像就是相似的。公式是这样的:
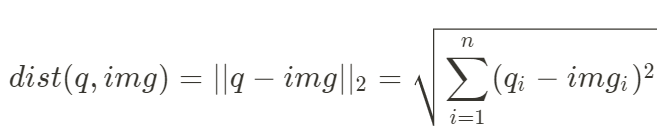
其中:
q = 待查询图像
img = 图像
n = 特征向量元素的个数
i = 矢量的位置
在我们知道了这些概念之后,现在我们可以实现这个系统了。为了实现 CBIR,我们将使用 Python 作为编程语言,Tensorflow 用于特征提取框架,Numpy 用于计算距离。如果我们总结一下,这里是我们将要做的步骤:
下载数据集
从图像数据库中提取特征
插入查询图像并提取其特征
计算所有图像的相似性
检索最相似的结果
对于数据集,我们将使用来自 Kaggle 的 CBIR 数据集。你可以通过这里的链接访问数据集:https://www.kaggle.com/theaayushbajaj/cbir-dataset/notebooks。

Figure 3. Screenshot by me 图3. 我的屏幕截图
在我们检索所有的图像之后,现在我们可以使用 CNN 从所有的图像中提取特征并将这些特征保存在 .npy 格式的文件中以供日后使用。为了指定体系结构,我们将使用 VGG-16体系结构和来自 ImageNet 的预先训练的权重。
另外,我们可以利用 GPU 提取图像的特征,但是在这种情况下,我们只使用 CPU。
代码是这样的:
# Import the librariesfrom tensorflow.keras.preprocessing import imagefrom tensorflow.keras.applications.vgg16 import VGG16, preprocess_inputfrom tensorflow.keras.models import Modelfrom pathlib import Pathfrom PIL import Imageclass FeatureExtractor:def __init__(self):# Use VGG-16 as the architecture and ImageNet for the weightbase_model = VGG16(weights='imagenet')# Customize the model to return features from fully-connected layerself.model = Model(inputs=base_model.input, outputs=base_model.get_layer('fc1').output) def extract(self, img):# Resize the imageimg = img.resize((224, 224))# Convert the image color spaceimg = img.convert('RGB')# Reformat the imagex = image.img_to_array(img)x = np.expand_dims(x, axis=0)x = preprocess_input(x)# Extract Featuresfeature = self.model.predict(x)[0]return feature / np.linalg.norm(feature)# Iterate through images (Change the path based on your image location)for img_path in sorted("<IMAGE DATABASE PATH LIST HERE>"):print(img_path)# Extract Featuresfeature = fe.extract(img=Image.open(img_path))# Save the Numpy array (.npy) on designated pathfeature_path = "<IMAGE FEATURE PATH HERE>.npy"np.save(feature_path, feature)
在我们从所有图像中提取特征之后,现在我们可以尝试使用查询检索类似的图像。在这种情况下,我们可以输入一张看起来类似下图的狮子:

为了检索类似的图像,我们使用如下代码:
# Import the librariesimport matplotlib.pyplot as pltimport numpy as np# Insert the image queryimg = Image.open("<IMAGE QUERY PATH HERE>")# Extract its featuresquery = fe.extract(img)# Calculate the similarity (distance) between imagesdists = np.linalg.norm(features - query, axis=1)# Extract 30 images that have lowest distanceids = np.argsort(dists)[:30]scores = [(dists[id], img_paths[id]) for id in ids]# Visualize the resultaxes=[]fig=plt.figure(figsize=(8,8))for a in range(5*6):score = scores[a]axes.append(fig.add_subplot(5, 6, a+1))subplot_title=str(score[0])axes[-1].set_title(subplot_title)plt.axis('off')plt.imshow(Image.open(score[1]))fig.tight_layout()plt.show()
最终的结果如下:


总结
祝贺你!你已经创建了自己的图片搜索引擎。好吧,这并不是非常类似于谷歌,但至少你知道的概念,如何基于内容的图像检索工作。
如果你对 web 开发有所了解,也许你可以使用 Flask 或 Django 这样的框架创建一个 web 应用程序来构建你自己的搜索引擎。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~