
"锟斤拷"的前世今生
不管是在工作中还是生活中,相信很多同学都被“锟斤拷”深深的毒害过,比如这样,
这样,

还有这样,
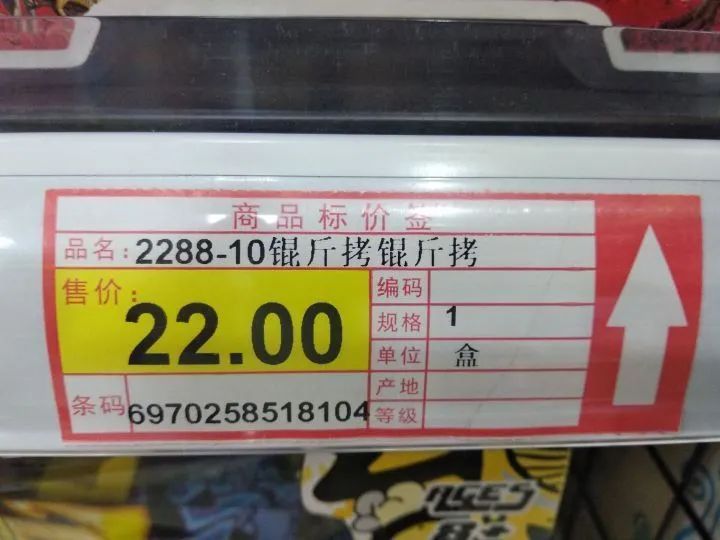
那么究竟是为什么会出现这些奇怪的字符?接下来我们一探究竟!
ASCII编码
在计算机底层都是用0和1进行存储的,ASCII编码将所有的字母及符号进行编码后转成二进制的0和1进行存储,字母和符号占1个字节(即8bit),标准的ASCII码规定最高位必须为0,因此ASCII编码只能有128个,转成十进制即为0-127。标准的ASCII码表如下:
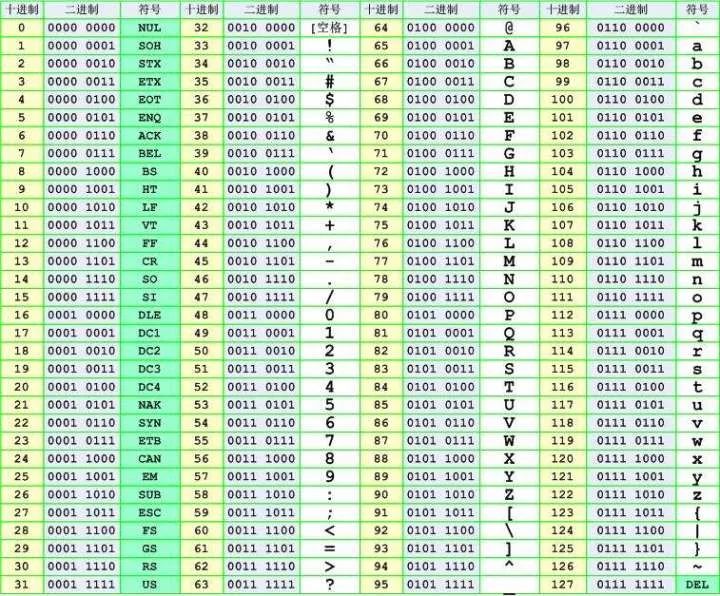
ASCII码表只有128个字符,对于英语来说已经够用了,但是世界上还有很多国家的文字各不相同,这时候就需要一个更加全面的编码出现。
Unicode(又称统一码、万国码、单一码)是计算机科学领域里的一项业界标准。它为每种语言中的每个字符设定了统一并且唯一的二进制编码。在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这个字符。
UTF-8与GBK
UTF-8是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容。UTF-8使用一至四个字节为每个字符进行编码。常用的汉字采用3个字节进行编码。
因为UTF-8是针对Unicode的一种可变长度的字符编码,所以它包含了世界上所有字符的编码,对于那些早录入的字符,就会优先使用1、2个字节来存储,对于迟录入的字符存储占用的字节就会大一些,这样,那些迟录入的字符存储空间就会很大。
对于一个中文网站,实际上并不需要其他国家的文字出现,但是中国汉字用UTF-8进行编码,大多数却占用了3个字节甚至更多字节,这样就造成了不必要的存储浪费。为了解决这种问题,中华人民共和国全国信息技术标准化技术委员会制定了一套GB系列的编码,最常用的就是GBK了。
GBK编码英文使用单字节编码,完全兼容ASCII字符,汉字使用了两个字节进行编码,其编码范围从0x8140(表示16进制)至0xFEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,图形符号 883 个。
为什么要剔除xx7F,因为它对应的ASCII码表是DEL,意味着要向后删除一个字符。
为什么会出现“锟斤拷”
Unicode编码一直持续在收录各种字符,这就可能会出现各种操作系统支持的Unicode字符不一样。这也就会导致A上的一个用Unicode编码的字符,在B上就会出现无法显示的情况。为了避免这种情况,在Unicode中定义了一个特殊字符�,它的Unicode编码为0xFFFD。
假如A支持特殊字符⬆,但是B并不支持这个⬆,那么在B中将会用�来代替。

这个字符用UTF-8编码后,十六进制表示为0xEF 0XBF 0XBD。如果连续出现两个⬆符号,那么用UTF-8编码后的十六进制则表示为0xEF 0XBF 0XBD 0xEF 0XBF 0XBD,这时候再转码成GBK,因为GBK中用两个字节表示一个字符,那么上述的字符就成了锟(0xEFBF),斤(0xBDEF),拷(0xBFBD)。出现锟斤拷的原因就是UTF-8转码GBK的过程中出现了问题。当然如果想要出现锟斤拷,则至少需要两个字符出现乱码。
接下来,我们直接用代码来看一下效果:
@Test
void contextLoads() throws Exception {
String str = "�";
String strCode = new String(str.getBytes("UTF-8"), "GBK");
System.out.println(strCode);
}
运行结果为锟�,前面也说了如果想要出现锟斤拷,则至少需要为两个字符,现在再修改一下代码。
@Test
void contextLoads() throws Exception {
String str = "��";
String strCode = new String(str.getBytes("UTF-8"), "GBK");
System.out.println(strCode);
}
运行结果如下为锟斤拷。
如果以后再遇到锟斤拷,不要慌,它一定是UTF-8在转换GBK编码的时候出现了问题。现在看来GBK编码虽然减少了内存的浪费,但是也带来了不少问题。
参考:zhihu.com/question/23024782
END
有热门推荐?
2. 10个常见的软件架构模式
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
