
从 "�" 到 "锟斤拷",这都是些啥玩意?


手持两把锟斤拷,
口中疾呼烫烫烫。
脚踏千朵屯屯屯,
笑看万物锘锘锘。
� 为何物?
其实,这个 “�” 真是无处不在,比如大名鼎鼎的微信:

再比如,封面图中,单价22元的“锟斤拷锟斤拷”,再随便百度一把:
要弄清这个问题,还得先从编码谈起。
因为在计算机的眼里,都是二进制,具体用哪些二进制数字表示哪个符号,这就是编码。不要把编码想象得太复杂,其实就是一个很简单的 mapping。
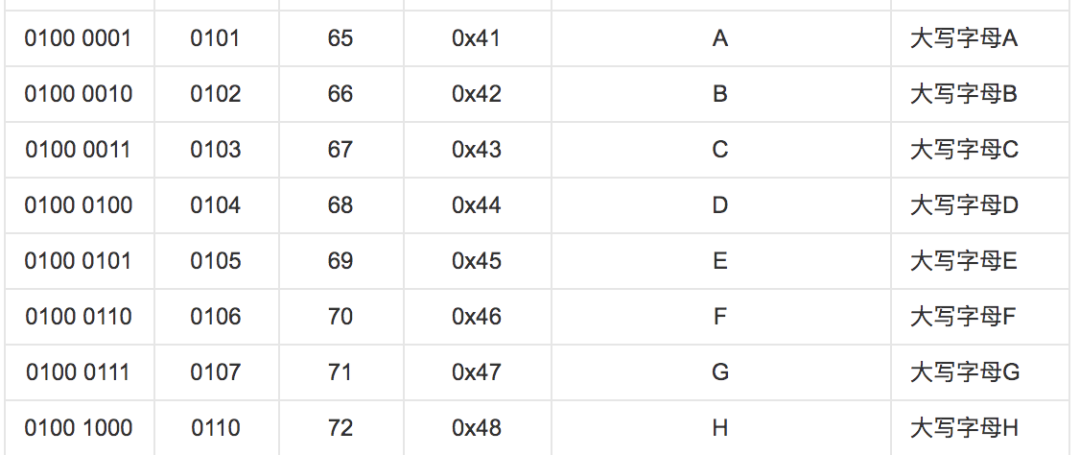
比如大家所熟知的 ASCII 编码,规定了二进制的0100 0001,也就是十进制的65,代表的含义就是大写字母 A。
� 也是一种编码字符,就跟上面的 A 一样一样的,它是 UNICODE 编码方式中的一个特殊的字符,也就是 0xFFFD(65533),语义是一个占位符,用来表达这套编码系统中未知的、自己不认识的东西。
比如下面的实验截图,红色部分圈出来的对应的字符,UTF-8 编码都不认识,所以按照 UNICODE 的定义,就只好用统一的一个占位符 —— 0xFFFD(65533) 来表示。
为什么会出现“锟斤拷”?
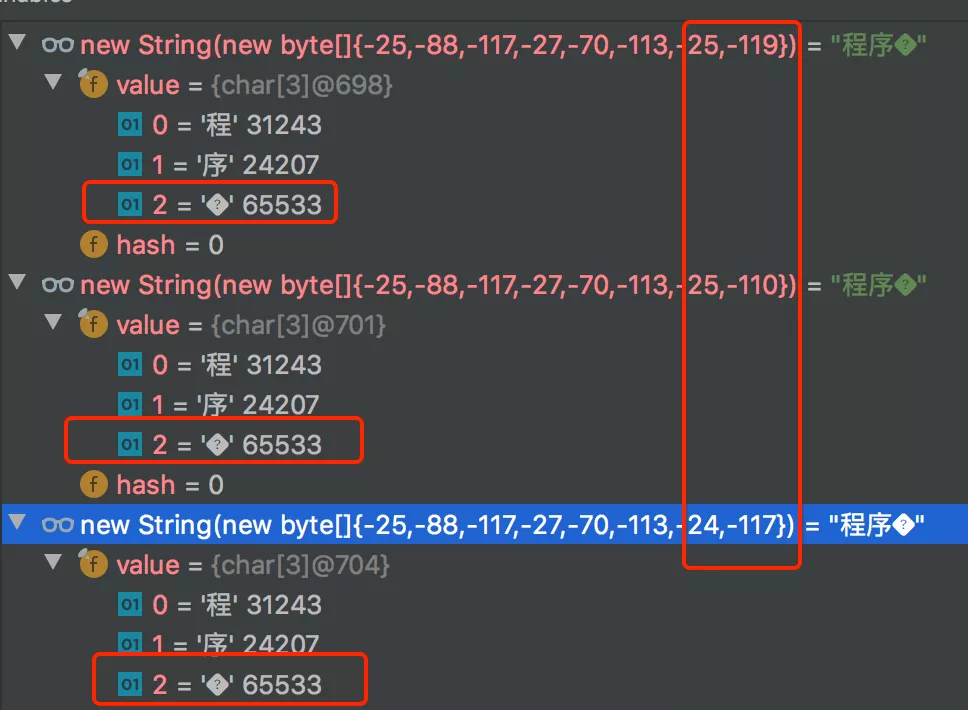
我们接着来看, 如下图所示,仍然从 “程序猿石头” 对应二进制编码截取部分:

上图中,第 18 行的字节数组 new byte[] {-25, -119, -25, -116},UTF-8 恰好都不认识,因此只能用占位符替换。

这种情况,在编码转换过程中确实也比较常见,如果双方没沟通清楚,确实很容易出现互相不认识的情况。

在中文系统中,常见的字符编码是 GBK,这个时候,因为大家没提前商量清楚,我就默认按照 GBK 给你编码看看。

惊不惊喜意不意外……
其实是因为,� 用 UTF-8 编码后变成了 0xEFBFBD(就是上面的字节数组 [-17, -65, -67]),两个连起来就是 0xEFBFBDEFBFBD,也就是上面的字节数组[-17, -65, -67, -17, -65, -67]。
而 GBK 编码依然采用双字节编码方案,因此上面的 6 字节 0xEFBFBDEFBFBD,就被拆成了 3 个 2 字节字符即 0xEFBF, 0xBDEF, 0xBFBD 对应 GBK 编码里面就是:锟(0xEFBF),斤(0xBDEF),拷(0xBFBD)。



锟斤拷(可向右滑动)
现在,你知道了吗?
最后,你知道开篇的五言绝句,另外的梗是来自哪里吗?
推荐阅读:
推荐一款,比 Navicat 还要好用,功能还很强大的 工具!
“华为天才少年”自制百大Up奖杯,网友:技术难度不高侮辱性极强
5T技术资源大放送!包括但不限于:C/C++,Linux,Python,Java,PHP,人工智能,单片机,树莓派,等等。在公众号内回复「1024」,即可免费获取!!