
【送书】联邦学习在视觉领域的应用,揭秘2020年AAAI人工智能创新应用奖获奖案例!

联邦学习是如何应用在视觉领域的?
本文会通过一个获得了2020年AAAI人工智能创新应用奖(也是第一个基于联邦学习的人工智能工业级奖项)的案例来向大家介绍!
本案例是联邦学习在视觉、物联网、安防领域的实际应用,对分散在各地的摄像头数据,通过联邦学习,构建一个联邦分布式的训练网络,使摄像头数据不需要上传,就可以协同训练目标检测模型,这样一方面确保用户的隐私数据不会泄露,另一方面充分利用各参与方的训练数据,提升机器视觉模型的识别效果。
以下内容节选自《联邦学习实战(全彩)》一书!

--正文--
在2012 年的ImageNet LSVRC 比赛中,AlexNet 凭借15.3% 的top-5 错误率夺得冠军后,以深度学习为代表的算法模型开始在视觉领域占据绝对的主导地位,并且在很多场景任务中达到、甚至超过人类的水平。
比如,2015 年,微软宣布在图像识别领域,以4.94% 的top-5 错误率超过人类的5.1% 水平;Google 最近发表在Nature Medicine上的一项新研究表明,通过AI 视觉算法能够根据患者的胸部CT 图像诊断出早期肺癌,与六位放射科医生相比,AI 的准确度更高,检测到的病例增加了5%,假阳性减少了11%,AUC(Area Under Curve,曲线下方的面积大小)达到94.4%。
除了算法上的不断提升,大数据和硬件算力的发展也促使人工智能在视觉领域出现爆发性的增长,传统的视觉算法处理流程如图1 所示。
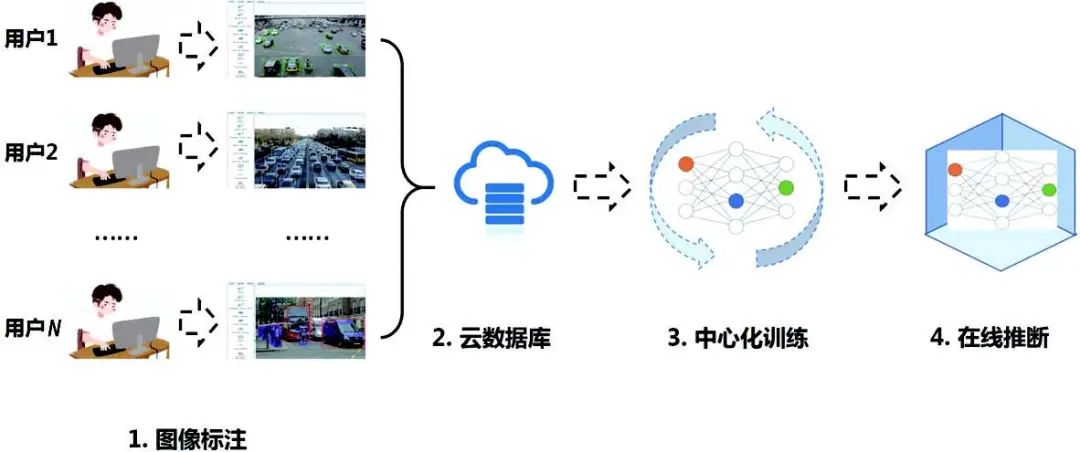
图1 中心化训练流程图
我们以目标检测任务为例,它由下面几个主要步骤构成:
首先,将收集来的数据集都集中存放在中心数据库中,并进行集中的图片数据预处理,包括图片数据清理、标注等。
然后,利用这些预处理的数据进行中心化的模型训练。
最后,将训练的模型部署到客户。
但当前的中心化训练模式使得视觉的落地和部署面临许多困难和挑战,具体来说,主要是受下面因素的影响:
• 数据隐私:在安防、医疗等领域,每一个客户采集的数据都具有高度的隐私性,这些敏感数据在用户没有授权的前提下,通常是被禁止上传的,因此,每一个客户端的数据都无法有效进行共享。另外,机器学习模型的效果非常依赖数据的数量和质量,数据的割裂导致我们只能利用本地的数据进行单点建模,也就是每一个设备单独利用本地数据进行训练,这种单点训练的模型效果也将明显下降。
• 模型更新:传统的处理方式需要将数据集中上传到中心数据库,进行统一的数据处理和模型训练,然后进行模型的评估和部署。在这个过程中,各个数据源之间,由于网络性能和设备性能的差异,导致数据的同步不一致,整个流程会持续较长的时间,因此对于具有实时响应的场景,这种中心化的训练模式无法满足当前的需求。
• 数据的不均匀:这种数据的不均匀性体现在每一个数据源得到的数据,它们的数据分布、数据质量和数据大小各不相同。
▊ 动机
上面说到了在传统的集中式目标检测训练中的几处不足,对模型提供方和数据提供方来说,安全(数据隐私)威胁是当前最为头疼和亟待解决的问题。
安全的威胁主要来自数据层面,包括:
• 数据提供方的数据源离开本地后,数据提供方就没办法跟踪这部分数据的用途了,也无法保证数据离开本地后不被其他人窃取。
• 一般来说,数据从离开数据提供方,到上传至中心数据库,会经过多个中转地,这就进一步增加了数据泄露的风险和问题排查的难度。
受此影响,当前的模型服务供应商和数据提供方,都急需一种新的模型训练方法:
一方面,保证数据不离开本地,这样能够使数据提供方确信数据的安全;另一方面,模型的训练和性能不会受到影响。
这两点都非常适合用联邦学习来解决,联邦学习的定义和提出的初衷,就是保证数据在不出本地的前提下,联合各参与方数据进行协同训练。
▊ Fedision-联邦视觉产品
前面介绍了利用联邦学习进行目标检测模型训练的动机,一个完整的联邦视觉(目标检测)产品的流程图如图2 所示。本节将对该产品进行概括的描述。
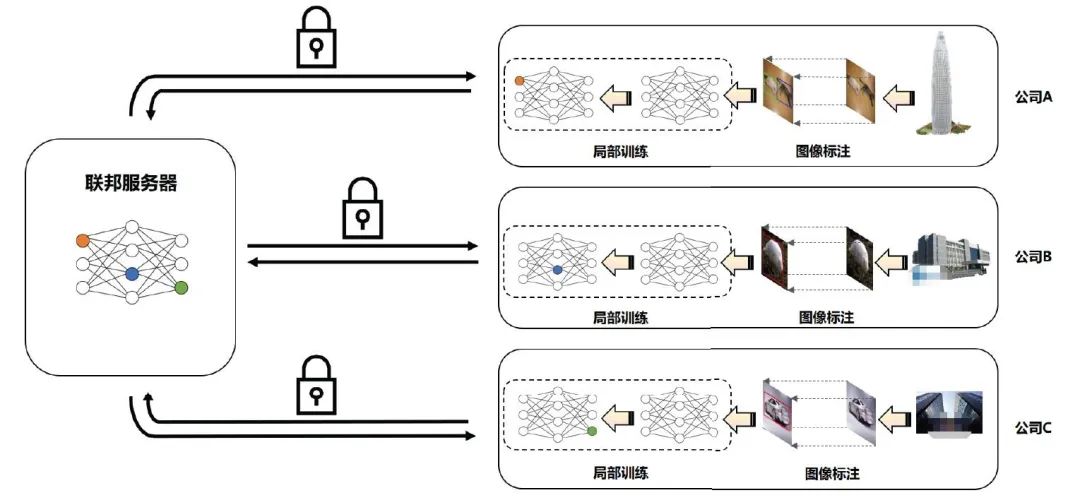
图2 横向联邦视觉产品流程图
图中描述了基于横向联邦学习实现的目标检测模型的工作流程,我们对本案例的基本设置进行如下综述:
• 不失一般性,本案例的联邦网络中的客户参与方共有三个:分别是公司A、B、C。服务端由微众的云服务器提供。
• 为了简化问题,本案例中的三个客户参与方提供的数据分布都比较均衡。
• 每一个客户方部署联邦学习框架后,其主要工作包括:对本地数据进行预处理;发起联邦学习训练任务;参与联邦学习任务;部署联邦学习模型在本地进行预测和推断。
• 服务端由微众的云服务器提供,其主要工作包括:实时监控客户端参与方的连接情况;对上传的客户端模型进行聚合;挑选客户端参与客户端本地训练;上传全局模型。
• 经过联邦学习更新后的全局模型,有两个用途:
第一, 可以分发到当前联邦网络的客户端参与方(即图中的公司A、B、C),进行本地部署预测,使得联邦学习的参与方受益;
第二, 如果新的全局模型效果能达到SOTA 水平,在经过参与方的协商同意后,还可以将新的联邦全局模型以开源或者商业售卖的形式,提供给其他厂商进行部署。
基于联邦学习构建的目标检测视觉模型,相比于集中式的目标检测模型,有下面的优势和好处:
• 隐私性:从隐私角度,联邦学习确保数据的产生、数据的处理都在本地进行。相比集中式训练,数据的隐私安全大为提高。
• 效率:从效率上来说,传统的集中式训练,需要等待所有数据提供方的数据上传后,才进行统一的数据处理,再进行集中式的模型训练和模型评估,最后部署新模型,这个流程的等待时间比较长。而联邦学习的训练,由于每一个客户参与方从数据收集到数据处理都独立完成,且都有发起联邦学习的权力,只要发起联邦学习请求,就能进行模型训练,因此每一个客户方部署新模型的速度都加快了许多。
• 费用:在集中式训练中,将原始数据(图像、视频)上传到服务端会消耗非常多的网络带宽资源。而联邦视觉模型上传的是模型参数,模型参数的传输量要比数据传输量小得多,从而能有效节省网络带宽,节约费用。
基于联邦学习实现目标检测产品是横向联邦的一个经典应用。本节我们将给出其详细的实现过程。本案例有基于Flask-SocketIO的Python 实现,也有基于FATE 的实现。最后,我们讨论基于Flask-SocketIO 的Python 实现。读者可以自行查阅基于FATE 的实现。
▊ Flask-SocketIO 基础
在本案例的实现中,我们将使用Python 语言和PyTorch 机器学习模型库,与书中第3章的实现不同,第3章使用普通函数调用的方式模拟服务端与客户端之间的通信,这里使用Flask-SocketIO 作为服务端和客户端之间的通信框架。此外,书中第16 章会具体介绍联邦学习中的通信机制和常用的Python 网络通信包。
通过Flask-SocketIO,我们可以轻松实现服务端与客户端的双向通信,Flask-SocketIO 库的安装非常方便,只需要在命令行中输入下面的命令即可:
![]()
• 服务端创建:先来初始化服务端,下面是初始化服务端的一段简短代码。

socketio.run() 是服务器的启动接口,它通过封装app.run() 标准实现。这段代码是创建socket 服务端最简短的代码,服务器启动后没有实现任何功能,为了能响应连接的客户端请求,我们在服务端中定义必要的处理函数。socketIO 的通信基于事件,不同名称的事件对应不同的处理函数,在处理函数的定义前,用on 装饰器指定接收事件的名称,这样事件就与处理函数一一对应,如下我们创建了一个“my event”事件,该事件对应的处理函数是“test_message”。

事件创建后,服务器处在监听状态,等待客户端发送“my event”的请求。由于socketIO 实现的是双向通信,除了能添加事件等待客户端响应,服务端也可以向客户端发送请求,服务端向客户端发送消息使用send 函数或是emit 函数(对于未命名的事件使用send,已经命名的事件用emit),如上面的代码中,当服务端接收到客户端的“my event”事件请求后,向客户端反向发送“my response”的请求。
• 客户端:客户端的应用程序设计相对服务端要灵活很多,我们可以使用JavaScript、C++、Java 和Swift 中的任意socketIO 官方客户端库或与之兼容的客户端,来与上面的服务端建立连接。这里,我们使用socketIO-client 库来创建一个client。

先利用socketIO 函数构造一个客户端,构造函数需要提供连接的服务端的IP 和端口信息。然后利用on 连接事件“my response”和处理函数“test_response”,发送“my event”事件,等待服务端的事件响应。
鉴于本书的篇幅限制,我们不在此对Flask-SocketIO 做更多的讲述,读者如果想深入了解Flask-SocketIO 的实现和使用,可以参见Flask-SocketIO 的官方文档。联邦学习的过程是联邦服务端与联邦客户端之间不断进行参数通信的过程,图3 展示了联邦客户端与联邦服务端的详细通信过程。
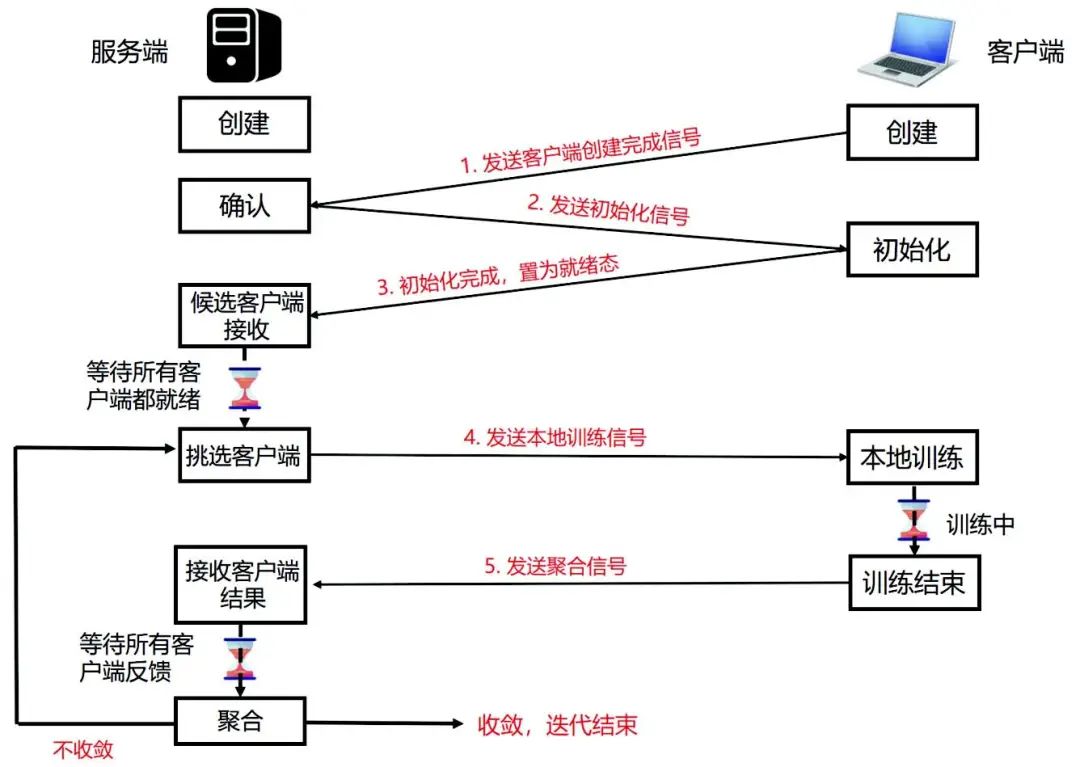
图3 联邦客户端与联邦服务端的通信过程
接下来,书中会分别从服务端角度和客户端角度简要分析其构建和实现过程,如果想要了解后面的完整案例,推荐阅读《联邦学习实战(全彩)》一书。


▊《联邦学习实战》
杨强 黄安埠 刘洋 陈天健 著
经典案例一手实践
配套Python代码和丰富线上教学资源(含视频)
本书以实战为主(包括对应用案例的深入讲解和代码分析),兼顾对理论知识的系统总结。
全书由五部分共19 章构成。第一部分简要介绍了联邦学习的理论知识;第二部分介绍如何使用Python 和FATE 进行简单的联邦学习建模;第三部分是联邦学习的案例分析,筛选了经典案例进行讲解,部分案例用Python 代码实现,部分案例采用FATE 实现;第四部分主要介绍和联邦学习相关的高级知识点,包括联邦学习的架构和训练的加速方法等;第五部分是回顾与展望。本书适合对联邦学习和隐私保护感兴趣的高校研究者、企业研发人员阅读。
福利来了
评论区留言送书! 你在学习深度学习的过程中遇到过哪些问题?希望读者后续分享哪个系列的干货?对于用心留言(20字以上)点赞前8名的同学将送《联邦学习》一本,到5月23日22:00截止。 (为防止刷量,5月23日18时对留言前20名做个截图作为证据,与最终点赞数量作对比。) 往期精彩回顾
本站qq群851320808,加入微信群请扫码: