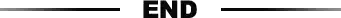华为智能化战略,国产AI基础设施突破


华为在计算、网络、存储等领域的综合优势明显,从器件级、节点级、集群级和业务级全面提升系统可靠性,将大模型训练稳定性从天级提升到月级。
1.1.算力、运力、存力全方位发展,国产算力瓶颈有望突破
大模型进入万亿参数时代,单体服务器算力有限,需要将大量杰斯安服务器、存储器等通过网络相连,打造大规模算力集群。通过对处理器、网络架构和存储性能的全面优化,为大模型训练提供高性能、高带宽、低延迟的智算能力支撑。
关于算力发展的突破方向,华为改变了传统的服务器堆叠模式,以系统架构创新的思路,着力打造 AI 集群,实现算力、运力、存力的一体化设计,突破算力瓶颈。
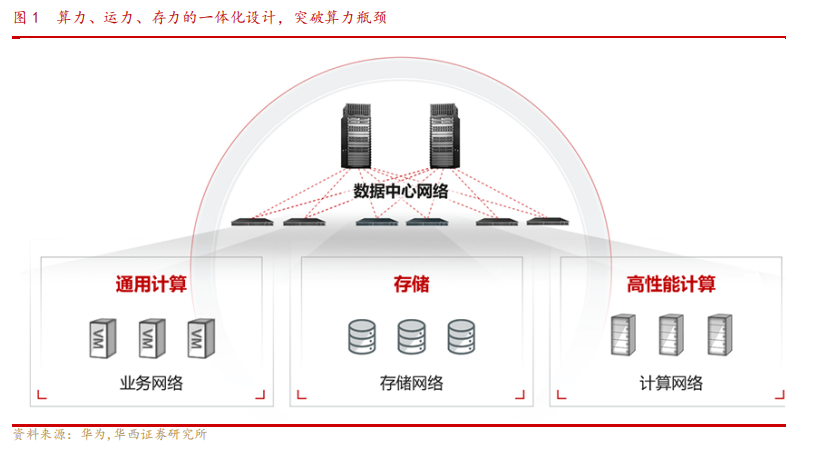
1.2.昇腾 AI 计算集群打造超大规模无收敛集群组网
华为昇腾 AI 计算集群采用全新的华为星河 AI 智算交换机 CloudEngine XH16800,借助其高密的800GE端口能力,两层交换网络即可实现2250节点(等效于 18000 张卡)超大规模无收敛集群组网。
算力方面,华为通过架构和系统创新,构筑面向多场景的大算力平台,突破 AI 大模型训练的算力瓶颈。
存力方面,华为发布领先的 AI 知识库存储 OceanStor A800, 以创新架构构建高性能数据存储。
运力方面,华为发布业界首款高运力 DCN 星河 AI 智算交换机,和业界容量最大的超宽全光智能 DCI 方案,以大规模,大容量网络运力释放大算力。
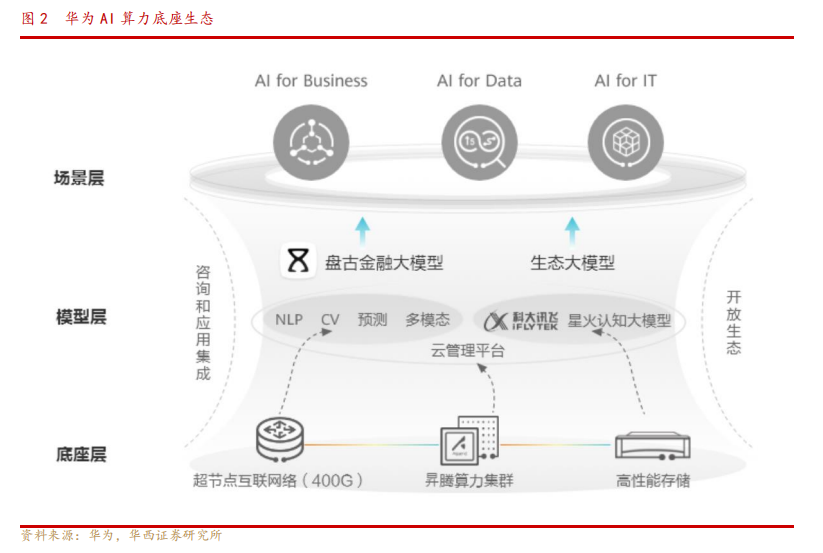
1.3.昇腾芯片+ MindSpore 生态,全球算力第二极
华为深耕 AI 算力,推出了完全自主架构的昇腾 AI 处理器 910 (Ascend 910),Ascend 910 采用华为自研达芬奇架构。
昇腾 910 的半精度 (FP16)算力达到 256 Tera-FLOPS,整数精度(NT8) 算力达到 512 Tera-OPS,且芯片最大功耗仅为 310W,比此前设计规格的 350W 更低。

除了超高的算力之外,昇腾 910 还拥有高集成度和高速互联的特性。它集成了CPU、DVPP 和任务管理器,因此它能独立完成 AI 训练流程。同时昇腾 910 集成了 HCCS、PCIe 和 RoCE 三种高速接口。其中最新的 PCle 吞吐量相比上一代翻了一倍。这些特性共同组成了算力最强的昇腾 910 处理器。
配合昇腾 910,华为采用全栈全场景AI 计算框架 MindSpore,打造昇腾 AI 基础软硬件平台, 携手伙伴共建昇腾 AI 计算产业。
1)硬件方面,华为采用自有硬件+硬件生态伙伴方式,为终端客户提供多样化算力选择。
2)软件方面,开发、销售自有知识产权的应用程序、软件、垂直细分应用等产品,能对接昇腾产品,有能力二次开发的软件伙伴,相关上市公司包括:智洋创新等。