
用于实现3D目标识别的新数据集
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

来自ObjectNet3D的示例图像,其中2D对象与3D形状对应
ObjectNet3D是一个大型数据库,其中图像中的对象与3D形状对应,并且这种对应为每个2D对象提供了准确的3D姿态注释和最接近的3D形状注释。该数据集的规模使得计算机视觉任务取得重大进展,例如从2D图像识别对象的3D姿势和3D形状。

3D形状检索的示例。绿色框表示选定的形状。下排说明了两种情况,在前5种形状中未找到相似的形状
为了构建此数据库,斯坦福大学的研究人员诉诸于现有图像存储库中的图像,并提出了一种将3D形状(可从现有3D形状存储库中获得)与这些图像中的对象对应的方法。
在他们的工作中,研究人员仅考虑刚性对象类别,他们可以从网络中收集大量3D形状。以下是类别的完整列表:
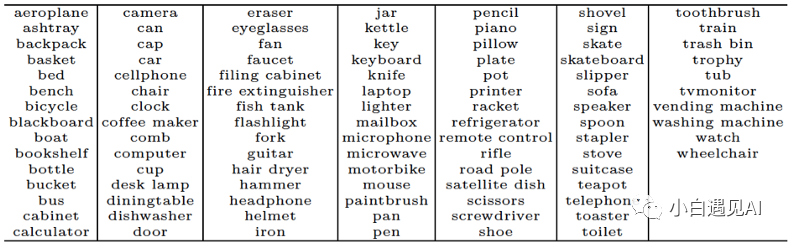
ObjectNet3D中的对象类别
从ImageNet数据集收集了2D图像,此外,通过Google图像搜索收集了ImageNet数据集未充分涵盖的类别。3D形状是从Trimble 3D Warehouse和ShapeNet存储库中获得的。然后,使用相机模型将图像中的对象与3D形状对应。最后,将3D注释提供给2D图像中的对象。所得数据集可用于对象提议生成,2D对象检测,联合2D检测和3D对象姿态估计以及基于图像的3D形状检索。
MVTec ITODD

来自所有传感器的数据集的示例场景。第一行:灰度相机。下排:高质量(左)和低质量(右)3D传感器的Z和灰度图像
MVTec ITODD是用于3D对象检测和姿态估计的数据集,重点关注工业设置和应用。它包含布置在800多个场景中的28个对象,并以其严格的3D变换标记为地面实况。场景由两个工业3D传感器和三个灰度相机进行观察,从而可以评估适用于3D,图像或组合形式的方法。MVTec Software GmbH的数据集创建者选择使用灰度相机,因为它们在工业设置中更为突出。
如数据集描述中所述,选择对象时应使它们在表面反射率,对称性,复杂性,平面度,细节,紧密度和大小方面覆盖一系列不同的值。这是MVTec ITODD包含的所有对象的图像及其名称:

数据集中使用的28个对象的图像
对于每个对象,只有一个实例的场景和有多个实例的场景(例如,模拟箱拣选)可用。每个场景使用每个3D传感器采集一次,每个灰度相机采集两次:一次带有随机投影图案,一次没有随机投影图案。
最后,对于所有对象,都可以使用手动创建的CAD模型来训练检测方法。基于高质量3D传感器的3D数据,使用半手动方法标记了地面真相。
该数据集为工业场景中3D对象的检测和姿态估计提供了很好的基准。
T-LESS
图片数量:每三个传感器会传回3900张训练图片+10000张测试图片
物体数量:30
年份:2017

T-LESS测试图像的数据示例(左),在地面真实6D姿势下(右)覆盖有彩色3D对象模型。同一对象的实例具有相同的颜色
T-LESS是一个新的公共数据集,用于估计无纹理的刚性物体的6D姿势,即平移和旋转。该数据集包含30个与行业相关的对象,这些对象没有明显的纹理并且没有可辨别的颜色或反射率属性。该数据集的另一个独特属性是某些对象是其他对象的一部分。 T-LESS背后的研究人员已经选择了不同的方法来训练图像和测试图像。因此,该数据集中的训练图像在黑色背景下描绘了单个对象,而测试图像则来自二十个场景,且复杂程度不同。以下是训练和测试图像的示例:

上:训练图像和30个对象的3D模型。下:在地面真实姿势下用彩色3D对象模型覆盖的20个场景的测试图像
所有的训练和测试图像都是通过三个同步传感器捕获的,其中包括结构化光和飞行时间RGB-D传感器以及高分辨率RGB相机。
最后,为每个对象提供两种类型的3D模型:1)手动创建的CAD模型,以及2)半自动重建的模型。
该数据集对于评估6D对象姿态估计,2D对象检测和分割,3D对象重建的方法非常有用。考虑到来自三个传感器的图像的可用性,对于给定的问题,也有可能研究不同输入方式的重要性。
Falling Things
图片数量:61500
物体数量:21个居家物品
年份:2018

FAT数据集的样本图像
Falling Things数据集为加速研究对象检测和姿态估计以及分割,深度估计和传感器模态提供了绝佳机会。
写在最后
3D对象识别具有多个重要应用,但是该领域的进展受到可用数据集的限制。幸运的是,近年来引入了几个新的3D对象识别数据集。尽管它们具有不同的规模,重点和特征,但是每个数据集都为改进当前3D对象识别系统做出了重要贡献。