
如何设计与实现一个 IM 消息系统?
点击上方 蓝字 关注我们!
Java,Python,C/C++,Linux,PHP,Go,C#,QT,大数据,算法,软件教程,前端,简历,毕业设计等分类,资源在不断更新中... 点击领取!


来源:developer.aliyun.com/article/253242
前言 架构设计 传统架构 vs 现代架构 Timeline模型 消息存储模型 消息同步模型 消息库设计 数据库选型 架构实现 后记
前言
IM全称是『Instant Messaging』,中文名是即时通讯。在这个高度信息化的移动互联网时代,生活中IM类产品已经成为必备品,比较有名的如钉钉、微信、QQ等以IM为核心功能的产品。
当然目前微信已经成长为一个生态型产品,但其核心功能还是IM。还有一些非以IM系统为核心的应用,最典型的如一些在线游戏、社交应用,IM也是其重要的功能模块。
可以说,带有社交属性的应用,IM功能一定是必不可少的。
IM系统在互联网初期即存在,其基础技术架构在这十几年的发展中更新迭代多次,从早期的CS、P2P架构,到现在后台已经演变为一个复杂的分布式系统,涉及移动端、网络、安全和存储等技术的方方面面。
其支撑的规模也从早期的少量日活,到现在微信这个巨头最新公布的达到9亿的日活的体量。
IM系统中最核心的部分是消息系统,消息系统中最核心的功能是消息的同步和存储:
消息的同步 :将消息完整的、快速的从发送方传递到接收方,就是消息的同步。消息同步系统最重要的衡量指标就是消息传递的实时性、完整性以及能支撑的消息规模。从功能上来说,一般至少要支持在线和离线推送,高级的IM系统还支持『多端同步』。 消息的存储 :消息存储即消息的持久化保存,这里不是指消息在客户端本地的保存,而是指云端的保存,功能上对应的就是『消息漫游』。『消息漫游』的好处是可以实现账号在任意端登陆查看所有历史消息,这也是高级IM系统特有的功能之一。
本篇文章内容主要涉及IM系统中的消息系统架构,会介绍一种基于TableStore构建的消息同步以及存储系统的架构实现,能够支持消息系统中的高级特性『多端同步』以及『消息漫游』。在性能和规模上,能够做到全量消息云端存储,百万TPS以及毫秒级延迟的消息同步能力。
架构设计
本章主要会介绍基于TableStore的现代IM消息系统的架构设计,在详细介绍架构设计之前,会先介绍一种Timeline逻辑模型,来抽象和简化对IM消息同步和存储模型的理解。
理解了Timeline模型后,会介绍如何基于此模型对消息的同步以及存储进行建模。基于Timeline模型,在实现消息同步和存储时还会有各方面的技术权衡,例如如何对消息同步常见的读扩散和写扩散两种模型进行对比和选择,以及针对Timeline模型的特征如何来选择底层数据库。
传统架构 vs 现代架构
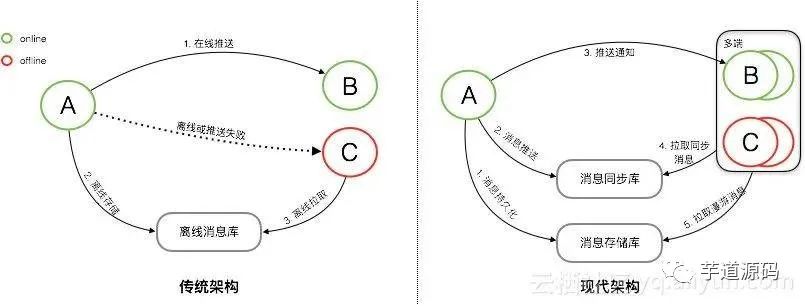
上图是消息系统传统架构与现代架构的简单对比。
传统架构下,消息是先同步后存储。对于在线的用户,消息会直接实时同步到在线的接收方,消息同步成功后,并不会进行持久化。而对于离线的用户或者消息无法实时同步成功时,消息会持久化到离线库,当接收方重新连接后,会从离线库拉取所有未读消息。当离线库中的消息成功同步到接收方后,消息会从离线库中删除。传统的消息系统,服务端的主要工作是维护发送方和接收方的连接状态,并提供在线消息同步和离线消息缓存的能力,保证消息一定能够从发送方传递到接收方。服务端不会对消息进行持久化,所以也无法支持消息漫游。
现代架构下,消息是先存储后同步。先存储后同步的好处是,如果接收方确认接收到了消息,那这条消息一定是已经在云端保存了。并且消息会有两个库来保存,一个是消息存储库,用于全量保存所有会话的消息,主要用于支持消息漫游。另一个是消息同步库,主要用于接收方的多端同步。消息从发送方发出后,经过服务端转发,服务端会先将消息保存到消息存储库,后保存到消息同步库。完成消息的持久化保存后,对于在线的接收方,会直接选择在线推送。但在线推送并不是一个必须路径,只是一个更优的消息传递路径。对于在线推送失败或者离线的接收方,会有另外一个统一的消息同步方式。接收方会主动的向服务端拉取所有未同步消息,但接收方何时来同步以及会在哪些端来同步消息对服务端来说是未知的,所以要求服务端必须保存所有需要同步到接收方的消息,这是消息同步库的主要作用。对于新的同步设备,会有消息漫游的需求,这是消息存储库的主要作用,在消息存储库中,可以拉取任意会话的全量历史消息。
以上是传统架构和现代架构的一个简单的对比,现代架构上整个消息的同步和存储流程,并没有变复杂太多,但是其能实现多端同步以及消息漫游。现代架构中最核心的就是两个消息库『消息同步库』和『消息存储库』,是消息同步和存储最核心的基础。而本篇文章接下来的部分,都是围绕这两个库的设计和实现来展开。
Timeline模型
在分析『消息同步库』和『消息存储库』的设计和实现之前,在本章会先介绍一个逻辑模型-Timeline。Timeline模型会帮助我们简化对消息同步和存储模型的理解,而消息库的设计和实现也是围绕Timeline的特性和需求来展开。
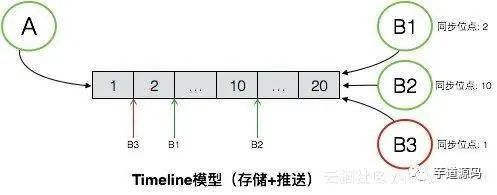
如图是Timeline模型的一个抽象表述,Timeline可以简单理解为是一个消息队列,但这个消息队列有如下特性:
每个消息拥有一个顺序ID(SeqId),在队列后面的消息的SeqId一定比前面的消息的SeqId大,也就是保证SeqId一定是增长的,但是不要求严格递增。 新的消息永远在尾部添加,保证新的消息的SeqId永远比已经存在队列中的消息都大。 可根据SeqId随机定位到具体的某条消息进行读取,也可以任意读取某个给定范围内的所有消息。
有了这些特性后,消息的同步可以拿Timeline来很简单的实现。图中的例子中,消息发送方是A,消息接收方是B,同时B存在多个接收端,分别是B1、B2和B3。A向B发送消息,消息需要同步到B的多个端,待同步的消息通过一个Timeline来进行交换。A向B发送的所有消息,都会保存在这个Timeline中,B的每个接收端都是独立的从这个Timeline中拉取消息。每个接收端同步完毕后,都会在本地记录下最新同步到的消息的SeqId,即最新的一个位点,作为下次消息同步的起始位点。服务端不会保存各个端的同步状态,各个端均可以在任意时间从任意点开始拉取消息。
消息漫游也是基于Timeline,和消息同步唯一的区别是,消息漫游要求服务端能够对Timeline内的所有数据进行持久化。
基于Timeline,从逻辑模型上能够很简单的理解在服务端如何去实现消息同步和存储,并支持多端同步和消息漫游这些高级功能。落地到实现的难点主要在如何将逻辑模型映射到物理模型,Timeline的实现对数据库会有哪些要求?我们应该选择何种数据库去实现?这些是接下来会讨论到的问题。
消息存储模型
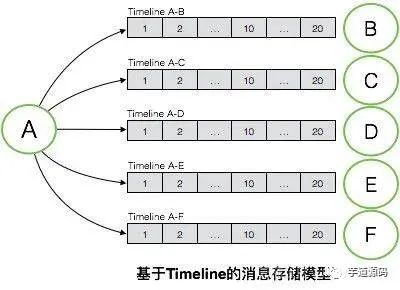
如图是基于Timeline的消息存储模型,消息存储要求每个会话都对应一个独立的Timeline。如图例子所示,A与B/C/D/E/F均发生了会话,每个会话对应一个独立的Timeline,每个Timeline内存有这个会话中的所有消息,服务端会对每个Timeline进行持久化。服务端能够对所有会话Timeline中的全量消息进行持久化,也就拥有了消息漫游的能力。
消息同步模型
消息同步模型会比消息存储模型稍复杂一些,消息的同步一般有读扩散和写扩散两种不同的方式,分别对应不同的Timeline物理模型。
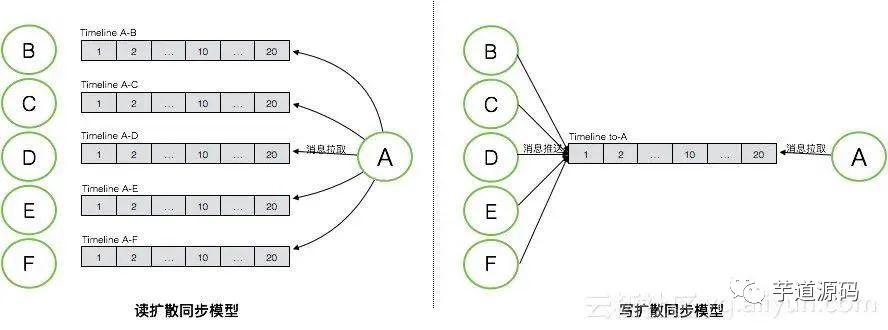
如图是读扩散和写扩散两种不同同步模式下对应的不同的Timeline模型,按图中的示例,A作为消息接收者,其与B/C/D/E/F发生了会话,每个会话中的新的消息都需要同步到A的某个端,看下读扩散和写扩散两种模式下消息如何做同步。
读扩散 :消息存储模型中,每个会话的Timeline中保存了这个会话的全量消息。读扩散的消息同步模式下,每个会话中产生的新的消息,只需要写一次到其用于存储的Timeline中,接收端从这个Timeline中拉取新的消息。优点是消息只需要写一次,相比写扩散的模式,能够大大降低消息写入次数,特别是在群消息这种场景下。但其缺点也比较明显,接收端去同步消息的逻辑会相对复杂和低效。接收端需要对每个会话都拉取一次才能获取全部消息,读被大大的放大,并且会产生很多无效的读,因为并不是每个会话都会有新消息产生。 写扩散 :写扩散的消息同步模式,需要有一个额外的Timeline来专门用于消息同步,通常是每个接收端都会拥有一个独立的同步Timeline,用于存放需要向这个接收端同步的所有消息。每个会话中的消息,会产生多次写,除了写入用于消息存储的会话Timeline,还需要写入需要同步到的接收端的同步Timeline。在个人与个人的会话中,消息会被额外写两次,除了写入这个会话的存储Timeline,还需要写入参与这个会话的两个接收者的同步Timeline。而在群这个场景下,写入会被更加的放大,如果这个群拥有N个参与者,那每条消息都需要额外的写N次。写扩散同步模式的优点是,在接收端消息同步逻辑会非常简单,只需要从其同步Timeline中读取一次即可,大大降低了消息同步所需的读的压力。其缺点就是消息写入会被放大,特别是针对群这种场景。
在IM这种应用场景下,通常会选择写扩散这种消息同步模式。IM场景下,一条消息只会产生一次,但是会被读取多次,是典型的读多写少的场景,消息的读写比例大概是10:1。若使用读扩散同步模式,整个系统的读写比例会被放大到100:1。一个优化的好的系统,必须从设计上去平衡这种读写压力,避免读或写任意一维触碰到天花板。所以IM系统这类场景下,通常会应用写扩散这种同步模式,来平衡读和写,将100:1的读写比例平衡到30:30。当然写扩散这种同步模式,还需要处理一些极端场景,例如万人大群。针对这种极端写扩散的场景,会退化到使用读扩散。一个简单的IM系统,通常会在产品层面限制这种大群的存在,而对于一个高级的IM系统,会采用读写扩散混合的同步模式,来满足这类产品的需求。
消息库设计
基于Timeline模型,以及Timeline模型在消息存储和消息同步的应用,我们看下消息同步库和消息存储库的设计。
 image
image
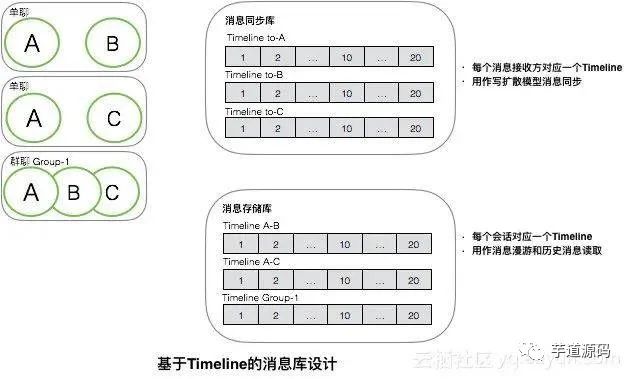
如图是基于Timeline的消息库设计。
消息同步库 :消息同步库用于存储所有用于消息同步的Timeline,每个Timeline对应一个接收端,主要用作写扩散模式的消息同步。这个库不需要永久保留所有需要同步的消息,因为消息在同步到所有端后其生命周期就可以结束,就可以被回收。但是如前面所介绍的,一个实现简单的多端同步消息系统,在服务端不会保存有所有端的同步状态,而是依赖端自己主动来做同步。所以服务端不知道消息何时可以回收,通常的做法是为这个库里的消息设定一个固定的生命周期,例如一周或者一个月,生命周期结束可被淘汰。 消息存储库 :消息存储库用于存储所有会话的Timeline,每个Timeline包含了一个会话中的所有消息。这个库主要用于消息漫游时拉取某个会话的所有历史消息,也用于读扩散模式的消息同步。
消息同步库和消息存储库,对数据库有不同的要求,如何对数据库做选型,在下面会讨论。
数据库选型
消息系统最核心的两个库是消息同步库和消息存储库,两个库对数据库有不同的要求:
| 消息同步库 | 消息存储库 | |
|---|---|---|
| 数据模型 | Timeline模型 | Timeline模型 |
| 写能力 | 高并发写,十万级TPS | 高并发写,少量读,万级TPS |
| 读能力 | 高并发范围读,十万级TPS | 少量范围读,千级TPS |
| 存储规模 | 保存一段时间内的同步消息,TB级。保留千万级的Timeline规模。 | 保存全量消息,百TB级。保留亿级的Timeline规模。 |
总结下来,对数据库的要求有如下几点:
表结构设计能够满足Timeline模型的功能要求:不要求关系模型,能够实现队列模型,并能够支持生成自增的SeqId。 能够支持高并发写和范围读,规模在十万级TPS。 能够保存海量数据,百TB级。 能够为数据定义生命周期。
阿里云表格存储(TableStore)是基于LSM存储引擎的分布式NoSQL数据库,支持百万TPS高并发读写,PB级数据存储,数据支持TTL,能够很好的满足以上需求,并且支持自增列,能够非常完美的设计和实现Timeline的物理模型。
架构实现
千言万语,不如直接看代码,具体示例代码可参考https://github.com/aliyun/tablestore-timeline/blob/master/src/test/java/examples/scene/SimpleIM.java。
后记
这篇文章主要介绍了现代IM系统中消息推送和存储架构的实现,基于逻辑的Timeline模型,我们可以很清晰明了的理解整个消息推送和存储的架构。基于TableStore,可以非常简单的实现Timeline模型,其中自增列功能,完美的匹配了Timeline模型中所需要的最关键的SeqId自增。
TableStore(表格存储)是阿里云自主研发的专业级分布式NoSQL数据库,是基于共享存储的高性能、低成本、易扩展、全托管的半结构化数据存储平台,支撑互联网和物联网数据的高效计算与分析。IM系统的消息推送和存储场景,是TableStore在社交领域的重要应用之一。
- END -往期推荐
END
若觉得文章对你有帮助,随手转发分享,也是我们继续更新的动力。
长按二维码,扫扫关注哦
✬「C语言中文网」官方公众号,关注手机阅读教程 ✬

目前收集的资料包括: Java,Python,C/C++,Linux,PHP,go,C#,QT,git/svn,人工智能,大数据,单片机,算法,小程序,易语言,安卓,ios,PPT,软件教程,前端,软件测试,简历,毕业设计,公开课 等分类,资源在不断更新中...