
基于GAN的说话人驱动:talking face generation解读
https://zhuanlan.zhihu.com/p/429965015
01
Diffcults:
Robust generation: 模型需要适应不同角度、不同姿态的驱动人脸输入,不同噪声条件下的音频输入,甚至跨语言合成 音视频之间的一致性问题:如何准确地保证唇形、头部姿态、面部表情和语音内容的一致性?语音信号其实很难去映射头部姿态、面部表情等信息 生成的视频的逼真度:1) 视频帧的逼真度(高分辨率、高保真度); 2) 视频序列的逼真度
02
2、DAVS: Talking Face Generation by Adversarially Disentangled Audio-Visual Representation (AAAI 2019)
2.1 Motivation
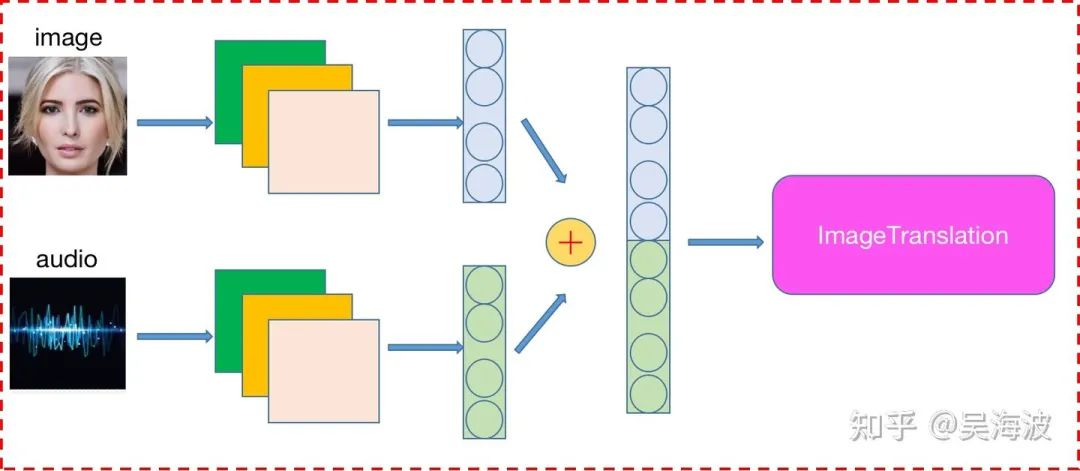
2.2 Learning Joint Audio-Visual Representation(本质上都是音频信号学习)
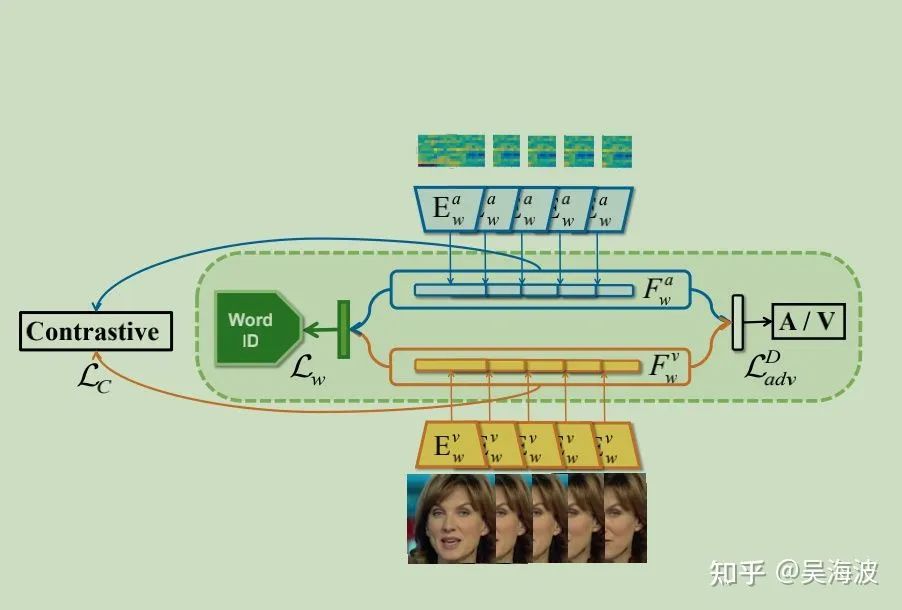
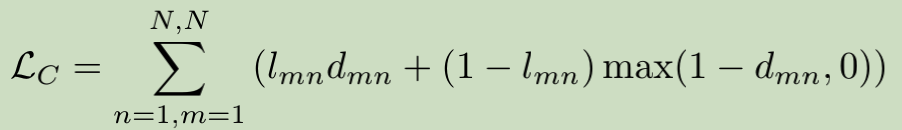
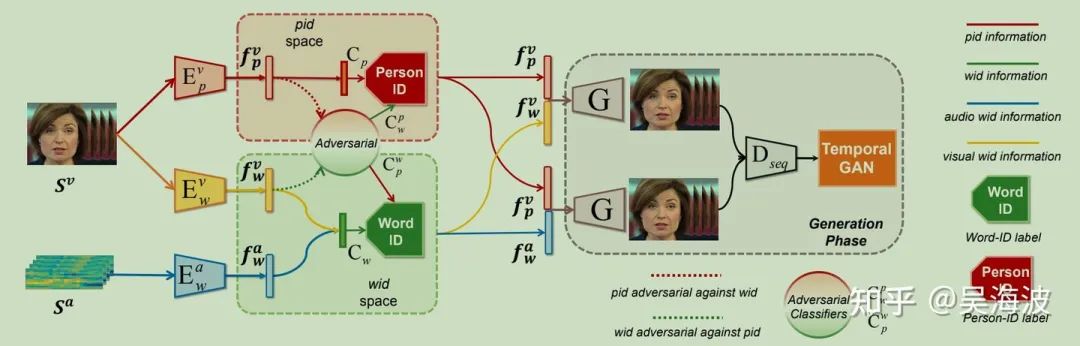
2.3 Adversarial Training for Latent Space Disentangling (全文亮点)
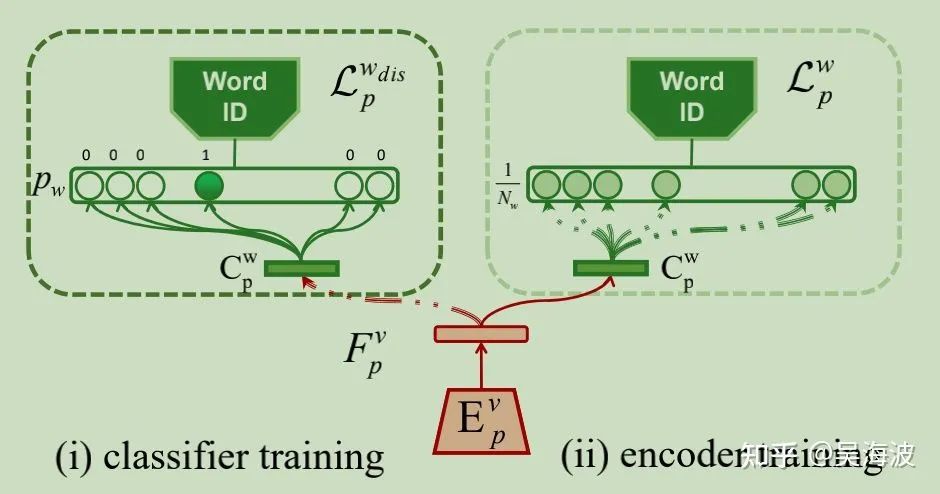
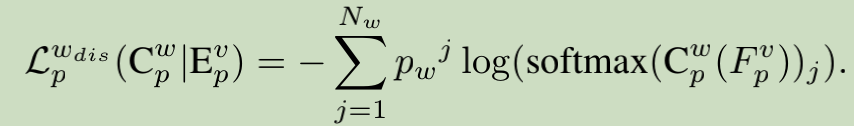
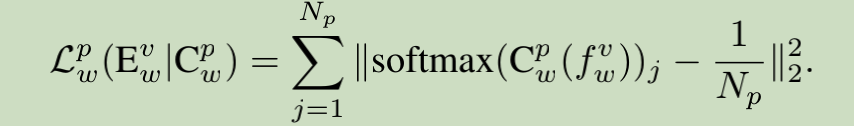

2.4 Inference: Arbitary-Subject Talking Face Generation
帧级别重构损失:
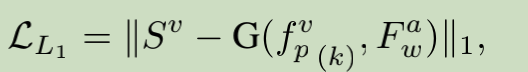
序列级别的GAN loss(时序GAN):
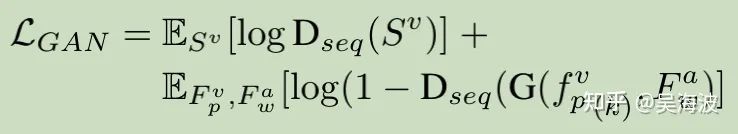
2.5 Abalation Study
GAN loss作用:
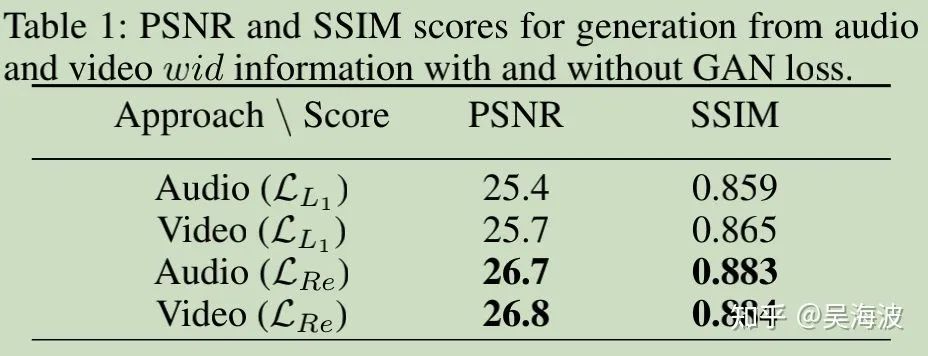
wid训练中各个loss作用:

Feature disentangle作用:

Results



2.6 小结
3、MakeItTalk: Speaker-Aware Talking-Head Animation (SIGGRAPH 2020)
3.1 Motivation
方法整体框架图如下:(主要分成4个步骤)
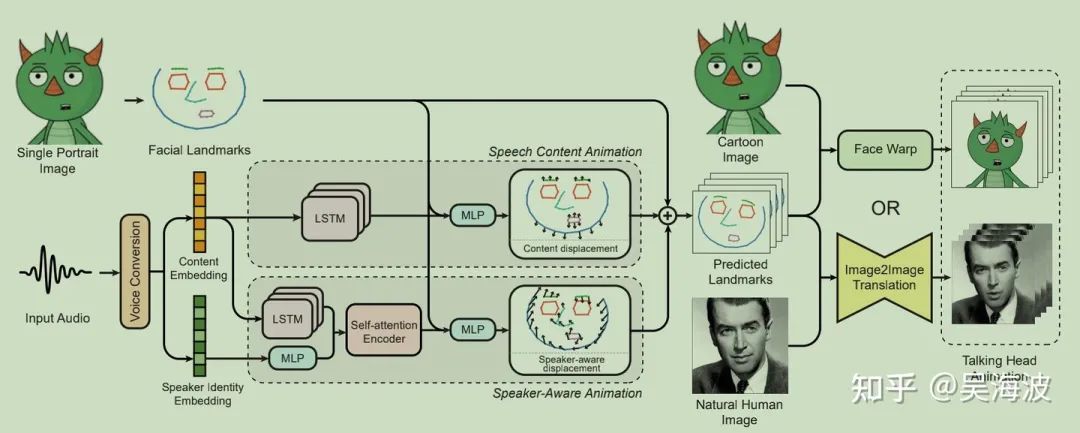
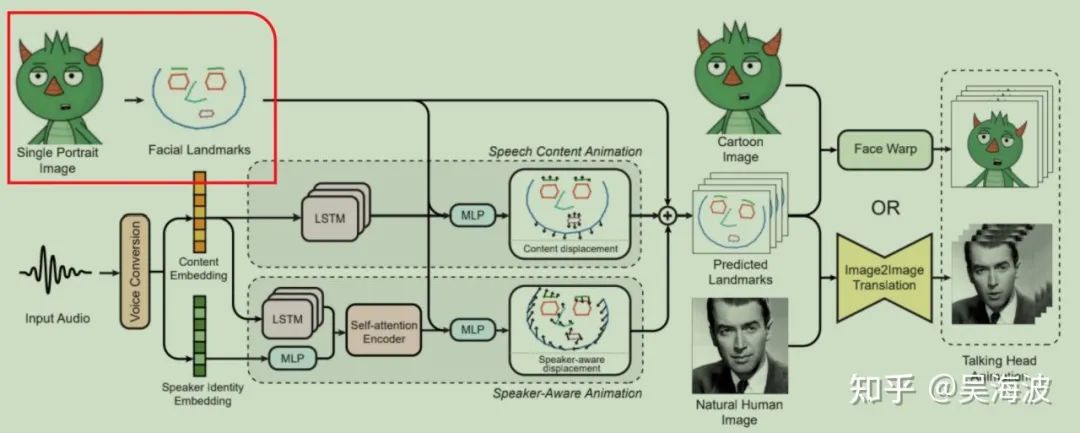
3.2 人脸关键点预提取
利用预训练的人脸关键点检测模型提取68个人脸的3d关键点坐标
3.3 音频特征分离
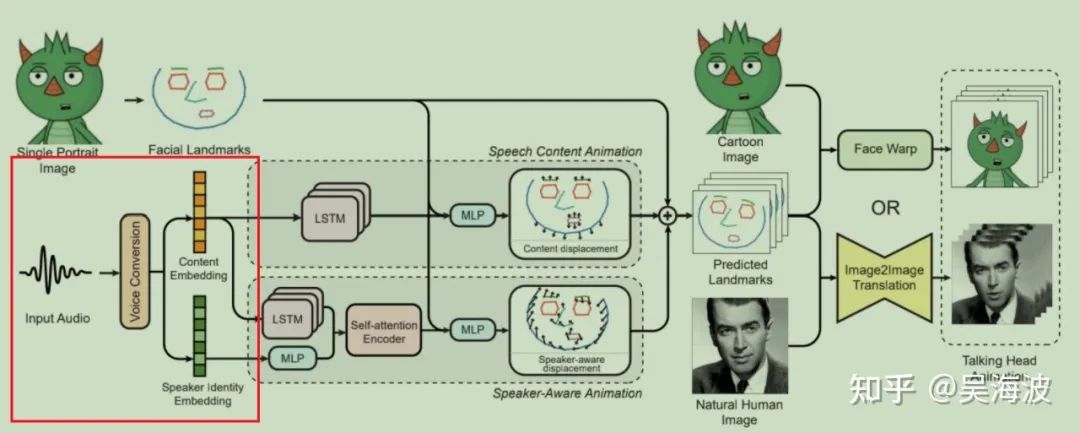
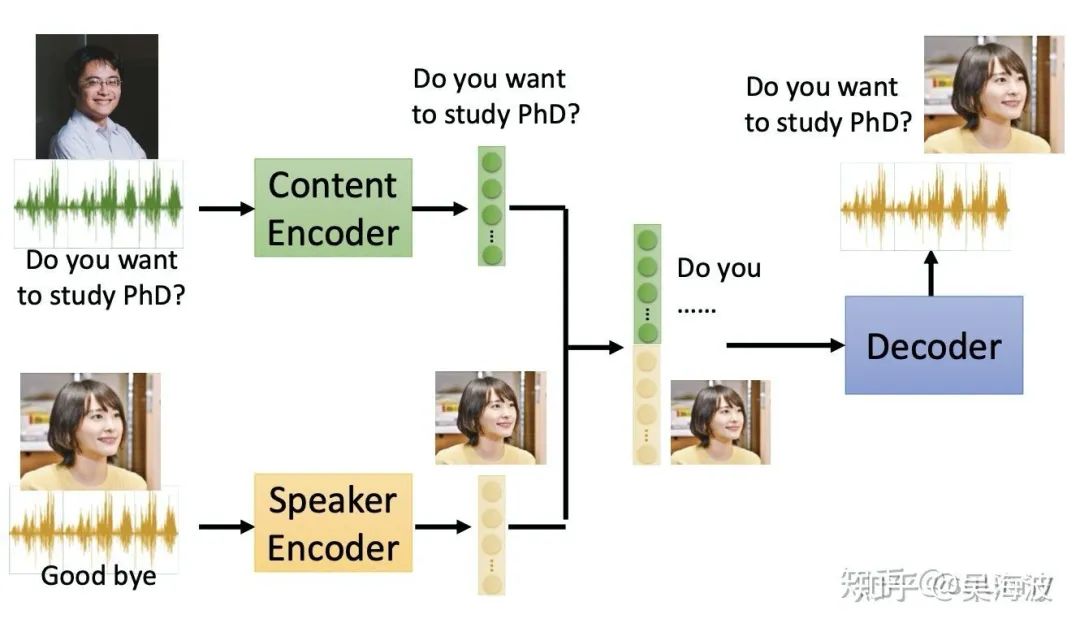
音频特征分离需要用到voice conversion (VC):将一个人的声音变成另外一个人的声音(变声器),该模块需要把音频内容信息和说话者身份信息完全剥离开来。
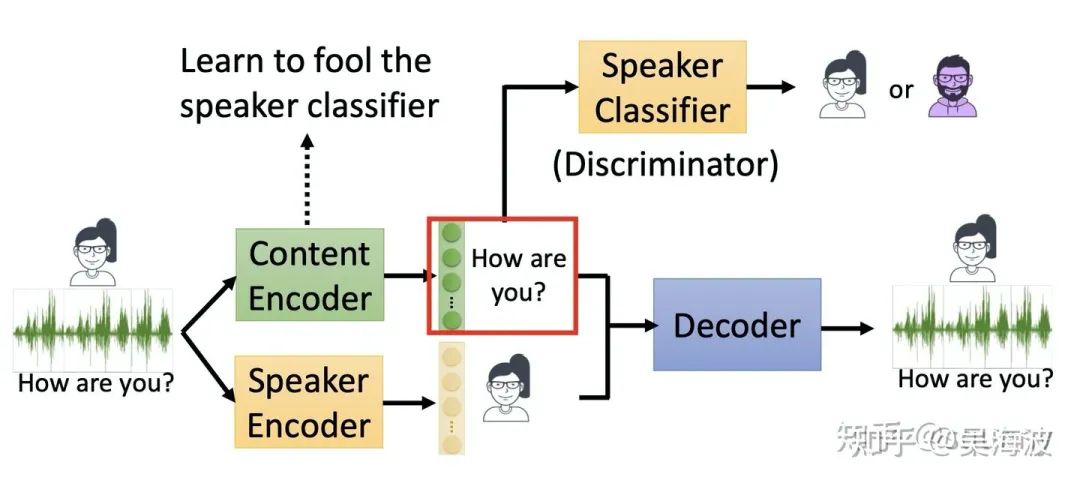
VC其中的一种训练方式(对抗训练)
本文采用的是另外一种做法,speaker Encoder是使用的预训练好的voice vertification模型,通过重构损失训练content Encoder。
3.4 人脸关键点偏移量学习

3.4.1 基于语音内容的关键点偏移量学习
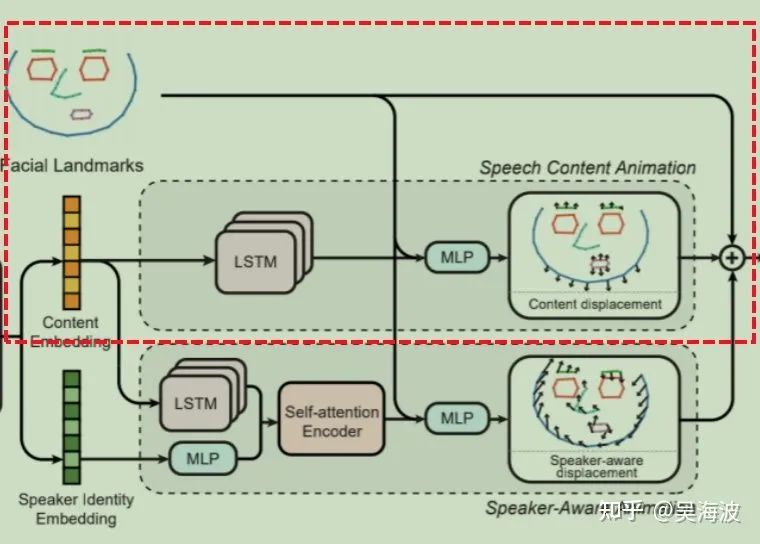
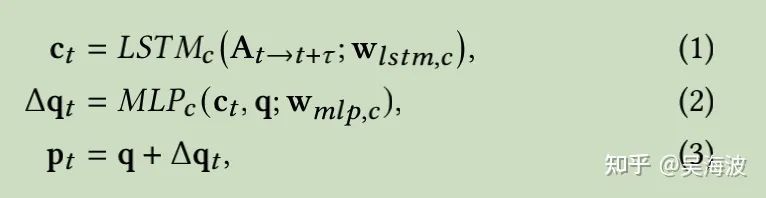
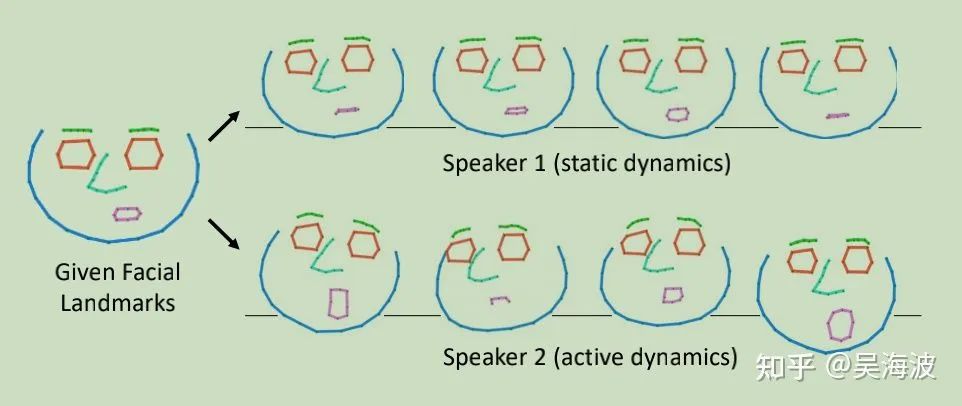
3.4.2 基于说话人信息的关键点偏移量预测
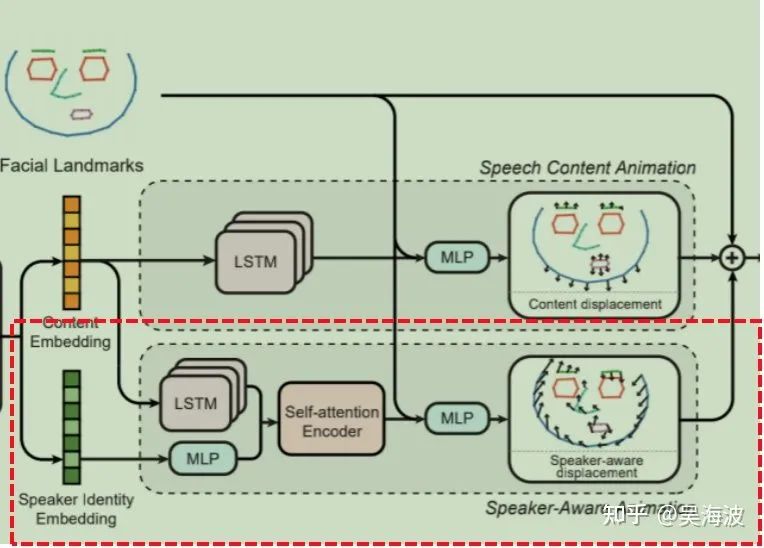
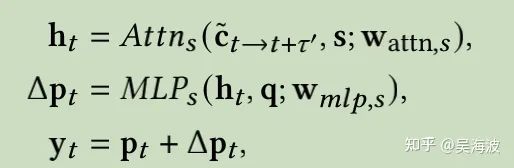
3.5 关键点到人脸图像生成

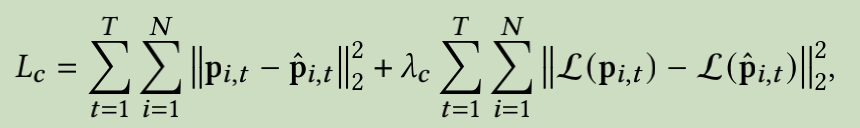
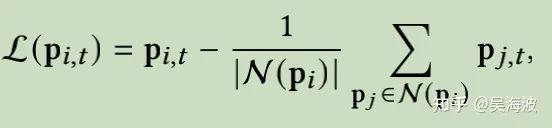
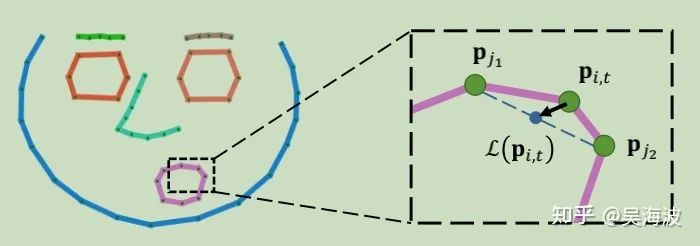
Discriminator loss
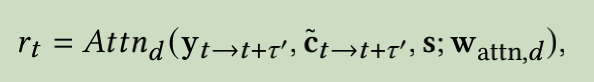
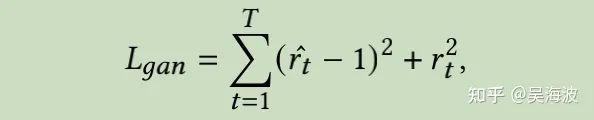
Generator loss
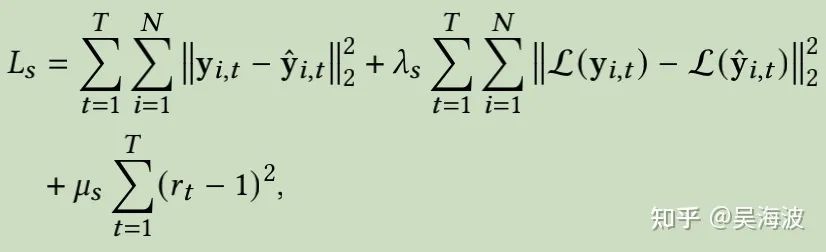
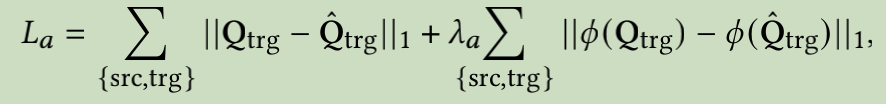
3.7 小结
03
DAVS作者在CVPR2021上PC-AVS(Pose-Controllable Talking Face Generation by Implicity Modularized Audio-Video Representation)
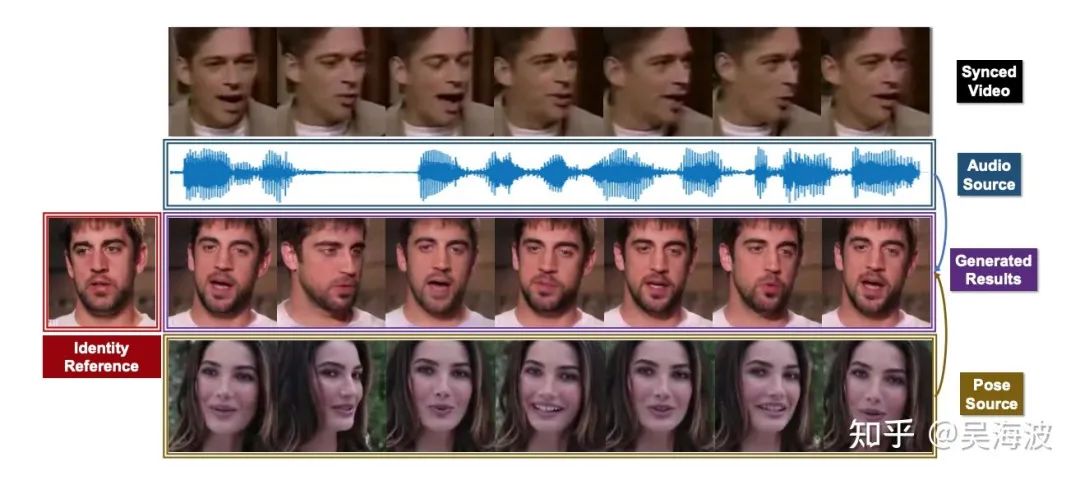

makeItTalk在训练过成中其实只利用到了音频信息,忽略了训练数据本身的视频信息。通过分离音频信息中的说话者特征去预测姿态相关的关键点偏移量,其实说明了说话者信息可以预测出姿态信息。而结合PC-AVS通过视频源编码姿态向量的方式,将二者结合起来。利用训练数据集本身的视频信息去编码姿态(显示或者隐式),音频信息分离出说话者信息同样编码姿态信息,让二者在训练中对齐。 预测的时候,直接输入音频信息,通过分离的出的说话者身份信息隐含的姿态编码,直接生成speaker-aware的讲话人视频
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
评论