
LVS原理与实现 - 实现篇
在上一篇文章中,我们主要介绍了 LVS 的原理,接下来我们将会介绍 LVS 的代码实现。
本文使用的内核版本是:2.4.23,而 LVS 的代码在路径:
/src/net/ipv4/ipvs中。
Netfilter
在介绍 LVS 的实现前,我们需要了解以下 Netfilter 这个功能,因为 LVS 的实现使用了 Netfilter 的功能。
Netfilter:顾名思义就是网络过滤器(Network Filter),是 Linux 系统特有的网络子系统,用于过滤或修改进出内核协议栈的网络数据包。一般可以用来实现网络防火墙功能,其中iptables就是基于Netfilter实现的。
Linux 内核处理进出网络协议栈的数据包分为5个不同的阶段,Netfilter 通过这5个阶段注入钩子函数(Hooks Function)来实现对数据包的过滤和修改。如下图的蓝色方框所示:
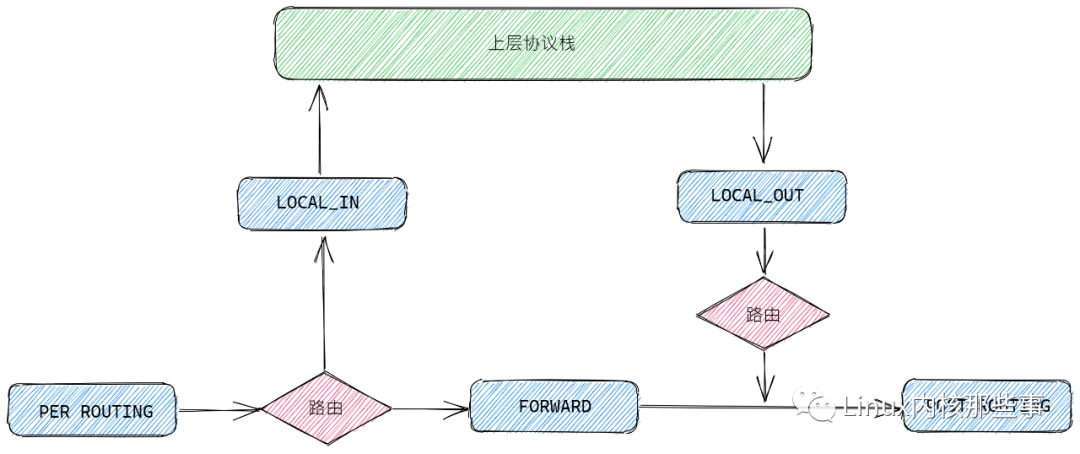
这5个阶段分为:
PER_ROUTING:路由前阶段,发生在内核对数据包进行路由判决前。LOCAL_IN:本地上送阶段,发生在内核通过路由判决后。如果数据包是发送给本机的,那么就把数据包上送到上层协议栈。FORWARD:转发阶段,发生在内核通过路由判决后。如果数据包不是发送给本机的,那么就把数据包转发出去。LOCAL_OUT:本地发送阶段,发生在对发送数据包进行路由判决之前。POST_ROUTING:路由后阶段,发生在对发送数据包进行路由判决之后。
当向 Netfilter 的这5个阶段注册钩子函数后,内核会在处理数据包时,根据所在的不同阶段来调用这些钩子函数对数据包进行处理。向 Netfilter 注册钩子函数可以通过函数 nf_register_hook() 来进行,nf_register_hook() 函数的原型如下:
int nf_register_hook(struct nf_hook_ops *reg);其中参数 reg 是类型为 struct nf_hook_ops 结构的指针,struct nf_hook_ops 结构的定义如下:
struct nf_hook_ops{struct list_head list;nf_hookfn *hook;int pf;int hooknum;int priority;};
struct nf_hook_ops 结构各个字段的作用如下:
list:用于连接同一阶段中所有相同的钩子函数列表。hook:钩子函数指针。pf:协议类型,因为Netfilter可以用于不同的协议,如 IPV4 和 IPV6 等。hooknum:所处的阶段,也就是上面所说的5个不同的阶段。priority:优先级,值越大优先级约小。
所以要使用 Netfilter 对网络数据包进行处理,只需要编写好处理数据包的钩子函数,然后通过调用 nf_register_hook() 函数向 Netfilter 注册即可。
另外,钩子函数 nf_hookfn 的原型如下:
typedef unsigned int nf_hookfn(unsigned int hooknum, struct sk_buff **skb,const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *));
其参数说明如下:
hooknum:所处的阶段,也就是上面所说的5个不同的阶段。skb:要处理的数据包。in:输入设备。out:输出设备。okfn:如果钩子函数执行成功,即调用这个函数完成对数据包的后续处理工作。
Netfilter 相关的知识点就介绍到这里,以后有机会会详解讲解 Netfilter 的原理和现实。
LVS 实现
前面我们主要简单介绍了 Netfilter 的使用,接下来我们将要分析 LVS 的代码实现。
1. 钩子函数注册
LVS 主要通过向 Netfilter 的3个阶段注册钩子函数来对数据包进行处理,如下图:
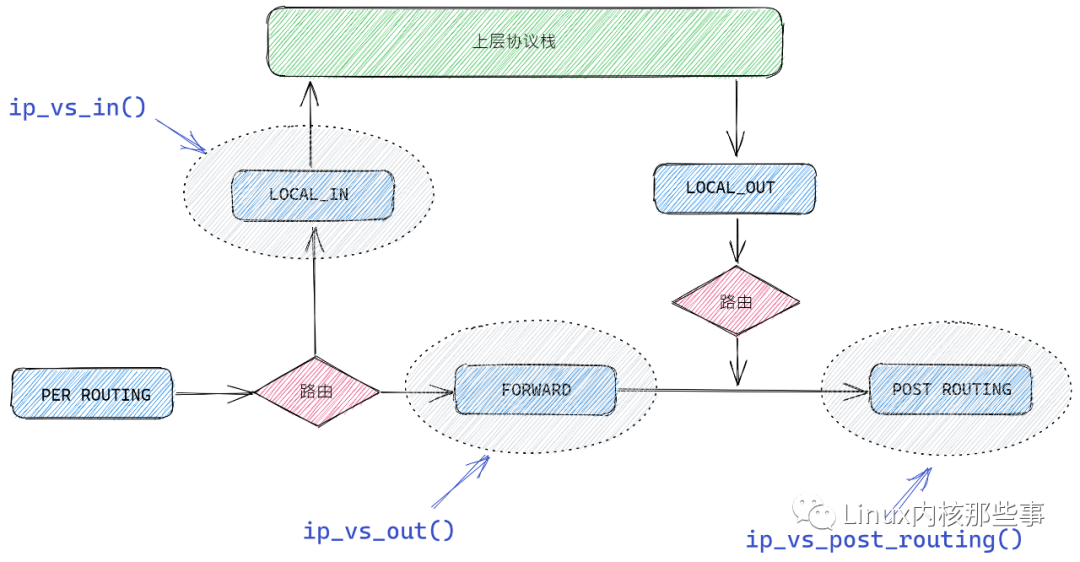
在
LOCAL_IN阶段注册了ip_vs_in()钩子函数。在
FORWARD阶段注册了ip_vs_out()钩子函数。在
POST_ROUTING阶段注册了ip_vs_post_routing()钩子函数。
我们在 LVS 的初始化函数 ip_vs_init() 可以找到这些钩子函数的注册代码,如下:
static struct nf_hook_ops ip_vs_in_ops = {{ NULL, NULL },ip_vs_in, PF_INET, NF_IP_LOCAL_IN, 100};static struct nf_hook_ops ip_vs_out_ops = {{ NULL, NULL },ip_vs_out, PF_INET, NF_IP_FORWARD, 100};static struct nf_hook_ops ip_vs_post_routing_ops = {{ NULL, NULL },ip_vs_post_routing, PF_INET, NF_IP_POST_ROUTING, NF_IP_PRI_NAT_SRC-1};static int __init ip_vs_init(void){int ret;...ret = nf_register_hook(&ip_vs_in_ops);...ret = nf_register_hook(&ip_vs_out_ops);...ret = nf_register_hook(&ip_vs_post_routing_ops);...return ret;}
LOCAL_IN阶段:在路由判决之后,如果发现数据包是发送给本机的,那么就调用ip_vs_in()函数对数据包进行处理。FORWARD阶段:在路由判决之后,如果发现数据包不是发送给本机的,调用ip_vs_out()函数对数据包进行处理。POST_ROUTING阶段:在发送数据前,需要调用ip_vs_post_routing()函数对数据包进行处理。
2. LVS 角色介绍
在介绍这些钩子函数之前,我们先来了解一下 LVS 中的四个角色。如下:
ip_vs_service:服务配置对象,主要用于保存 LVS 的配置信息,如 支持的传输层协议、虚拟IP和端口等。ip_vs_dest:真实服务器对象,主要用于保存真实服务器 (Real-Server) 的配置,如真实IP、端口和权重等。ip_vs_scheduler:调度器对象,主要通过使用不同的调度算法来选择合适的真实服务器对象。ip_vs_conn:连接对象,主要为了维护相同的客户端与真实服务器之间的连接关系。这是由于 TCP 协议是面向连接的,所以同一个的客户端每次选择真实服务器的时候必须保存一致,否则会出现连接中断的情况,而连接对象就是为了维护这种关系。
各个角色之间的关系如下图所示:
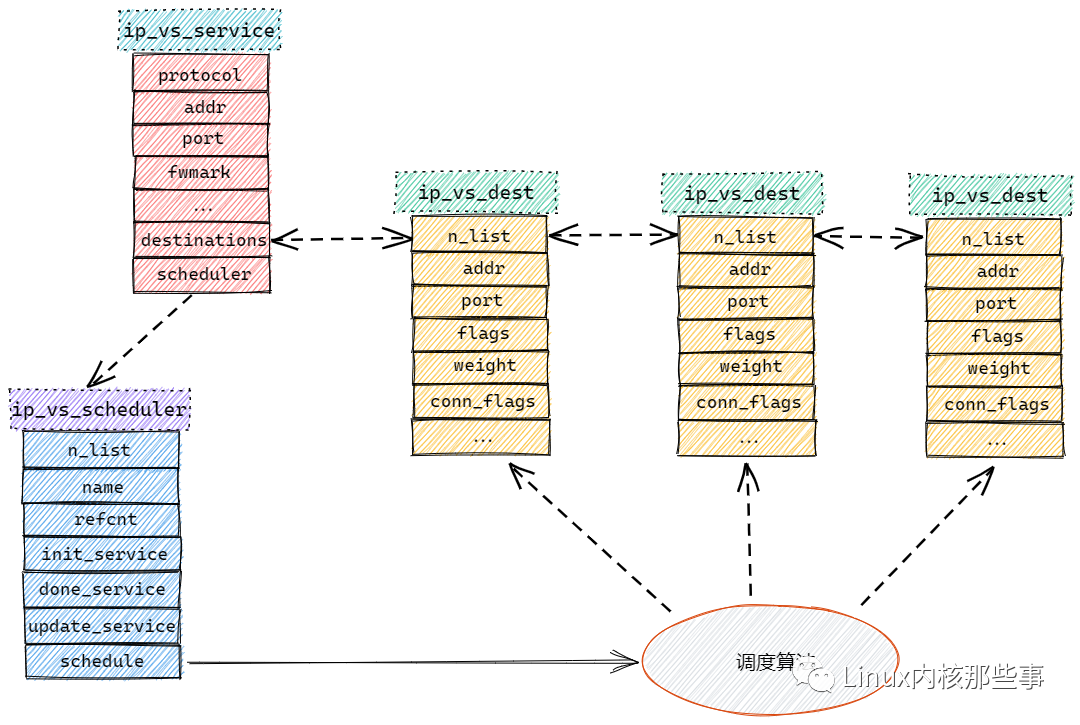
从上图可以看出,ip_vs_service 对象的 destinations 字段用于保存 ip_vs_dest 对象的列表,而 scheduler 字段指向了一个 ip_vs_scheduler 对象。
ip_vs_scheduler 对象的 schedule 字段指向了一个调度算法函数,通过这个调度函数可以从 ip_vs_service 对象的 ip_vs_dest 对象列表中选择一个合适的真实服务器。
那么,ip_vs_service 对象和 ip_vs_dest 对象的信息怎么来的呢?答案是通过用户配置创建。例如可以通过下面的命令来创建 ip_vs_service 对象和 ip_vs_dest 对象:
node1 > $ ipvsadm -A -t node1:80 -s wrrnode1 > $ ipvsadm -a -t node1:80 -r node2 -m -w 3node1 > $ ipvsadm -a -t node1:80 -r node3 -m -w 5
第一行用于创建一个 ip_vs_service 对象,而第二和第三行用于向 ip_vs_service 对象添加 ip_vs_dest 对象到 destinations 列表中。关于 LVS 的配置这里不作详细介绍,读者可以参考其他关于 LVS 配置的资料。
ip_vs_service 对象创建
我们来看看 LVS 源码是怎么创建一个 ip_vs_service 对象的,创建 ip_vs_service 对象通过 ip_vs_add_service() 函数完成,如下:
static intip_vs_add_service(struct ip_vs_rule_user *ur, struct ip_vs_service **svc_p){int ret = 0;struct ip_vs_scheduler *sched;struct ip_vs_service *svc = NULL;sched = ip_vs_scheduler_get(ur->sched_name); // 根据调度器名称获取调度策略对象...// 申请一个 ip_vs_service 对象svc = (struct ip_vs_service *)kmalloc(sizeof(struct ip_vs_service), GFP_ATOMIC);...memset(svc, 0, sizeof(struct ip_vs_service));// 设置 ip_vs_service 对象的各个字段svc->protocol = ur->protocol; // 协议svc->addr = ur->vaddr; // 虚拟IPsvc->port = ur->vport; // 虚拟端口svc->fwmark = ur->vfwmark; // 防火墙标记svc->flags = ur->vs_flags; // 标志位svc->timeout = ur->timeout * HZ; // 超时时间svc->netmask = ur->netmask; // 网络掩码INIT_LIST_HEAD(&svc->destinations);svc->sched_lock = RW_LOCK_UNLOCKED;svc->stats.lock = SPIN_LOCK_UNLOCKED;ret = ip_vs_bind_scheduler(svc, sched); // 绑定调度器...ip_vs_svc_hash(svc); // 添加到ip_vs_service对象的hash表中...*svc_p = svc;return 0;}
先说明一下,参数 ur 是用户通过命令行配置的规则信息。上面的代码主要完成以下几个工作:
通过调用
ip_vs_scheduler_get()函数来获取一个ip_vs_scheduler(调度器) 对象。然后申请一个
ip_vs_service对象并且根据用户的配置设置其各个参数,并且把调度器对象绑定这个ip_vs_service对象。最后把
ip_vs_service对象添加到ip_vs_service对象的全局哈希表中(这是由于可以创建多个ip_vs_service对象,这些对象通过一个全局哈希表来存储)。
ip_vs_dest 对象创建
创建 ip_vs_dest 对象通过 ip_vs_add_dest() 函数完成,代码如下:
static int ip_vs_add_dest(struct ip_vs_service *svc, struct ip_vs_rule_user *ur){struct ip_vs_dest *dest;__u32 daddr = ur->daddr; // 目的IP__u16 dport = ur->dport; // 目的端口int ret;...// 调用 ip_vs_new_dest() 函数创建一个 ip_vs_dest 对象ret = ip_vs_new_dest(svc, ur, &dest);...// 把 ip_vs_dest 对象添加到 ip_vs_service 对象的 destinations 列表中list_add(&dest->n_list, &svc->destinations);svc->num_dests++;/* 调用调度器的 update_service() 方法更新 ip_vs_service 对象 */svc->scheduler->update_service(svc);...return 0;}
ip_vs_add_dest() 函数主要通过调用 ip_vs_new_dest() 创建一个 ip_vs_dest 对象,然后将其添加到 ip_vs_service 对象的 destinations 列表中。我们来看看 ip_vs_new_dest() 函数的实现:
static intip_vs_new_dest(struct ip_vs_service *svc,struct ip_vs_rule_user *ur,struct ip_vs_dest **destp){struct ip_vs_dest *dest;...*destp = dest = (struct ip_vs_dest*)kmalloc(sizeof(struct ip_vs_dest), GFP_ATOMIC);...memset(dest, 0, sizeof(struct ip_vs_dest));// 设置 ip_vs_dest 对象的各个字段dest->protocol = svc->protocol; // 协议dest->vaddr = svc->addr; // 虚拟IPdest->vport = svc->port; // 虚拟端口dest->vfwmark = svc->fwmark; // 虚拟网络掩码dest->addr = ur->daddr; // 真实IPdest->port = ur->dport; // 真实端口atomic_set(&dest->activeconns, 0);atomic_set(&dest->inactconns, 0);atomic_set(&dest->refcnt, 0);INIT_LIST_HEAD(&dest->d_list);dest->dst_lock = SPIN_LOCK_UNLOCKED;dest->stats.lock = SPIN_LOCK_UNLOCKED;__ip_vs_update_dest(svc, dest, ur);...return 0;}
ip_vs_new_dest() 函数的实现也比较简单,首先通过调用 kmalloc() 函数申请一个 ip_vs_dest 对象,然后根据用户配置的规则信息来初始化 ip_vs_dest 对象的各个字段。
ip_vs_scheduler 对象
ip_vs_scheduler (调度器) 对象用于从 ip_vs_service 对象的 destinations 列表中选择一个合适的 ip_vs_dest 对象,其定义如下:
struct ip_vs_scheduler {struct list_head n_list; // 连接所有调度策略char *name; // 调度策略名称atomic_t refcnt; // 应用计数器struct module *module; // 模块对象(如果是通过模块引入的)int (*init_service)(struct ip_vs_service *svc); // 用于初始化服务int (*done_service)(struct ip_vs_service *svc); // 用于停止服务int (*update_service)(struct ip_vs_service *svc); // 用于更新服务// 用于获取一个真实服务器对象 (Real-Server)struct ip_vs_dest *(*schedule)(struct ip_vs_service *svc, struct iphdr *iph);};
ip_vs_scheduler 对象的各个字段都在注释说明了,其中 schedule 字段是一个函数的指针,其指向一个调度函数,用于从 ip_vs_service 对象的 destinations 列表中选择一个合适的 ip_vs_dest 对象。
我们可以通过一个最简单的调度模块(轮询调度模块)来分析 ip_vs_scheduler 对象的工作原理(文件路径:/net/ipv4/ipvs/ip_vs_rr.c):
static struct ip_vs_scheduler ip_vs_rr_scheduler = {{0}, /* n_list */"rr", /* name */ATOMIC_INIT(0), /* refcnt */THIS_MODULE, /* this module */ip_vs_rr_init_svc, /* service initializer */ip_vs_rr_done_svc, /* service done */ip_vs_rr_update_svc,/* service updater */ip_vs_rr_schedule, /* select a server from the destination list */};
首先轮询调度模块定义了一个 ip_vs_scheduler 对象,其中 schedule 字段设置为 ip_vs_rr_schedule() 函数。我们来看看 ip_vs_rr_schedule() 函数的实现:
static struct ip_vs_dest *ip_vs_rr_schedule(struct ip_vs_service *svc, struct iphdr *iph){register struct list_head *p, *q;struct ip_vs_dest *dest;write_lock(&svc->sched_lock);p = (struct list_head *)svc->sched_data; // 最后一次被调度的位置p = p->next;q = p;// 遍历 destinations 列表do {if (q == &svc->destinations) {q = q->next;continue;}dest = list_entry(q, struct ip_vs_dest, n_list);// 找到一个权限值大于 0 的 ip_vs_dest 对象if (atomic_read(&dest->weight) > 0)goto out;q = q->next;} while (q != p);write_unlock(&svc->sched_lock);return NULL;out:svc->sched_data = q; // 设置最后一次被调度的位置...return dest;}
ip_vs_rr_schedule() 函数是轮询调度算法的实现,其实现原理如下:
ip_vs_service对象的sched_data字段保存了最后一次调度的位置,所以每次调度时都是从这个字段读取到最后一次调度的位置。从最后一次调度的位置开始遍历,找到一个权限值(weight)大于 0 的
ip_vs_dest对象。如果找到就把
ip_vs_service对象的sched_data字段设置为最后被选择的ip_vs_dest对象的位置。
其原理可以通过以下图片说明:
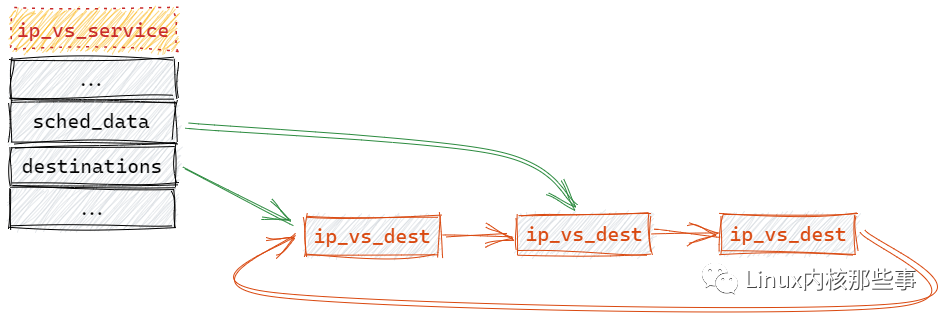
上图描述的原理还是比较简单,首先从 sched_data 处开始遍历,查找一个合适的 ip_vs_dest 对象,然后更新 sched_data 的位置。
另外,由于 LVS 可以存在多种不同的调度对象(提供不同的调度算法),所以 LVS 把这些调度对象通过一个链表(ip_vs_schedulers)存储起来,而这些调度对象可以通过调度对象的名字(name 字段)来查询。
可以通过调用 register_ip_vs_scheduler() 函数向 LVS 注册调度对象,而通过调用 ip_vs_scheduler_get() 函数来获取指定名字的调度对象,这两个函数的实现比较简单,这里就不作详细介绍了。
ip_vs_conn 对象
ip_vs_conn 对象用于维护 客户端 与 真实服务器 之间的关系,为什么需要维护它们之间的关系?原因是 TCP协议 面向连接的协议,所以每次调度都必须选择相同的真实服务器,否则连接就会失效。
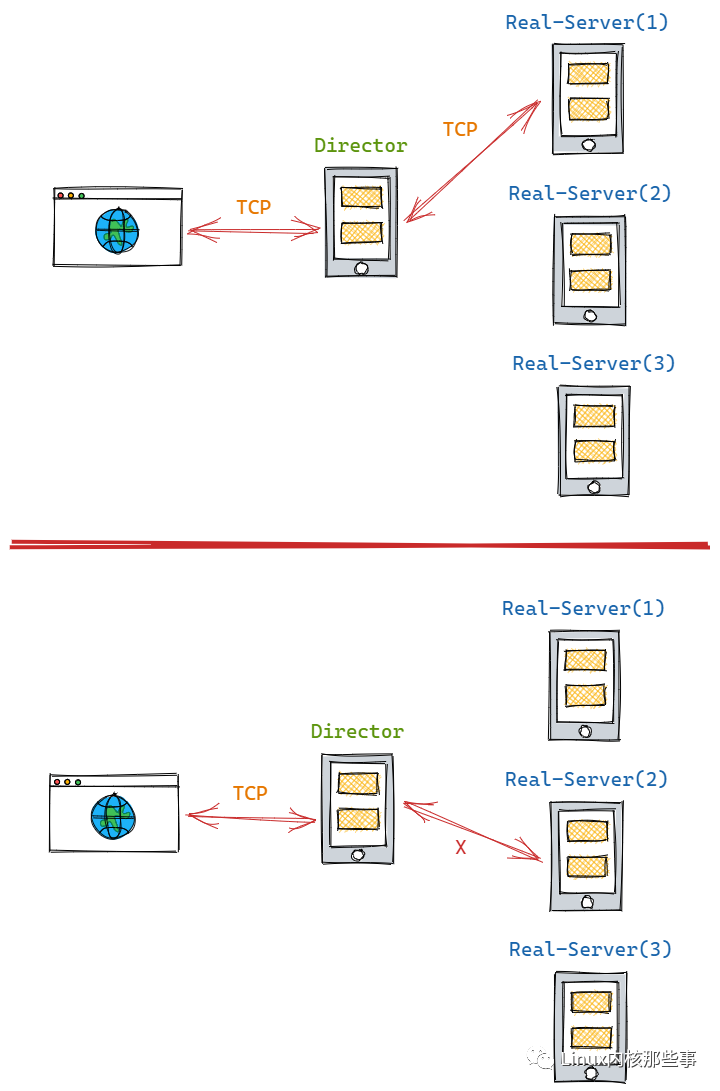
如上图所示,刚开始时调度器选择了 Real-Server(1) 服务器进行处理客户端请求,但第二次调度时却选择了 Real-Server(2) 来处理客户端请求。
由于 TCP协议 需要客户端与服务器进行连接,但第二次请求的服务器发生了变化,所以连接状态就失效了,这就为什么 LVS 需要维持客户端与真实服务器连接关系的原因。
LVS 通过 ip_vs_conn 对象来维护客户端与真实服务器之间的连接关系,其定义如下:
struct ip_vs_conn {struct list_head c_list; /* 用于连接到哈希表 */__u32 caddr; /* 客户端IP地址 */__u32 vaddr; /* 虚拟IP地址 */__u32 daddr; /* 真实服务器IP地址 */__u16 cport; /* 客户端端口 */__u16 vport; /* 虚拟端口 */__u16 dport; /* 真实服务器端口 */__u16 protocol; /* 协议类型(UPD/TCP) */.../* 用于发送数据包的接口 */int (*packet_xmit)(struct sk_buff *skb, struct ip_vs_conn *cp);...};
ip_vs_conn 对象各个字段的作用都在注释中进行说明了,客户端与真实服务器的连接关系就是通过 协议类型、客户端IP、客户端端口、虚拟IP 和 虚拟端口 来进行关联的,也就是说根据这五元组能够确定一个 ip_vs_conn 对象。
另外,在《原理篇》我们说过,LVS 有3中运行模式:NAT模式、DR模式 和 TUN模式。而对于不同的运行模式,发送数据包的接口是不一样的,所以 ip_vs_conn 对象的 packet_xmit 字段会根据不同的运行模式来选择不同的发送数据包接口,绑定发送数据包接口是通过 ip_vs_bind_xmit() 函数完成,如下:
static inline void ip_vs_bind_xmit(struct ip_vs_conn *cp){switch (IP_VS_FWD_METHOD(cp)) {case IP_VS_CONN_F_MASQ: // NAT模式cp->packet_xmit = ip_vs_nat_xmit;break;case IP_VS_CONN_F_TUNNEL: // TUN模式cp->packet_xmit = ip_vs_tunnel_xmit;break;case IP_VS_CONN_F_DROUTE: // DR模式cp->packet_xmit = ip_vs_dr_xmit;break;...}}
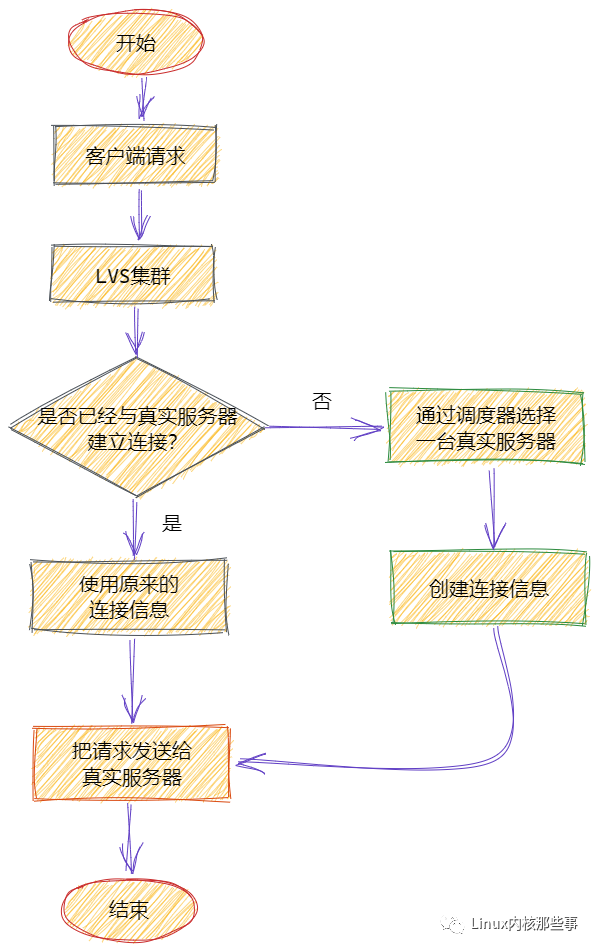
一个客户端请求到达 LVS 后,Director服务器 首先会查找客户端是否已经与真实服务器建立了连接关系,如果已经建立了连接,那么直接使用这个连接关系。否则,通过调度器对象选择一台合适的真实服务器,然后创建客户端与真实服务器的连接关系,并且保存到全局哈希表 ip_vs_conn_tab 中。流程图如下:
上面对 LVS 各个角色都进行了介绍,下面开始讲解 LVS 对数据包的转发过程。
3. 数据转发
因为 LVS 是一个负载均衡工具,所以其最重要的功能就是对数据的调度与转发, 而对数据的转发是在前面介绍的 Netfilter 钩子函数进行的。
对数据的转发主要是通过 ip_vs_in() 和 ip_vs_out() 这两个钩子函数:
ip_vs_in()运行在Netfilter的LOCAL_IN阶段。ip_vs_out()运行在Netfilter的FORWARD阶段。
FORWARD 阶段发送在数据包不是发送给本机的情况,但是一般来说数据包都是发送给本机的,所以对于 ip_vs_out() 这个函数的实现就不作介绍,我们主要重点分析 ip_vs_in() 这个函数。
ip_vs_in() 钩子函数
有了前面的知识点,我们对 ip_vs_in() 函数的分析就不那么困难了。下面我们分段对 ip_vs_in() 函数进行分析:
static unsigned intip_vs_in(unsigned int hooknum,struct sk_buff **skb_p,const struct net_device *in,const struct net_device *out,int (*okfn)(struct sk_buff *)){struct sk_buff *skb = *skb_p;struct iphdr *iph = skb->nh.iph; // IP头部union ip_vs_tphdr h;struct ip_vs_conn *cp;struct ip_vs_service *svc;int ihl;int ret;...// 因为LVS只支持TCP和UDPif (iph->protocol != IPPROTO_TCP && iph->protocol != IPPROTO_UDP)return NF_ACCEPT;ihl = iph->ihl << 2; // IP头部长度// IP头部是否正确if (ip_vs_header_check(skb, iph->protocol, ihl) == -1)return NF_DROP;iph = skb->nh.iph; // IP头部指针h.raw = (char*)iph + ihl; // TCP/UDP头部指针
上面的代码主要对数据包的 IP头部 进行正确性验证,并且将 iph 变量指向 IP头部,而 h 变量指向 TCP/UDP 头部。
// 根据 "协议类型", "客户端IP", "客户端端口", "虚拟IP", "虚拟端口" 五元组获取连接对象cp = ip_vs_conn_in_get(iph->protocol, iph->saddr,h.portp[0], iph->daddr, h.portp[1]);// 1. 如果连接还没建立// 2. 如果是TCP协议的话, 第一个包必须是syn包, 或者UDP协议。// 3. 根据协议、虚拟IP和虚拟端口查找服务对象if (!cp &&(h.th->syn || (iph->protocol != IPPROTO_TCP)) &&(svc = ip_vs_service_get(skb->nfmark, iph->protocol, iph->daddr, h.portp[1]))){...// 通过调度器选择一个真实服务器// 并且创建一个新的连接对象, 建立真实服务器与客户端连接关系cp = ip_vs_schedule(svc, iph);...}
上面的代码主要完成以下几个功能:
根据
协议类型、客户端IP、客户端端口、虚拟IP和虚拟端口五元组,然后调用ip_vs_conn_in_get()函数获取连接对象。如果连接还没建立,那么就调用
ip_vs_schedule()函数调度一台合适的真实服务器,然后创建一个连接对象,并且建立真实服务器与客户端之间的连接关系。
我们来分析一下 ip_vs_schedule() 函数的实现:
static struct ip_vs_conn *ip_vs_schedule(struct ip_vs_service *svc, struct iphdr *iph){struct ip_vs_conn *cp = NULL;struct ip_vs_dest *dest;const __u16 *portp;...portp = (__u16 *)&(((char *)iph)[iph->ihl*4]); // 指向TCP或者UDP头部...dest = svc->scheduler->schedule(svc, iph); // 通过调度器选择一台合适的真实服务器...cp = ip_vs_conn_new(iph->protocol, // 协议类型iph->saddr, // 客户端IPportp[0], // 客户端端口iph->daddr, // 虚拟IPportp[1], // 虚拟端口dest->addr, // 真实服务器的IPdest->port ? dest->port : portp[1], // 真实服务器的端口0, // flagsdest);...return cp;}
ip_vs_schedule() 函数的主要工作如下:
首先通过调用调度器(
ip_vs_scheduler对象)的schedule()方法从ip_vs_service对象的destinations链表中选择一台真实服务器(ip_vs_dest对象)然后调用
ip_vs_conn_new()函数创建一个新的ip_vs_conn对象。
ip_vs_conn_new() 主要用于创建 ip_vs_conn 对象,并且根据 LVS 的运行模式为其选择正确的数据发送接口,其实现如下:
struct ip_vs_conn *ip_vs_conn_new(int proto, // 协议类型__u32 caddr, __u16 cport, // 客户端IP和端口__u32 vaddr, __u16 vport, // 虚拟IP和端口__u32 daddr, __u16 dport, // 真实服务器IP和端口unsigned flags, struct ip_vs_dest *dest){struct ip_vs_conn *cp;// 创建一个 ip_vs_conn 对象cp = kmem_cache_alloc(ip_vs_conn_cachep, GFP_ATOMIC);...// 设置 ip_vs_conn 对象的各个字段cp->protocol = proto;cp->caddr = caddr;cp->cport = cport;cp->vaddr = vaddr;cp->vport = vport;cp->daddr = daddr;cp->dport = dport;cp->flags = flags;...ip_vs_bind_dest(cp, dest); // 将 ip_vs_conn 与真实服务器对象进行绑定...ip_vs_bind_xmit(cp); // 绑定一个发送数据的接口...ip_vs_conn_hash(cp); // 把 ip_vs_conn 对象添加到连接信息表中return cp;}
ip_vs_conn_new() 函数的主要工作如下:
创建一个新的
ip_vs_conn对象,并且设置其各个字段的值。调用
ip_vs_bind_dest()函数将ip_vs_conn对象与真实服务器对象(ip_vs_dest对象)进行绑定。根据
LVS的运行模式,调用ip_vs_bind_xmit()函数为连接对象选择一个正确的数据发送接口,ip_vs_bind_xmit()函数在前面已经介绍过。调用
ip_vs_conn_hash()函数把新创建的ip_vs_conn对象添加到全局连接信息哈希表中。
我们接着分析 ip_vs_in() 函数:
if (cp->packet_xmit)ret = cp->packet_xmit(skb, cp); // 把数据包转发出去else {ret = NF_ACCEPT;}...return ret;}
ip_vs_in() 函数的最后部分就是通过调用数据发送接口把数据包转发出去,对于 NAT模式 来说,数据发送接口就是 ip_vs_nat_xmit()。
数据发送接口:ip_vs_nat_xmit()
接下来,我们对 NAT模式 的数据发送接口 ip_vs_nat_xmit() 进行分析。由于 ip_vs_nat_xmit() 函数的实现比较复杂,所以我们通过分段来分析:
static int ip_vs_nat_xmit(struct sk_buff *skb, struct ip_vs_conn *cp){struct rtable *rt; /* Route to the other host */struct iphdr *iph;union ip_vs_tphdr h;int ihl;unsigned short size;int mtu;...iph = skb->nh.iph; // IP头部ihl = iph->ihl << 2; // IP头部长度h.raw = (char*) iph + ihl; // 传输层头部(TCP/UDP)size = ntohs(iph->tot_len) - ihl; // 数据长度...// 找到真实服务器IP的路由信息if (!(rt = __ip_vs_get_out_rt(cp, RT_TOS(iph->tos))))goto tx_error_icmp;...// 替换新路由信息dst_release(skb->dst);skb->dst = &rt->u.dst;
上面的代码主要完成两个工作:
调用
__ip_vs_get_out_rt()函数查找真实服务器 IP 对应的路由信息对象。把数据包的旧路由信息替换成新的路由信息。
我们接着分析:
iph->daddr = cp->daddr; // 修改目标IP地址为真实服务器IP地址h.portp[1] = cp->dport; // 修改目标端口为真实服务器端口...// 更新UDP/TCP头部的校验和if (!cp->app && (iph->protocol != IPPROTO_UDP || h.uh->check != 0)) {ip_vs_fast_check_update(&h, cp->vaddr, cp->daddr, cp->vport,cp->dport, iph->protocol);if (skb->ip_summed == CHECKSUM_HW)skb->ip_summed = CHECKSUM_NONE;} else {switch (iph->protocol) {case IPPROTO_TCP:h.th->check = 0;h.th->check = csum_tcpudp_magic(iph->saddr, iph->daddr,size, iph->protocol,csum_partial(h.raw, size, 0));break;case IPPROTO_UDP:h.uh->check = 0;h.uh->check = csum_tcpudp_magic(iph->saddr, iph->daddr,size, iph->protocol,csum_partial(h.raw, size, 0));if (h.uh->check == 0)h.uh->check = 0xFFFF;break;}skb->ip_summed = CHECKSUM_UNNECESSARY;}
上面的代码完成两个工作:
修改目标IP地址和端口为真实服务器IP地址和端口。
更新
UDP/TCP 头部的校验和(checksum)。
我们接着分析:
ip_send_check(iph); // 计算IP头部的校验和...skb->nfcache |= NFC_IPVS_PROPERTY;ip_send(skb); // 把包发送出去...return NF_STOLEN; // 让其他 Netfilter 的钩子函数放弃处理该包}
上面的代码完成两个工作:
调用
ip_send_check()函数重新计算数据包的IP头部校验和。调用
ip_send()函数把数据包发送出去。
这样,数据包的目标IP地址和端口被替换成真实服务器的IP地址和端口,然后被发送到真实服务器处。至此,NAT模式 的分析已经完毕。下面我们来总结一下整个流程:
当数据包进入到
Director服务器后,会被LOCAL_IN阶段的ip_vs_in()钩子函数进行处理。ip_vs_in()函数首先查找客户端与真实服务器的连接是否存在,如果存在就使用这个真实服务器。否则通过调度算法对象选择一台最合适的真实服务器,然后建立客户端与真实服务器的连接关系。根据运行模式来选择发送数据的接口(如
NAT模式对应的是ip_vs_nat_xmit()函数),然后把数据转发出去。转发数据时,首先会根据真实服务器的IP地址更新数据包的路由信息,然后再更新各个协议头部的信息(如IP地址、端口和校验和等),然后把数据发送出去。
总结
本文主要分析 LVS 的实现原理,但由于本人能力有限,并且很多细节没有分析,所以有问题可以通过评论指出。另外,本文只介绍了 NAT模式 的原理,还有 DR模式 和 TUN模式 的没有分析,有兴趣可以自行阅读源码