
在pandas中利用hdf5高效存储数据

点击上方"蓝字"关注我们
记录 分享 成长
1 简介
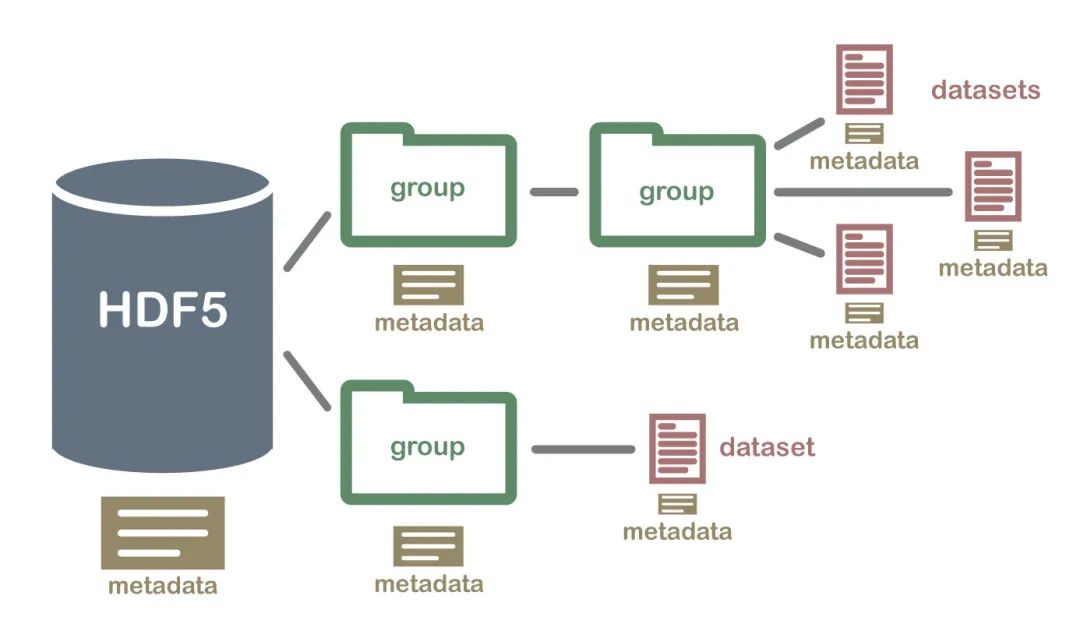
HDF5(Hierarchical Data Formal)是用于存储大规模数值数据的较为理想的存储格式。
其文件后缀名为h5,存储读取速度非常快,且可在文件内部按照明确的层次存储数据,同一个HDF5可以看做一个高度整合的文件夹,其内部可存放不同类型的数据。
在Python中操纵HDF5文件的方式主要有两种,一是利用pandas中内建的一系列HDF5文件操作相关的方法来将pandas中的数据结构保存在HDF5文件中,二是利用h5py模块来完成从Python原生数据结构向HDF5格式的保存。
本文就将针对pandas中读写HDF5文件的方法进行介绍。
2 利用pandas操纵HDF5文件
2.1 写出文件
pandas中的HDFStore()用于生成管理HDF5文件IO操作的对象,其主要参数如下:
❝「path」:字符型输入,用于指定h5文件的名称(不在当前工作目录时需要带上完整路径信息)
「mode」:用于指定IO操作的模式,与Python内建的open()中的参数一致,默认为'a',即当指定文件已存在时不影响原有数据写入,指定文件不存在时则新建文件;'r',只读模式;'w',创建新文件(会覆盖同名旧文件);'r+',与'a'作用相似,但要求文件必须已经存在;
「complevel」:int型,用于控制h5文件的压缩水平,取值范围在0-9之间,越大则文件的压缩程度越大,占用的空间越小,但相对应的在读取文件时需要付出更多解压缩的时间成本,默认为0,代表不压缩
❞
下面我们创建一个HDF5 IO对象store:
import pandas as pd
store = pd.HDFStore('demo.h5')
'''查看store类型'''
print(store)
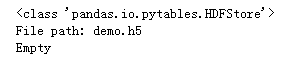
可以看到store对象属于pandas的io类,通过上面的语句我们已经成功的初始化名为demo.h5的的文件,本地也相应的会出现对应文件。
接下来我们创建pandas中不同的两种对象,并将它们共同保存到store中,首先创建Series对象:
import numpy as np
#创建一个series对象
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
s

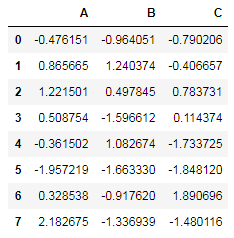
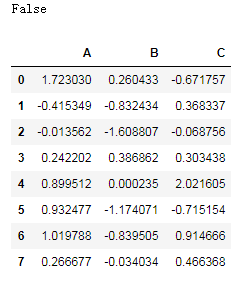
接着我们创建一个DataFrame对象:
#创建一个dataframe对象
df = pd.DataFrame(np.random.randn(8, 3),
columns=['A', 'B', 'C'])
df
第一种方式利用键值对将不同的数据存入store对象中:
store['s'], store['df'] = s, df
第二种方式利用store对象的put()方法,其主要参数如下:
❝「key」:指定h5文件中待写入数据的key
「value」:指定与key对应的待写入的数据
「format」:字符型输入,用于指定写出的模式,'fixed'对应的模式速度快,但是不支持追加也不支持检索;'table'对应的模式以表格的模式写出,速度稍慢,但是支持直接通过store对象进行追加和表格查询操作
❞
使用put()方法将数据存入store对象中:
store.put(key='s', value=s);store.put(key='df', value=df)
既然是键值对的格式,那么可以查看store的items属性(注意这里store对象只有items和keys属性,没有values属性):
store.items

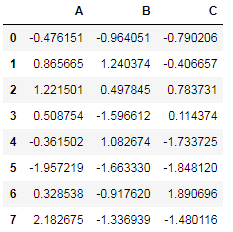
调用store对象中的数据直接用对应的键名来索引即可:
store['df']
删除store对象中指定数据的方法有两种,一是使用remove()方法,传入要删除数据对应的键:
store.remove('s')
二是使用Python中的关键词del来删除指定数据:
del store['s']
这时若想将当前的store对象持久化到本地,只需要利用close()方法关闭store对象即可,而除了通过定义一个确切的store对象的方式之外,还可以从pandas中的数据结构直接导出到本地h5文件中:
#创建新的数据框
df_ = pd.DataFrame(np.random.randn(5,5))
#导出到已存在的h5文件中,这里需要指定key
df_.to_hdf(path_or_buf='demo.h5',key='df_')
#创建于本地demo.h5进行IO连接的store对象
store = pd.HDFStore('demo.h5')
#查看指定h5对象中的所有键
print(store.keys())

2.2 读入文件
在pandas中读入HDF5文件的方式主要有两种,一是通过上一节中类似的方式创建与本地h5文件连接的IO对象,接着使用键索引或者store对象的get()方法传入要提取数据的key来读入指定数据:
store = pd.HDFStore('demo.h5')
'''方式1'''
df1 = store['df']
'''方式2'''
df2 = store.get('df')
df1 == df2

可以看出这两种方式都能顺利读取键对应的数据。
第二种读入h5格式文件中数据的方法是pandas中的read_hdf(),其主要参数如下:
❝「path_or_buf」:传入指定h5文件的名称
「key」:要提取数据的键
❞
需要注意的是利用read_hdf()读取h5文件时对应文件不可以同时存在其他未关闭的IO对象,否则会报错,如下例:
print(store.is_open)
df = pd.read_hdf('demo.h5',key='df')

把IO对象关闭后再次提取:
store.close()
print(store.is_open)
df = pd.read_hdf('demo.h5',key='df')
df
2.3 性能测试
接下来我们来测试一下对于存储同样数据的csv格式文件、h5格式的文件,在读取速度上的差异情况:
这里我们首先创建一个非常大的数据框,由一亿行x5列浮点类型的标准正态分布随机数组成,接着分别用pandas中写出HDF5和csv格式文件的方式持久化存储:
import pandas as pd
import numpy as np
import time
store = pd.HDFStore('store.h5')
#生成一个1亿行,5列的标准正态分布随机数表
df = pd.DataFrame(np.random.rand(100000000,5))
start1 = time.clock()
store['df'] = df
store.close()
print(f'HDF5存储用时{time.clock()-start1}秒')
start2 = time.clock()
df.to_csv('df.csv',index=False)
print(f'csv存储用时{time.clock()-start2}秒')
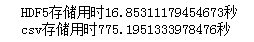
在写出同样大小的数据框上,HDF5比常规的csv快了将近50倍,而且两者存储后的文件大小也存在很大差异:
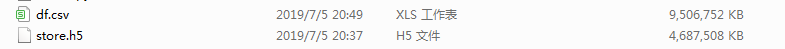
csv比HDF5多占用将近一倍的空间,这还是在我们没有开启HDF5压缩的情况下,接下来我们关闭所有IO连接,运行下面的代码来比较对上述两个文件中数据还原到数据框上两者用时差异:
import pandas as pd
import time
start1 = time.clock()
store = pd.HDFStore('store.h5',mode='r')
df1 = store.get('df')
print(f'HDF5读取用时{time.clock()-start1}秒')
start2 = time.clock()
df2 = pd.read_csv('df.csv')
print(f'csv读取用时{time.clock()-start2}秒')
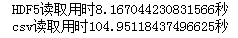
HDF5用时仅为csv的1/13,因此在涉及到数据存储特别是规模较大的数据时,HDF5是你不错的选择。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
加入我们的知识星球【Python大数据分析】
爱上数据分析!

Python大数据分析
data creates value
扫码关注我们