
CV岗位面试题:K-means选择初始点的方法有哪些,优缺点是什么?

文 | 七月在线
编 | 小七
解析:
KMeans是数据挖掘十大算法之一,在数据挖掘实践中,我们也常常将KMeans运用于各种场景,因为它原理简单、易于实现、适合多种数据挖掘情景。
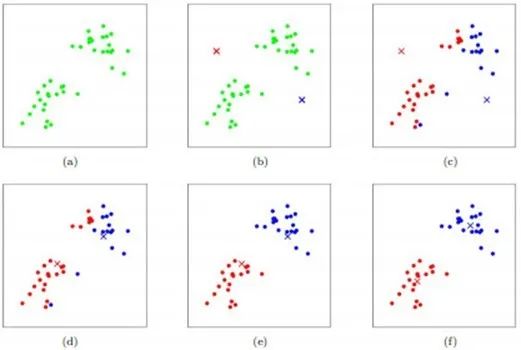
如上图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示:
(a)刚开始时是原始数据,杂乱无章,没有label,看起来都一样,都是绿色的。
(b)假设数据集可以分为两类,令K=2,随机在坐标上选两个点,作为两个类的中心点。
(c-f)演示了聚类的两种迭代。先划分,把每个数据样本划分到最近的中心点那一簇;划分完后,更新每个簇的中心,即把该簇的所有数据点的坐标加起来去平均值。这样不断进行”划分—更新—划分—更新”,直到每个簇的中心不在移动为止。(图文来自Andrew ng的机器学习公开课)。
初始中心点的选择:
初始中心点的选择最简单的做法是随机从样本中选K个作为中心点,但由于中心点的选择会影响KMeans的聚类效果,因此我们可以采取以下三种方式优化中心点的选取:
1.多次选取中心点进行多次试验,并用损失函数来评估效果,选择最优的一组;
2.选取距离尽量远的K个样本点作为中心点:随机选取第一个样本C1作为第一个中心点,遍历所有样本选取离C1最远的样本C2为第二个中心点,以此类推,选出K个初始中心点
3.特别地,对于像文本这样的高维稀疏向量,我们可以选取K个两两正交的特征向量作为初始化中心点。

评论