
即插即用 | 卷积与Self-Attention完美融合X-volution插入CV模型将带来全任务的涨点(文末附论文)


本文建立了一个由卷积和self-attention组成的多分支基本模块,能够统一局部和非局部特征交互,然后可以结构重新参数化为一个纯卷积风格的算子:X-volution,即插即用!可助力分类、检测和分割任务的涨点!
作者单位:上海交通大学(倪冰冰团队),华为海思
1简介
卷积和self-attention是深度神经网络中的2个基本构建块,前者以线性方式提取图像的局部特征,而后者通过非局部关系编码高阶上下文关系。尽管本质上是相互补充的,即一阶/高阶、最先进的架构,但是,CNN或Transformer均缺乏一种原则性的方法来在单个计算模块中同时应用这2种操作,因为它们的异构计算视觉任务的全局点积的模式和过度负担。
在这项工作中,作者从理论上推导出一种全局self-attention近似方案,该方案通过对变换特征的卷积运算来近似self-attention。基于近似方案建立了一个由卷积和self-attention操作组成的多分支基本模块,能够统一局部和非局部特征交互。重要的是,一旦经过训练,这个多分支模块可以通过结构重新参数化有条件地转换为单个标准卷积操作,呈现一个名为X-volution的纯卷积风格的算子,准备作为atomic操作插入任何现代网络。大量实验表明,所提出的X-volution实现了极具竞争力的视觉理解改进(ImageNet分类的top-1准确率+1.2%,COCO 检测和分割的+1.7box AP和+1.5mask AP)。
2方法
本文提出了一种新颖的原子算子X-volution,将基本卷积算子和self-attention算子集成到一个统一的计算块中,期望从局部vs非局部/线性vs非线性两方面获得令人印象深刻的性能改进。
首先,回顾卷积和self-attention的基本数学公式;
然后,解读全局self-attention近似方案,它可以直接转换为一个兼容的卷积模式。
最后,解释在推断阶段如何有条件地合并卷积分支和所提出的self-attention近似到单个卷积风格原子操作符。
2.1 回顾卷积和self-attention
这2个算子想必大家已经非常熟悉了,这里就简单的说一下哈!!!
卷积Module
卷积算子是用于构建卷积神经网络(CNN)的基本算子,它通过有限局部区域内的线性加权来估计输出。给定一个特征张量, 表示输入通道的数量,H是高度,W是宽度。卷积算子的估计结果由以下公式定义:

其中为输出通道数。为卷积核,为特定位置核标量值。为卷积kernel大小,为偏差向量,为卷积kernel中所有可能偏移的集合。
Self-Attention Module
与卷积不同,self-attention不能直接处理图像张量,首先将输入特征张量reshape为向量。表示向量的长度,。分别表示Query、Key、Value的嵌入变换,是空间共享的线性变换。Self-Attention的定义如下:
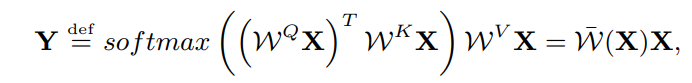
其中表示最终的Self-Attention等价系数矩阵,可以认为是一个动态和空间变化的卷积kernel。
2.2 全局self-attention近似方案
全局自注意是最原始的attention方案,它得益于全局范围的优势而具有优异的性能。然而,它的复杂度太大了使得其在CV任务中的应用受到严重限制。关键问题是能否在公式2中推导出的适当近似结果,即能否找到的兼容计算模式,即能否找到卷积、single element-wise product等现成的算子替代?
在本部分中,作者展示了在简单的element-wise shift和dot-product之后,可以用卷积的形式近似全局self-attention算子。给定特征张量中的一个位置,将其特征向量表示为,其attention logit 可以写成如下公式:

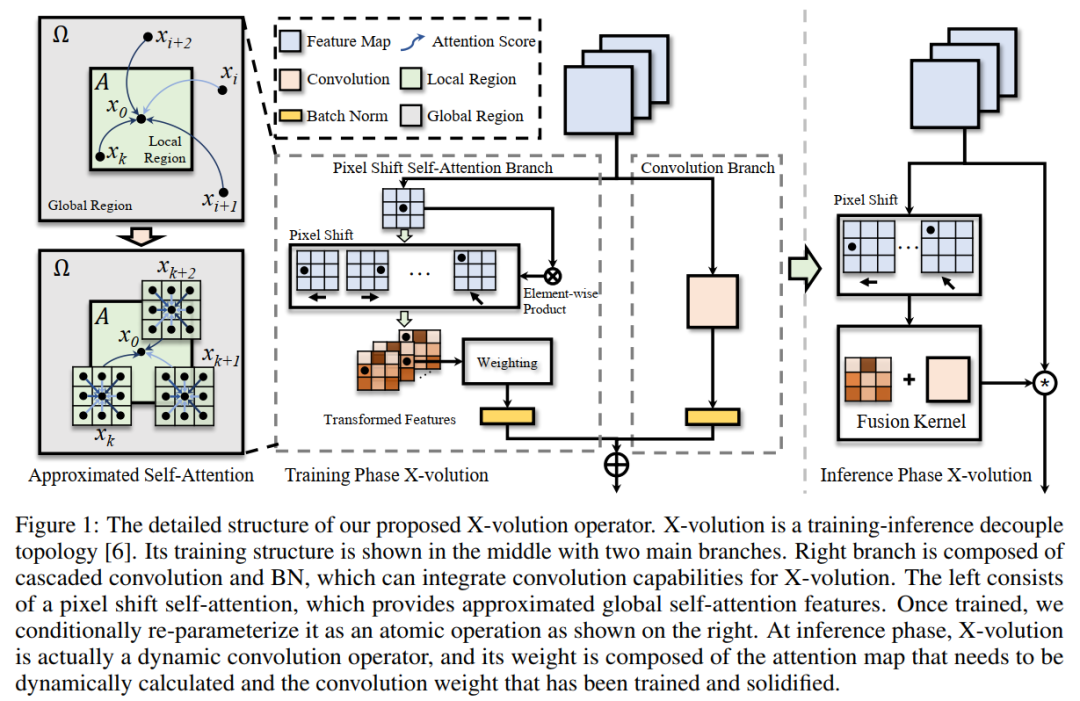
其中, Ω为全局区域,A为以x0为中心的局部区域。在图1的左边说明了局部区域和非局部区域。图中灰框表示输入特征X的全局区域,绿框表示以为中心的局部区域。
另外,non-local区域是指局部区域以外的区域。因为图像具有很强的说服力(根据马尔可夫性质),可以用像素在其局部区域近似线性表示:,其中为线性权值。代入式3中第2项,可得:
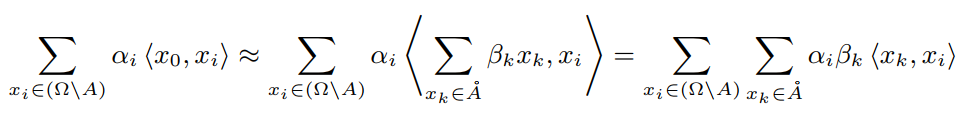
在不失一般性的情况下,可以在区域A中加入系数为零的项。通过设计,non-local区域也在局部区域的边界像素的接受域内。因此可以将上式转化为:
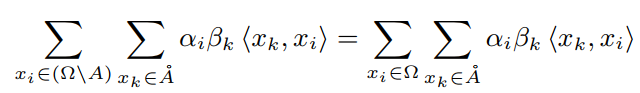
根据图像的马尔可夫性质,可以假设对于,远离的与之间的相互作用是弱的。因此,可以进一步简化式上式:
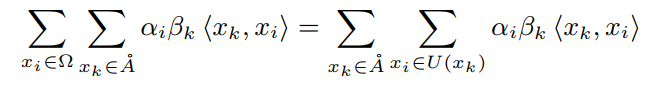
其中为的局部区域。将上式代入Eq.3中的第2项,可以改写为:
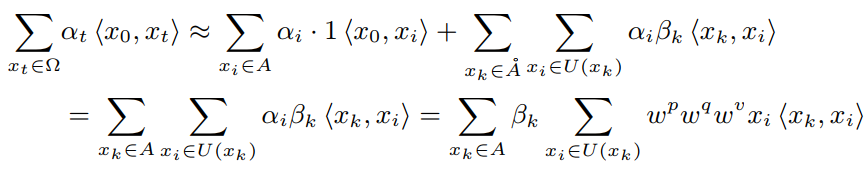
注意,是和之间的内积,它衡量了和之间的相似性。是在其邻近区域的attention结果。因此,在处的全局注意力logit可以通过加权求和其邻域内像素的attention结果来近似。
根据以上理解,可以设计一个近似算子,通过逐点上下文关系传播来估计全局attention。因此,作者提出了一个全局注意力近似方案,Pixel Shift
Self-Attention (PSSA),基于像素偏移和卷积来近似全局attention。
具体来说,首先将特征映射沿给定的方向(即左、右、上等)移动L个像素,然后将原始特征与移动的特征进行元素积,得到变换后的特征。
实际上,shift-product操作建立了邻域内点之间的上下文关系,通过分层叠加可以将上下文关系传播到全局区域。最后,对这些变换后的特征进行加权求和(可以通过卷积算子实现),得到一个近似的自注意力映射。平移、元素积和加权求和的复杂度为O(n),因此提出的PSSA是一个时间复杂度为O(n)的算子。值得注意的是,PSSA实际上是将self-attention转换为对转换特征的标准卷积运算。该结构通过层次叠加进而通过上下文关系传播实现全局self-attention logit的估计。
2.3 卷积和Self-Attention的统一: X-volution
卷积和Self-Attention是相辅相成的
卷积采用局域性和各向同性的归纳偏差,使其具有平移等方差的能力。然而,局部固有的特性使卷积无法建立形成图所必需的长期关系。
与卷积相反,Self-Attention摒弃了提到的归纳偏差,即所谓的低偏差,并从数据集中发现自然模式,而没有明确的模型假设。低偏差原则给予Self-Attention以探索复杂关系的自由(例如,长期依赖、各向异性语义、CNN中的强局部相关性等),因此该方案通常需要对超大数据集进行预训练(如JFT-300M、ImageNet21K)。
此外,Self-Attention很难优化,需要更长的训练周期和复杂的Tricks。有文献提出将卷积引入Self-Attention以提高Self-Attention的鲁棒性和性能。简而言之,采用不同的模型假设,使卷积和Self-Attention在优化特征、注意范围(即局部/长期)和内容依赖(内容依赖/独立)等方面得到相互补充。
统一的多分支拓扑
有一些工作试图将卷积和self-attention结合起来,然而,粗糙的拓扑组合(例如,分层堆叠,级联)阻止他们获得单个原子操作(在同一个模块中应用卷积和注意),使结构不规则。例如,AANet将经过卷积层和Self-Attention层处理的结果直接连接起来,得到组合结果。说明单一的卷积或单一的Self-Attention都会导致性能下降,当它们同时存在时,性能会有显著的提高。
在这个工作中,作者研究卷积和self-attention的数学原理后找到了近似形式。作者还观察到全局元素相互作用(点积)可以用局部元素相互作用的传播来近似表示。
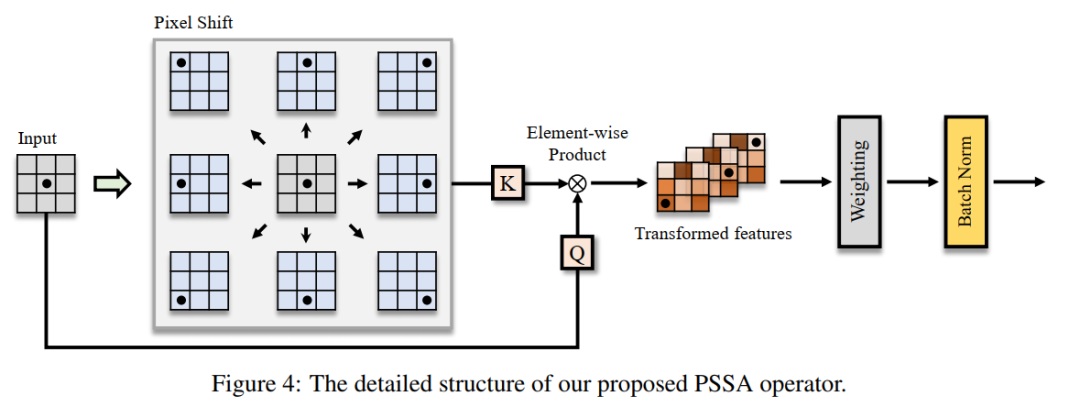
因此,这2种算子可以用统一的计算模式来处理,即卷积。从另一个角度来看,卷积运算可以看作是Self-Attention的空间不变偏差。考虑到这一点,可以将算子组合成一个多分支拓扑,如图所示,这可以同时受益于卷积和Self-Attention。多分支模块由2个主要分支组成。左边的分支由级联的Shift Pixel Self-Attention和batch-normalization组成起到近似全局Self-Attention操作的作用,右分支被设计成由级联卷积和批归一化组成的卷积分支。
有条件地将多分支方案转换为Atomic X-volution
多分支模块实现了卷积与Self-Attention的功能组合。然而,它只是一种粗粒度的算子组合,这将使网络高度复杂和不规则。从硬件实现的角度来看,多分支结构需要更多的缓存来服务于多路径的处理。相反,单个算子操作效率更高,内存开销更低,这是硬件友好的。
为了简单起见,在这里省略批标准化的公式。实际上,批归一化可以看作是一个组卷积(其组等于channel数),可以合并到卷积/Self-Attention层中。实际上,一般采用分层叠加的PSSA,堆叠结构中的加权运算可以省略,因为分层叠加隐含了加权邻接像素的运算。本文提出的多分支模块的训练阶段如下:
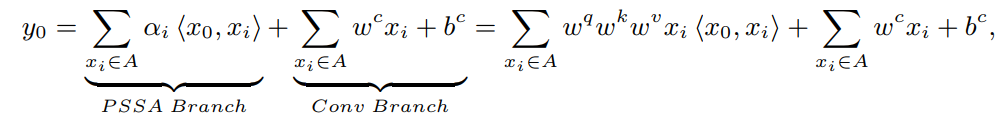
其中为卷积权值,为其对应的偏置。
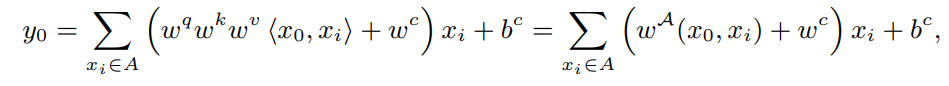
其中表示来自pixel shift self-attention 分支的content-dependent/dynamic coefficients。表示从卷积分支继承的content-independent/static coefficients,训练完成后会修复。
观察上式可以发现,经过一个简单的变换,多分支结构可以转换成卷积形式。值得指出的是,这个过程在CNN中被广泛使用,被称为structural re-parameterization。在这里首先把它扩展到卷积和self-attention的合并。根据上式将由卷积和self-attention组成的多分支模块等价地转换为一个动态卷积算子X-voultion。
请注意,这里建议X-volution可以作为一个原子操作插入主流网络(例如,ResNet)。
3实验
3.1 图像分类
架构设计
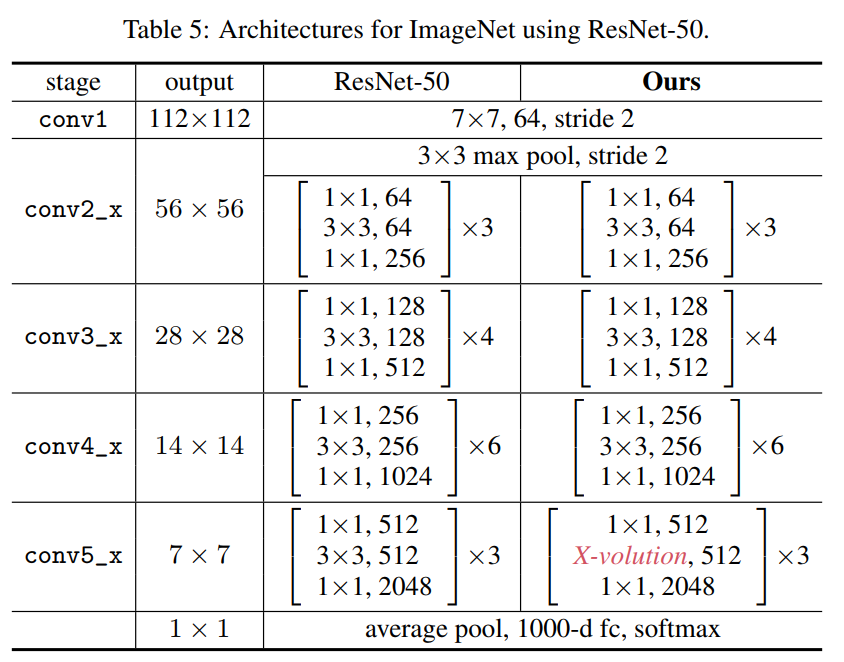
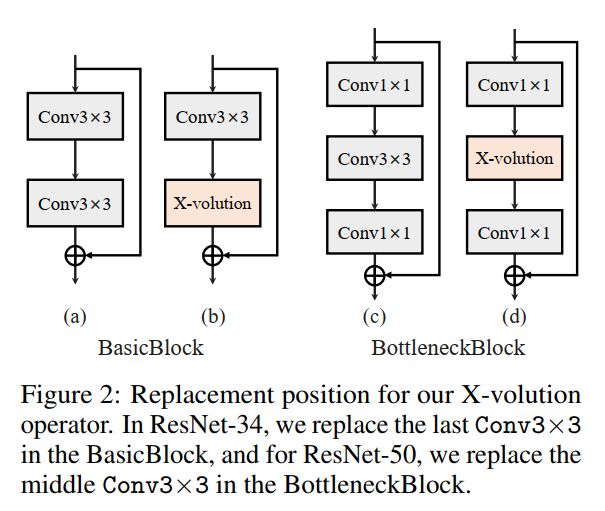
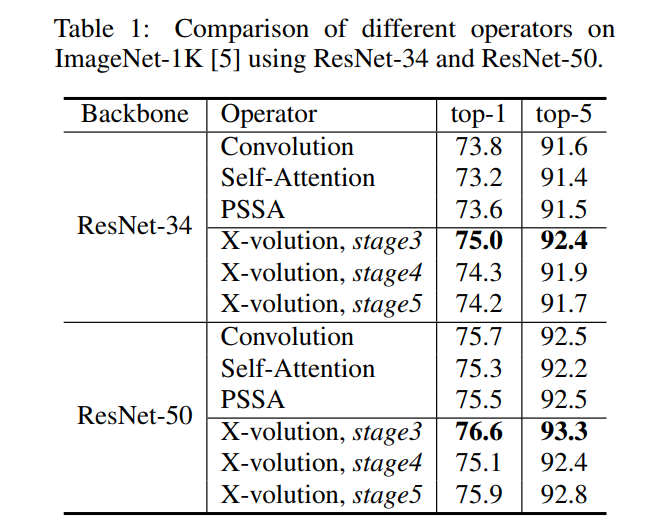
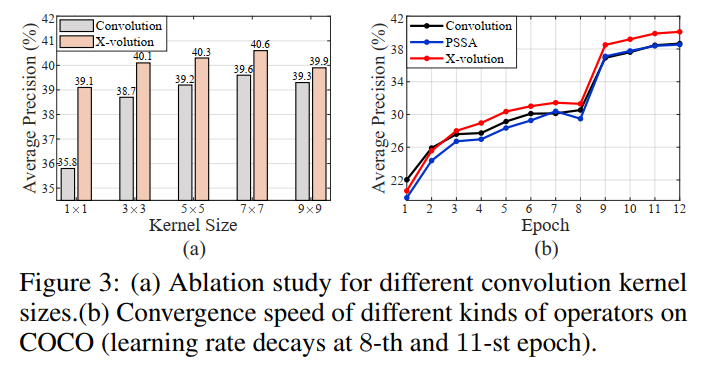
结果表明,第3阶段的替换效果最好,ResNet-34的top-1准确率为+1.2%,ResNet-50的top-1准确率为+0.9%。作者怀疑第4阶段替换的性能较差ResNet-50可以归因于可学习参数的增加,这减慢了网络的收敛。
3.2 目标检测
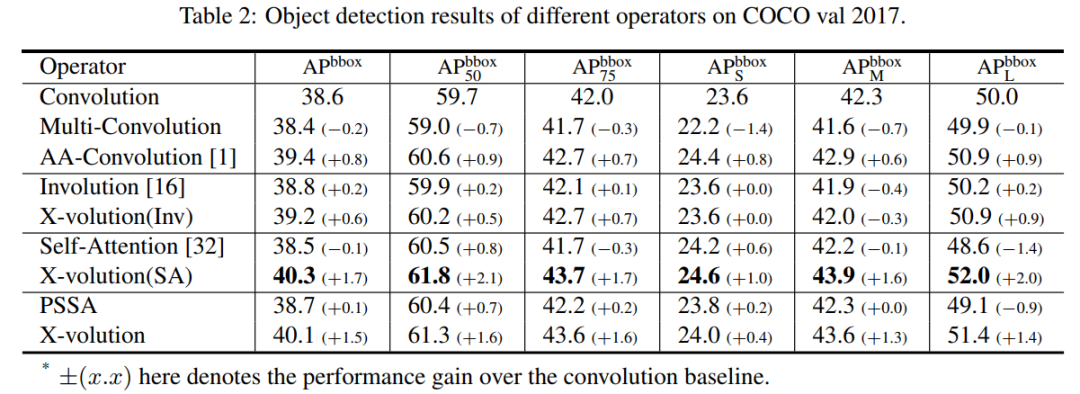
特别是,本文所提X-volution(SA)实现了最好的性能,与ResNet-50相比增加了+1.7boxes AP。通过结合低阶局部特征和高阶长依赖,所提出的X-volution算子比单独的卷积或自注意力算子具有更高的精度。
结果表明,图完备原子算符有助于视觉理解,而现有的计算算符忽略了这一性质。此外,基于PSSA的X-volution也取得了与X-volution(SA)相当的性能,表明在X-volution模块中,近似效果良好,对硬件实现和计算更加友好。

3.3 语义分割
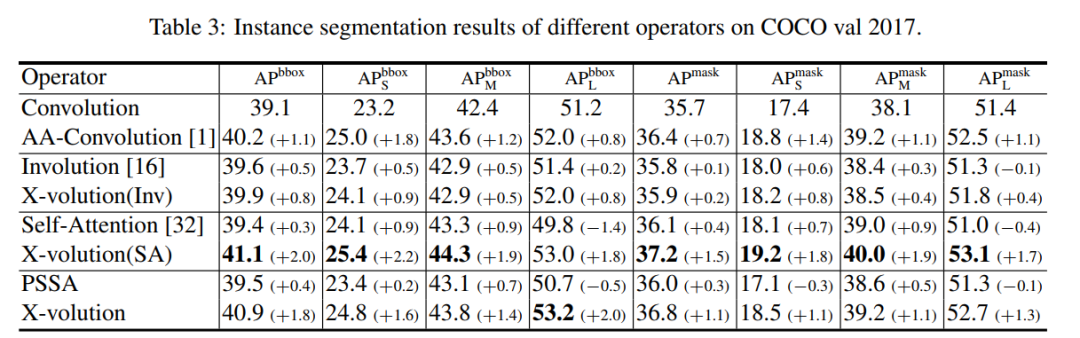
可以观察到,作者提出的X-volution比其他算子的性能要好很多。其中,X-volution(SA)实现了41.1 box AP和37.2 mask AP。
4参考
[1].X-volution: On the Unification of Convolution and Self-attention.
5推荐阅读

Transformer | 详细解读Transformer怎样从零训练并超越ResNet?
YOLO |多域自适应MSDA-YOLO解读,恶劣天气也看得见(附论文)

Transformer | 没有Attention的Transformer依然是顶流!!!

项目实践 | 从零开始边缘部署轻量化人脸检测模型——EAIDK310部署篇

项目实践 | 从零开始边缘部署轻量化人脸检测模型——训练篇
本文论文原文获取方式,扫描下方二维码
回复【X-volution】即可获取项目代码
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
