
Python分析5000+抖音大V,发现大家都喜欢这类视频!

大数据文摘授权转载自法纳斯特
作者:小F
最近,小F在知乎上看到一个关于抖音的问题。
里面提到了,目前我国人均每天刷短视频110分钟。
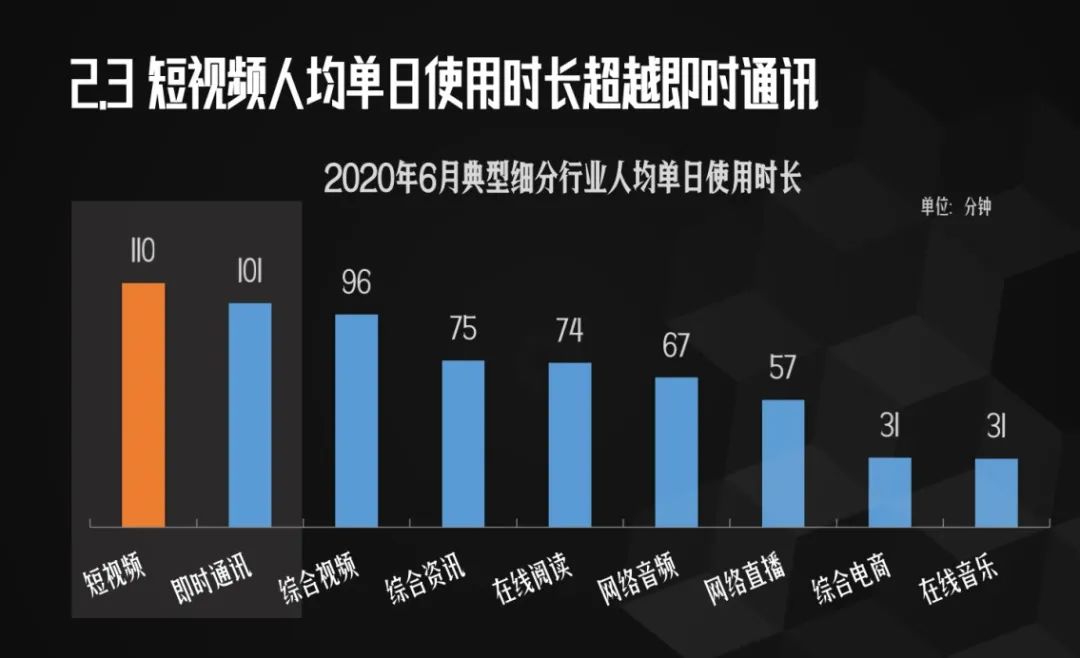
看这数据,看来小F又被平均了。
不过老实说,只要一打开抖音,小F确实是有一种停不下来的感觉~
所以还是少刷抖音,多看书。要不然时间全流逝了。
本期就给大家用数据分析一下在抖音,什么类型的视频最受欢迎。
/ 01 / 数据获取
数据来自于第三方监测,一共是有5000+抖音大V的数据信息。
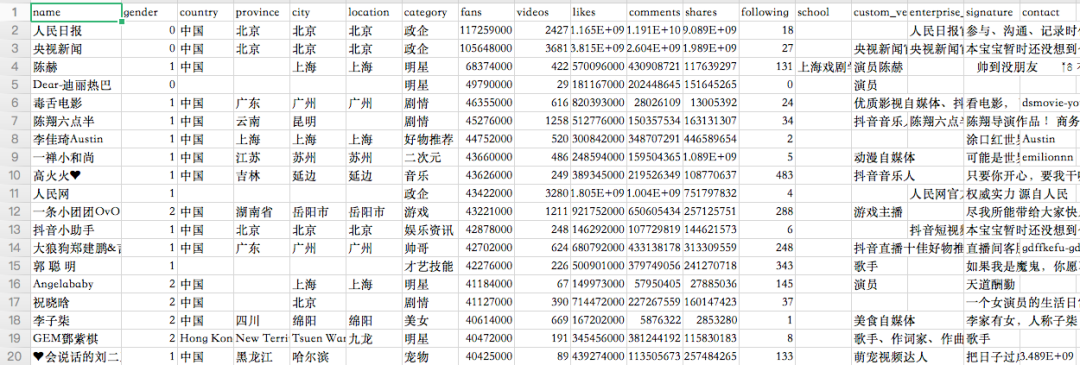
主要包含大V们的昵称、性别、地点、类型、点赞数、粉丝数、视频数、评论数、分享数、关注数、毕业学校、认证、简介等信息。
其中粉丝最多的是「人民日报」,接近1.2亿。「央视新闻」也破亿了,记得之前破亿的时候还上过热搜~
粉丝最少的博主也有近150w+的粉丝,这5000多位大V累计236.5亿粉丝,地球人口的三倍多!
/ 02 / 数据可视化
导入相关库,然后读取数据。
from pyecharts.charts import Pie, Bar, TreeMap, Map, Geo
from wordcloud import WordCloud, ImageColorGenerator
from pyecharts import options as opts
import matplotlib.pyplot as plt
from PIL import Image
import pandas as pd
import numpy as np
import jieba
df = pd.read_csv('douyin.csv', header=0, encoding='utf-8-sig')
print(df)
01 性别分布情况
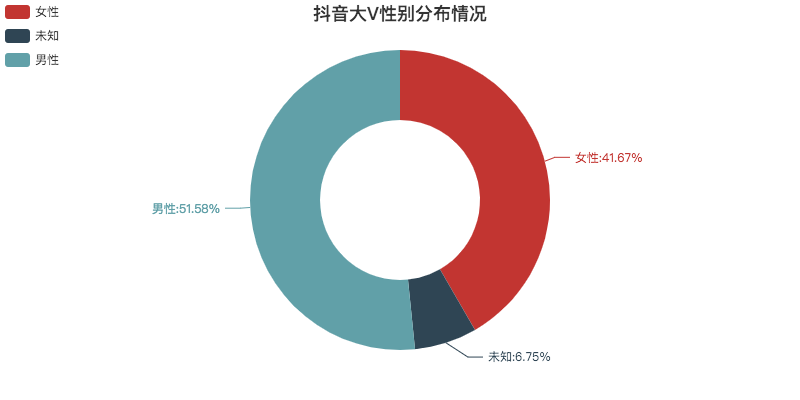
整体上看,男女比例差别不大。
除去未知的数据,基本是1:1。
可视化代码如下。
def create_gender(df):
df = df.copy()
# 修改数值
df.loc[df.gender == '0', 'gender'] = '未知'
df.loc[df.gender == '1', 'gender'] = '男性'
df.loc[df.gender == '2', 'gender'] = '女性'
# 根据性别分组
gender_message = df.groupby(['gender'])
# 对分组后的结果进行计数
gender_com = gender_message['gender'].agg(['count'])
gender_com.reset_index(inplace=True)
# 饼图数据
attr = gender_com['gender']
v1 = gender_com['count']
# 初始化配置
pie = Pie(init_opts=opts.InitOpts(width="800px", height="400px"))
# 添加数据,设置半径
pie.add("", [list(z) for z in zip(attr, v1)], radius=["40%", "75%"])
# 设置全局配置项,标题、图例、工具箱(下载图片)
pie.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V性别分布情况", pos_left="center", pos_top="top"),
legend_opts=opts.LegendOpts(orient="vertical", pos_left="left"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}))
# 设置系列配置项,标签样式
pie.set_series_opts(label_opts=opts.LabelOpts(is_show=True, formatter="{b}:{d}%"))
pie.render("抖音大V性别分布情况.html")
02 点赞数
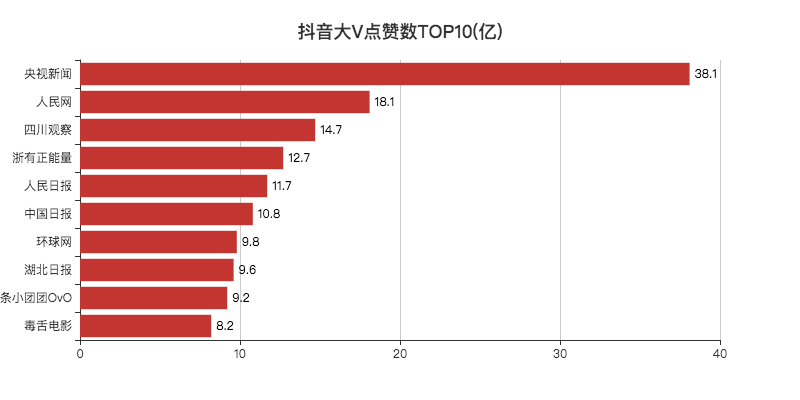
点赞数TOP10,除了「小团团」和「毒舌」,其他都是新闻媒体类的大V。
今年因为疫情,有很多新闻在抖音上都是第一时间传播,所以影响力比较大,点赞也就比较多了。
记得「四川观察」还被评论区调侃为四处观察,意思是发布消息非常快。
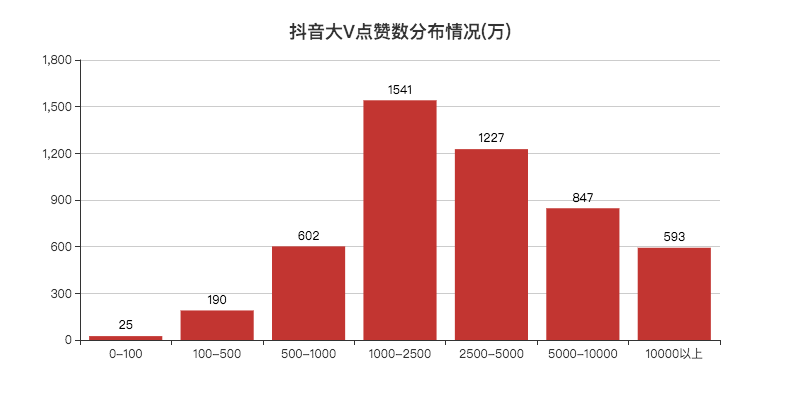
好奇为什么会有100万点赞数的大V,小F的抖音号都有20w+的赞。
最后发现是第三方监测收录的问题,下次可以直接剔除这批数据。
点赞破亿的有500多个大V,1000万到5000万点赞数的大V人数最多。
可视化代码如下。
def create_likes(df):
# 排序,降序
df = df.sort_values('likes', ascending=False)
# 获取TOP10的数据
attr = df['name'][0:10]
v1 = [float('%.1f' % (float(i) / 100000000)) for i in df['likes'][0:10]]
# 初始化配置
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
# x轴数据
bar.add_xaxis(list(reversed(attr.tolist())))
# y轴数据
bar.add_yaxis("", list(reversed(v1)))
# 设置全局配置项,标题、工具箱(下载图片)、y轴分割线
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V点赞数TOP10(亿)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
# 设置系列配置项,标签样式
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
bar.reversal_axis()
bar.render("抖音大V点赞数TOP10(亿).html")
def create_cut_likes(df):
# 将数据分段
Bins = [0, 1000000, 5000000, 10000000, 25000000, 50000000, 100000000, 5000000000]
Labels = ['0-100', '100-500', '500-1000', '1000-2500', '2500-5000', '5000-10000', '10000以上']
len_stage = pd.cut(df['likes'], bins=Bins, labels=Labels).value_counts().sort_index()
# 获取数据
attr = len_stage.index.tolist()
v1 = len_stage.values.tolist()
# 生成柱状图
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(attr)
bar.add_yaxis("", v1)
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V点赞数分布情况(万)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
bar.render("抖音大V点赞数分布情况(万).html")
03 粉丝数
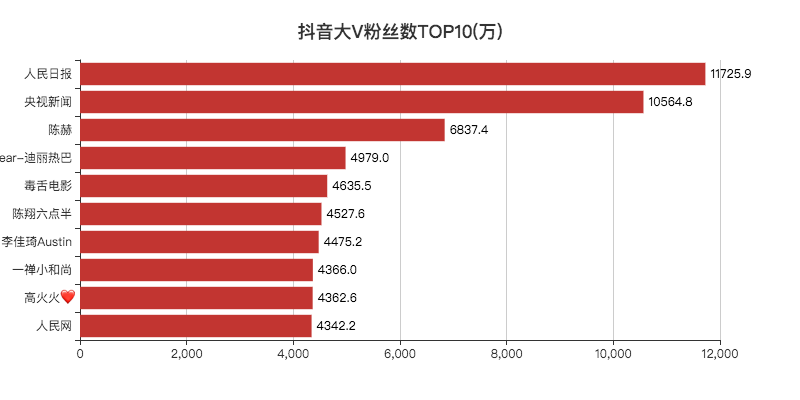
「人民日报」和「央视新闻」粉丝都破亿了。
和去年的抖音数据一对比,「热巴」还少了几十万的粉丝,陈赫倒是涨了不少粉丝。
今年直播带货火热,李佳琦排入前十,也不足为奇,毕竟带货一哥。
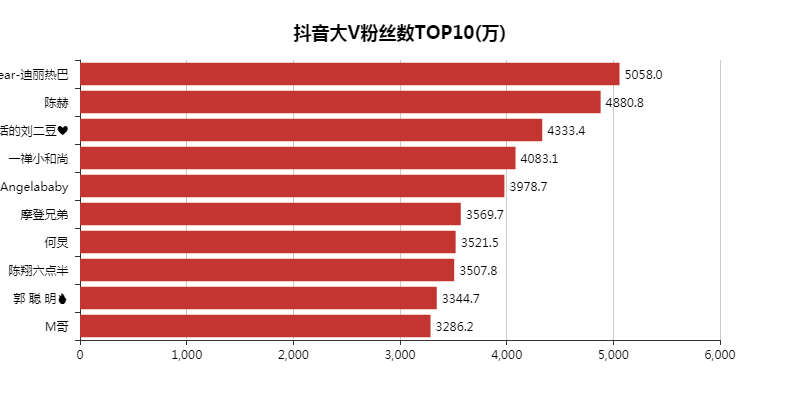
再来看一下大V们粉丝数的分布情况。
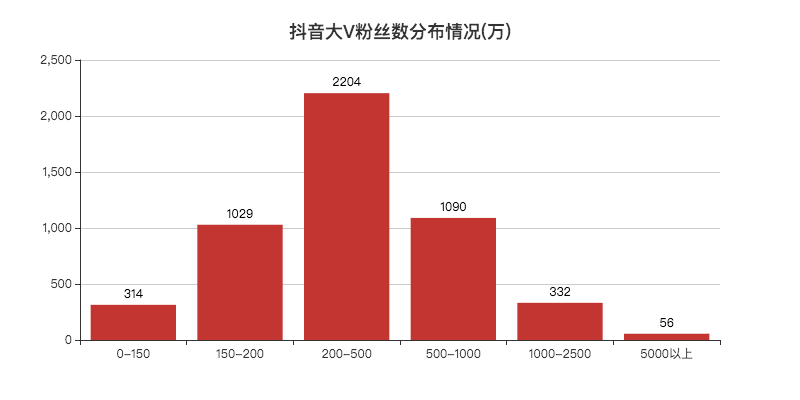
5000万以上56个,妥妥的大佬。
200w~500w的人数最多,好多一时爆火的博主,一段时间后也基本不怎么涨粉了。
可能都停留到了这里,比如小F以前刷过的「三支花」,想不明白这都能火...
这里的可视化代码和上面差不多,就不放出来了。
04 评论数TOP10
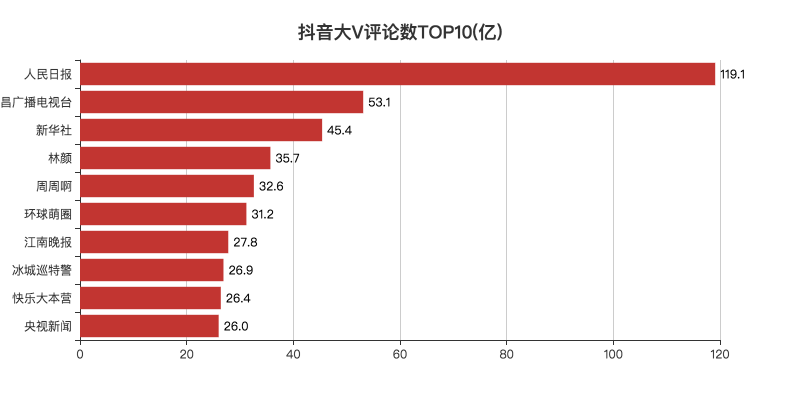
抖音视频的评论区也是比较有意思的地方。
比如刷剧催更的,「赶紧去更新,都过了十几分钟了,生产队的驴都不敢休息这么久」。
还有五只疯狂摇头的猫,也占领了评论区一段时间。

小F只能说,太魔性了~
总的来说,媒体类的视频评论较多。
05 分享数TOP10
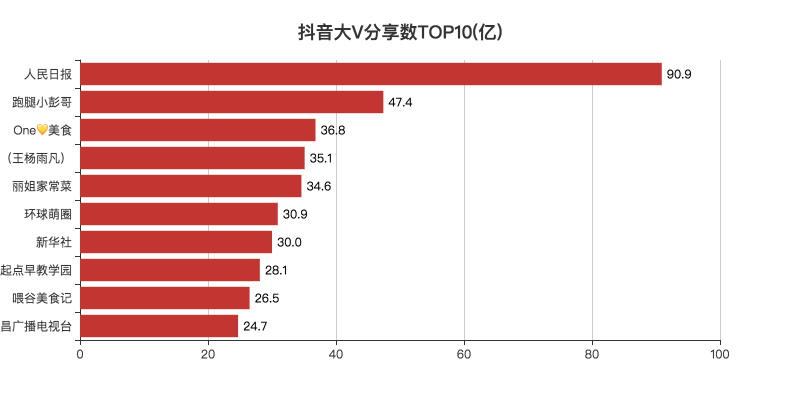
抖音的分享是视频对外传播的一个方法,可以让更多的人看到视频。
从数据上看,大家还是比较喜欢分享新闻类以及美食类的视频。
可能过年疫情,居家一个月的时间,除了葛优躺看新闻,就是吃吃吃。
每个人,也就都有了一个成为大厨的梦想。
06 各类型点赞数/粉丝数汇总分布图
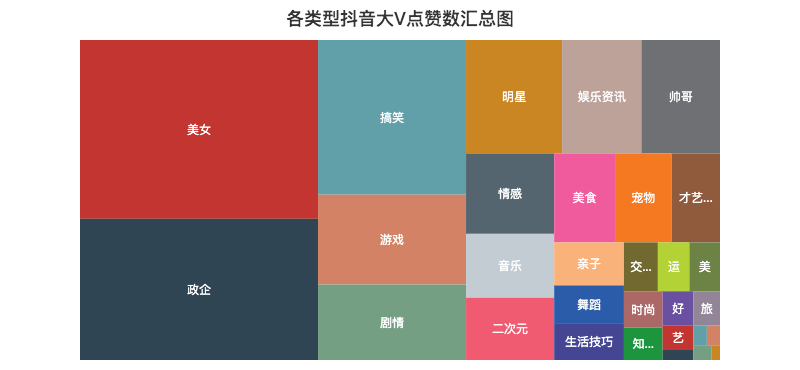
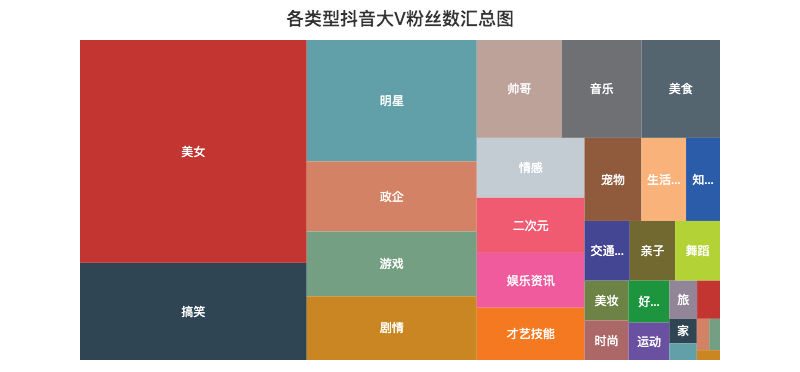
记得曾经一位大佬说过,抖音这个产品是消磨你时间的(Kill Time),而不是节约时间(Save Time),技术稍微深一点的视频基本上生存不下去。
由上面的矩形树图可以知道,大家都喜欢「美女」类型的视频,毕竟谁不喜欢漂亮妹子呢~
比如说深情看铜人的妹子、高考送满天星的妹子,刀小刀等等,妹子爆火的视频太多了...
另外「搞笑」、「游戏」、「剧情」类的视频也比较吸引人,妥妥的Kill Time。
可视化代码如下。
def create_type_likes(df):
# 分组求和
likes_type_message = df.groupby(['category'])
likes_type_com = likes_type_message['likes'].agg(['sum'])
likes_type_com.reset_index(inplace=True)
# 处理数据
dom = []
for name, num in zip(likes_type_com['category'], likes_type_com['sum']):
data = {}
data['name'] = name
data['value'] = num
dom.append(data)
print(dom)
# 初始化配置
treemap = TreeMap(init_opts=opts.InitOpts(width="800px", height="400px"))
# 添加数据
treemap.add('', dom)
# 设置全局配置项,标题、工具箱(下载图片)
treemap.set_global_opts(title_opts=opts.TitleOpts(title="各类型抖音大V点赞数汇总图", pos_left="center", pos_top="5"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
legend_opts=opts.LegendOpts(is_show=False))
treemap.render("各类型抖音大V点赞数汇总图.html")
07 平均视频点赞数/粉丝数TOP10
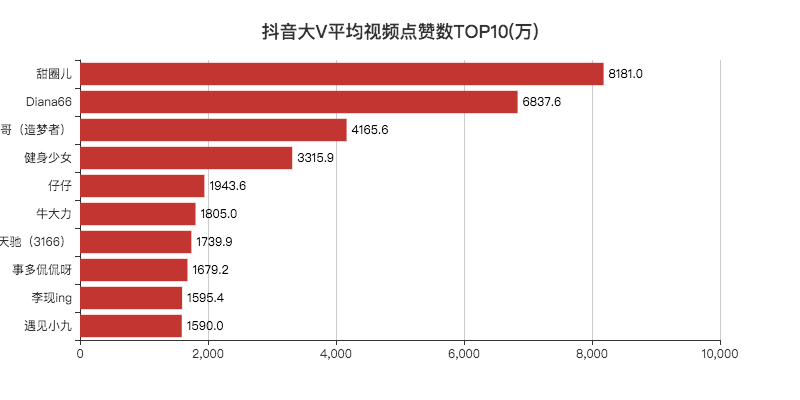
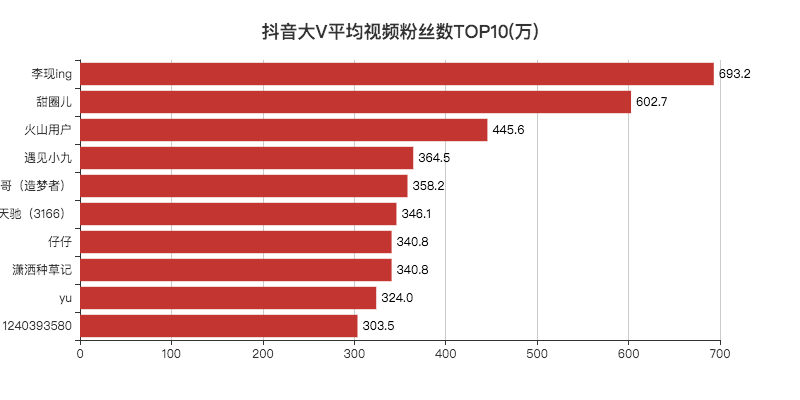
「李现」作为2019年的顶级流量,登顶第一,没啥问题。
其他的博主小F一个也没关注过。
去搜索了一下,发现大部分账号只有一两个视频。
看了评论区,发现原来号被卖掉了,有可能是大V和公司分手了,毕竟现在好多做网红的公司,不火就下一位。
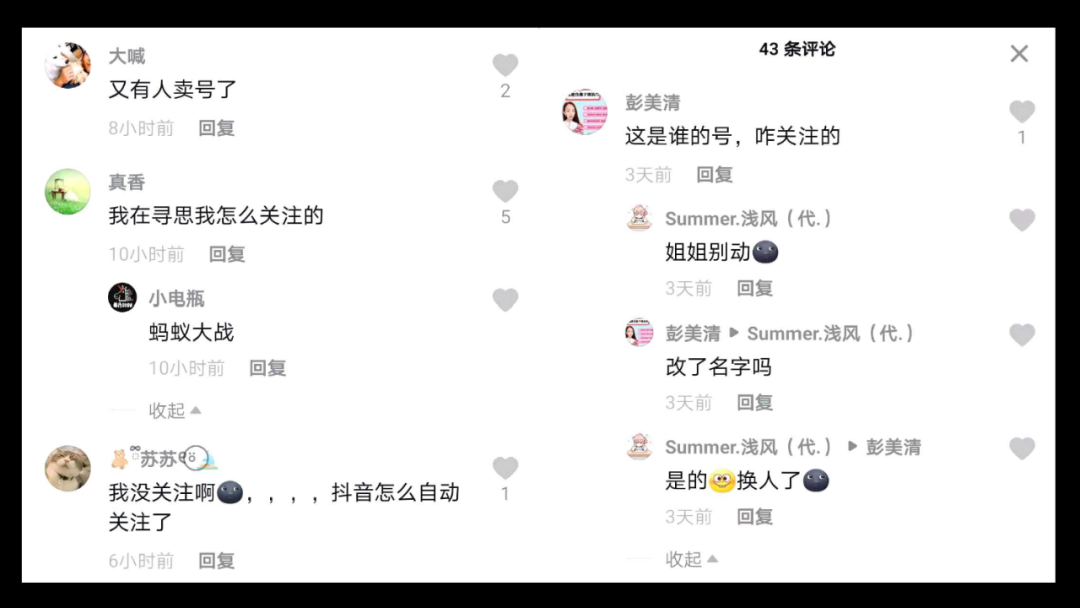
另一种就是个人转让账号,变现赚钱跑路咯。
可视化代码如下。
def create_avg_likes(df):
# 筛选
df = df[df['videos'] > 0]
# 计算单个视频平均点赞数
df.eval('result = likes/(videos*10000)', inplace=True)
df['result'] = df['result'].round(decimals=1)
df = df.sort_values('result', ascending=False)
# 取TOP10
attr = df['name'][0:10]
v1 = ['%.1f' % (float(i)) for i in df['result'][0:10]]
# 初始化配置
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
# 添加数据
bar.add_xaxis(list(reversed(attr.tolist())))
bar.add_yaxis("", list(reversed(v1)))
# 设置全局配置项,标题、工具箱(下载图片)、y轴分割线
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V平均视频点赞数TOP10(万)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
# 设置系列配置项
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
# 翻转xy轴
bar.reversal_axis()
bar.render("抖音大V平均视频点赞数TOP10(万).html")
08 抖音大V分布情况
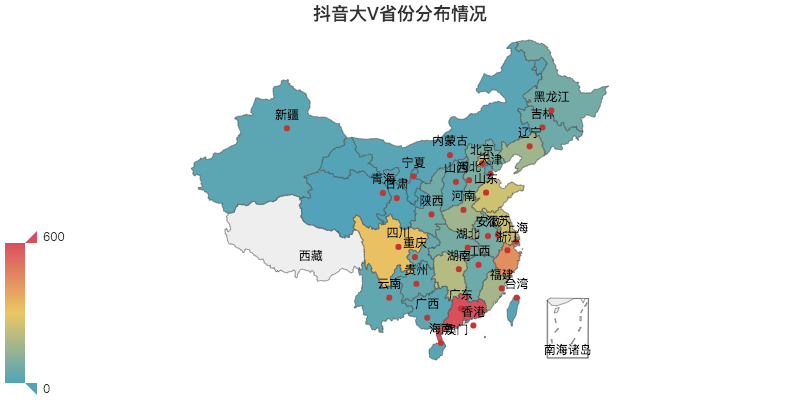
可以看出西藏一个大V都没有,所以没有颜色。
广东、浙江、四川位列前三。
可视化代码如下。
def create_province_map(df):
# 筛选数据
df = df[df["country"] == "中国"]
df1 = df.copy()
# 数据替换
df1["province"] = df1["province"].str.replace("省", "").str.replace("壮族自治区", "").str.replace("维吾尔自治区", "").str.replace("自治区", "")
# 分组计数
df_num = df1.groupby("province")["province"].agg(count="count")
df_province = df_num.index.values.tolist()
df_count = df_num["count"].values.tolist()
# 初始化配置
map = Map(init_opts=opts.InitOpts(width="800px", height="400px"))
# 中国地图
map.add("", [list(z) for z in zip(df_province, df_count)], "china")
# 设置全局配置项,标题、工具箱(下载图片)、颜色图例
map.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V省份分布情况", pos_left="center", pos_top="0"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
# 设置数值范围0-600,is_piecewise标签值连续
visualmap_opts=opts.VisualMapOpts(max_=600, is_piecewise=False))
map.render("抖音大V省份分布情况.html")
省份看完了,来看一下城市TOP10吧。
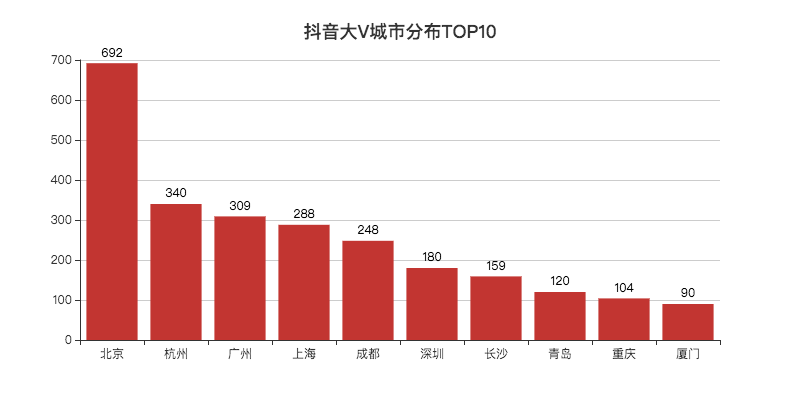
北京遥遥领先,大V的聚集地。
杭州盛产网红的城市,位列第二。
可视化代码如下。
def create_city(df):
df1 = df[df["country"] == "中国"]
df1 = df1.copy()
df1["city"] = df1["city"].str.replace("市", "")
df_num = df1.groupby("city")["city"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
df_city = df_num[:10]["city"].values.tolist()
df_count = df_num[:10]["count"].values.tolist()
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(df_city)
bar.add_yaxis("", df_count)
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V城市分布TOP10", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
bar.render("抖音大V城市分布TOP10.html")
看完国内,就应该是国外了。
抖音上有着不少汉语讲得非常好的「歪果仁」。
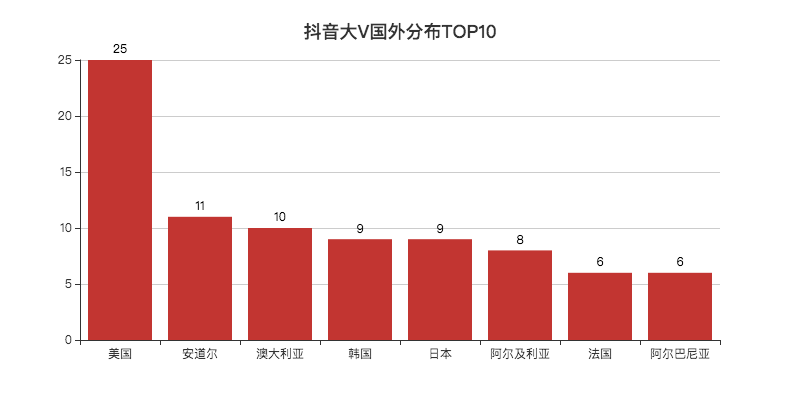
美国居第一,不少在美国的华人会分享他们在美国生活的一些事情。
国内也有人感兴趣这方面的东西,看看国外的月亮究竟圆不圆。
哈哈说笑了,其实是让我们了解国外的生活。
09 抖音大V毕业学校TOP10
北影、中传、浙传、中戏、上戏、央美,妥妥的演艺圈大佬。
通过代码查询一下大V们的认证情况。
df1 = df[(df["custom_verify"] != "") & (df["custom_verify"] != "未知")]
df1 = df1.copy()
df_num = df1.groupby("custom_verify")["custom_verify"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
print(df_num[:20])
得到结果如下。
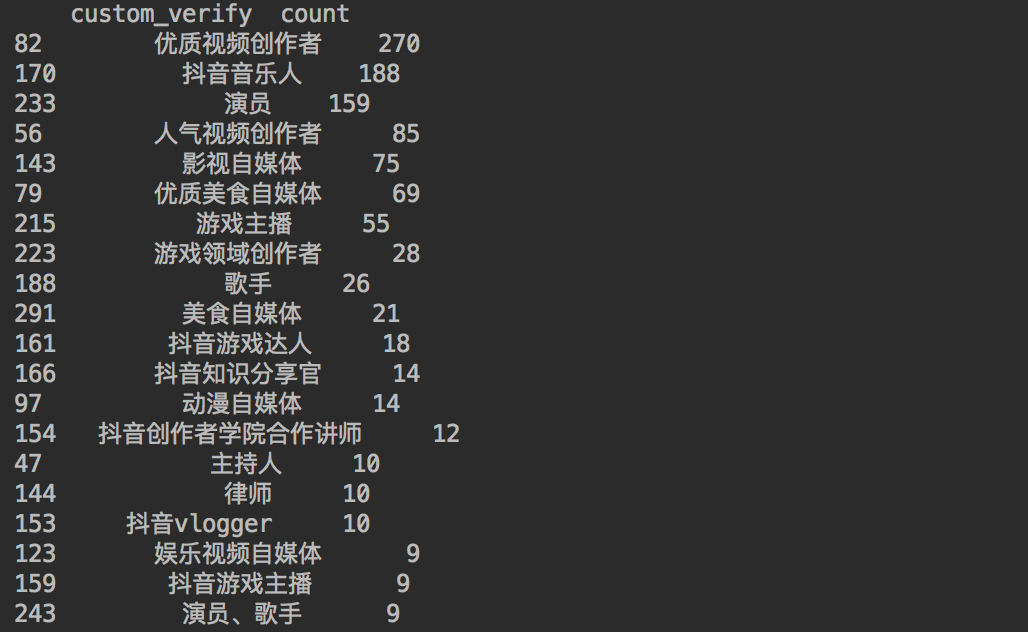
都是需要表演表达天赋的~
10 抖音大V简介词云
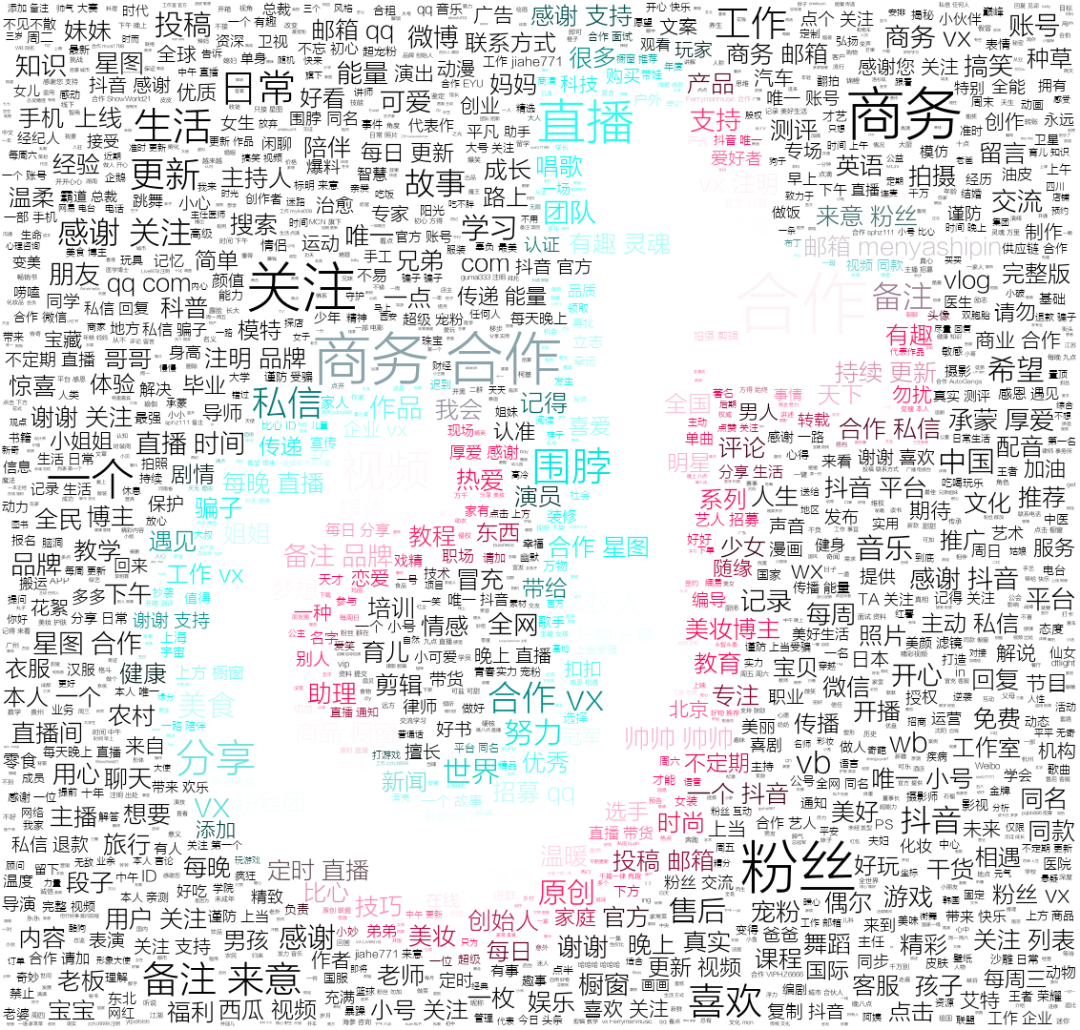
可以看到大部分大V都留下了商务合作的信息,利好内容创作者,如此才能双赢。
据统计,在抖音2200万以上创作者实现了超过417亿元的收入。
从创作到创益,这句话抖音讲的很好。
可视化代码如下。
def create_wordcloud(df, picture):
words = pd.read_csv('chineseStopWords.txt', encoding='gbk', sep='\t', names=['stopword'])
# 分词
text = ''
df1 = df[df["signature"] != ""]
df1 = df1.copy()
for line in df1['signature']:
text += ' '.join(jieba.cut(str(line).replace(" ", ""), cut_all=False))
# 停用词
stopwords = set('')
stopwords.update(words['stopword'])
backgroud_Image = plt.imread('douyin.png')
# 使用抖音背景色
alice_coloring = np.array(Image.open(r"douyin.png"))
image_colors = ImageColorGenerator(alice_coloring)
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='方正兰亭刊黑.TTF',
max_words=2000,
max_font_size=70,
min_font_size=1,
prefer_horizontal=1,
color_func=image_colors,
random_state=50,
stopwords=stopwords,
margin=5
)
wc.generate_from_text(text)
# 看看词频高的有哪些
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
print(sort[:50])
plt.imshow(wc)
plt.axis('off')
wc.to_file(picture)
print('生成词云成功!')
/ 03 / 总结
好了,本期的文章到此就结束。
词云图不是太好看,下次试一下stylecloud库~
恋习Python 关注恋习Python,Python都好练 好文章,我在看❤️