
Python批量下载抖音大V主页视频
上次写了用 Python 批量下载知乎视频的方式,这次分享用 Python 批量下载抖音个人主页的全部无水印视频,本文重点不是提供一个好用的脚本,而是讲述如何写出这样的脚本,正所谓授人以鱼,不如授人以渔,所谓的爬虫,基本都是这个套路。
思路
先说下思路,要批量下载视频,可以先尝试成功下载一个,确定没有水印,然后在写一个循环进行批量下载。
难点:下载一个视频可能很简单,但下载多个就稍微有点复杂,需要抓取多个视频对应的 url,抖音这块做了防爬措施,只允许手机上看到个人主页的视频列表,电脑端的网页却看不到,这就需要抓取手机的 https 包,这里借助 Burpsuite 进行抓包。
这里用到了 Burpsuite ,因此我把自己常用的 Burpsuite 2.1.06 专业版放在了网盘里面,公众号「Python七号」回复「burp」获取,下载后运行 start_burp.bat 或 sh start_burp.sh 即可一键启动,无需购买许可,非常方便。
爬取单个视频
找一个抖音视频链接,点击分享,复制链接,在电脑上用打开,然后打开开发者工具,点击 network 选项。
刷新,看接口,找到返回值里有播放地址的接口:
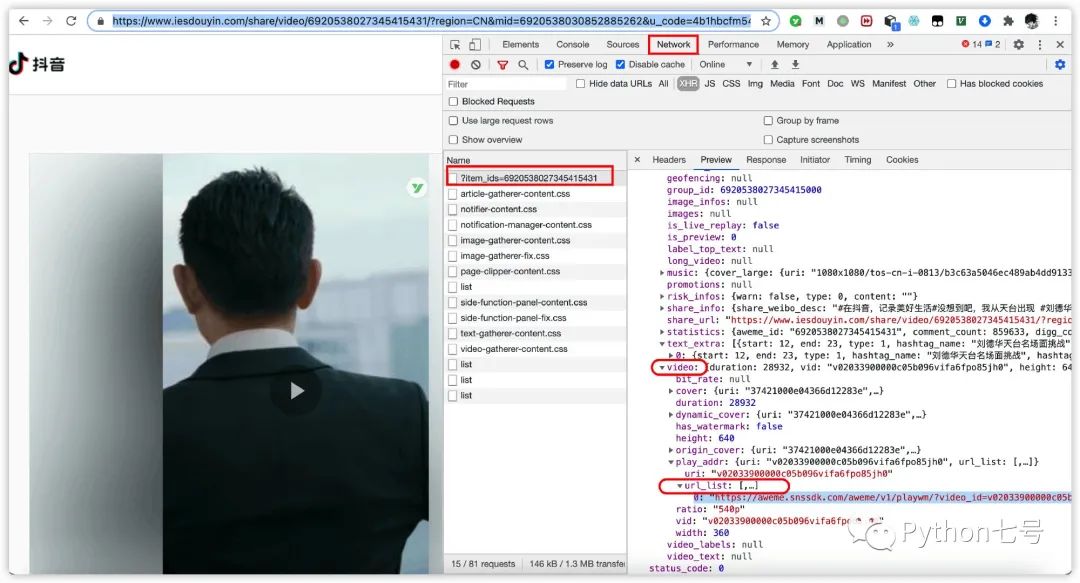
这里面有个 play_addr,内部有个 urllist,我们复制这个 urllist[0] 在浏览器打开,网站跳转到了真正的播放地址,同时可以看到下载的按钮:
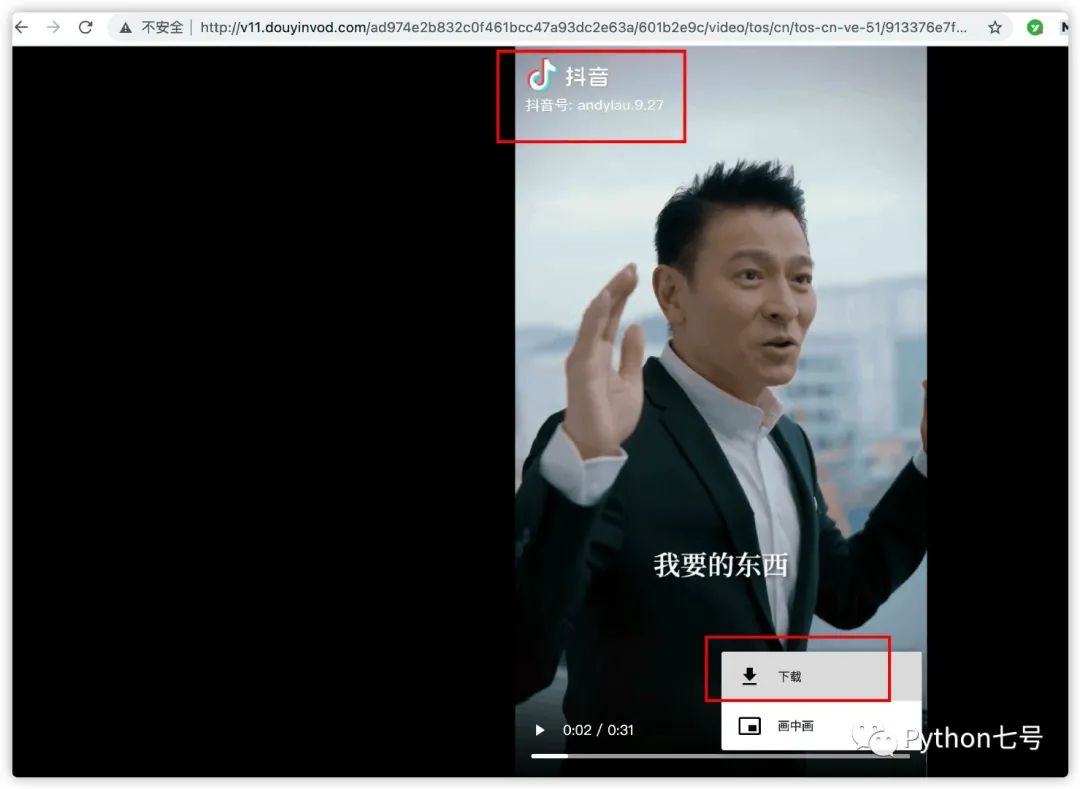
下载这个视频,发现是带水印的,如何下载到不带水印的视频呢?网上搜索了下,方法就是将上述 urllist[0] 中的 playwm 改成 play 就可以了。
然后开始写代码,获取这个 urllist[0],并下载
def get(share_url) -> dict:
"""
share_url -> 抖音视频分享url
返回格式 [{'url':'', 'title','format':'',},{}]
"""
data = []
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
api = "https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={item_id}"
rep = requests.get(share_url, headers=headers, timeout=10)
if rep.ok:
# item_id
item_id = re.findall(r'video/(\d+)', rep.url)
if item_id:
item_id = item_id[0]
# video info
rep = requests.get(api.format(item_id=item_id), headers=headers, timeout=10)
if rep.ok and rep.json()["status_code"] == 0:
info = rep.json()["item_list"][0]
tmp = {}
tmp["title"] = info["desc"]
#去水印的视频链接
play_url = info["video"]["play_addr"]["url_list"][0].replace('playwm', 'play')
tmp["url"] = play_url
tmp["format"] = 'mp4'
data.append(tmp)
return data
if __name__ =='__main__':
videos = get('https://www.iesdouyin.com/share/video/6920538027345415431/?region=&mid=6920538030852885262&u_code=48&titleType=title&did=0&iid=0')
for video in videos:
downloader.download(video['url'],video['title'],video['format'],'./download')
这里 downloader.download 函数,与前文知乎视频下载 里的函数一样,这里就不贴代码了。
获取个人主页视频链接
前两步已经实现了单个抖音视频的无水印下载,现在我们要做的就是找到大量的这种链接,直接循环就可以了。
任意打开一个大 V 的个人主页,分享,复制链接,使用浏览器打开,一个视频也看不到,而使用抖音 App 就可以看到:
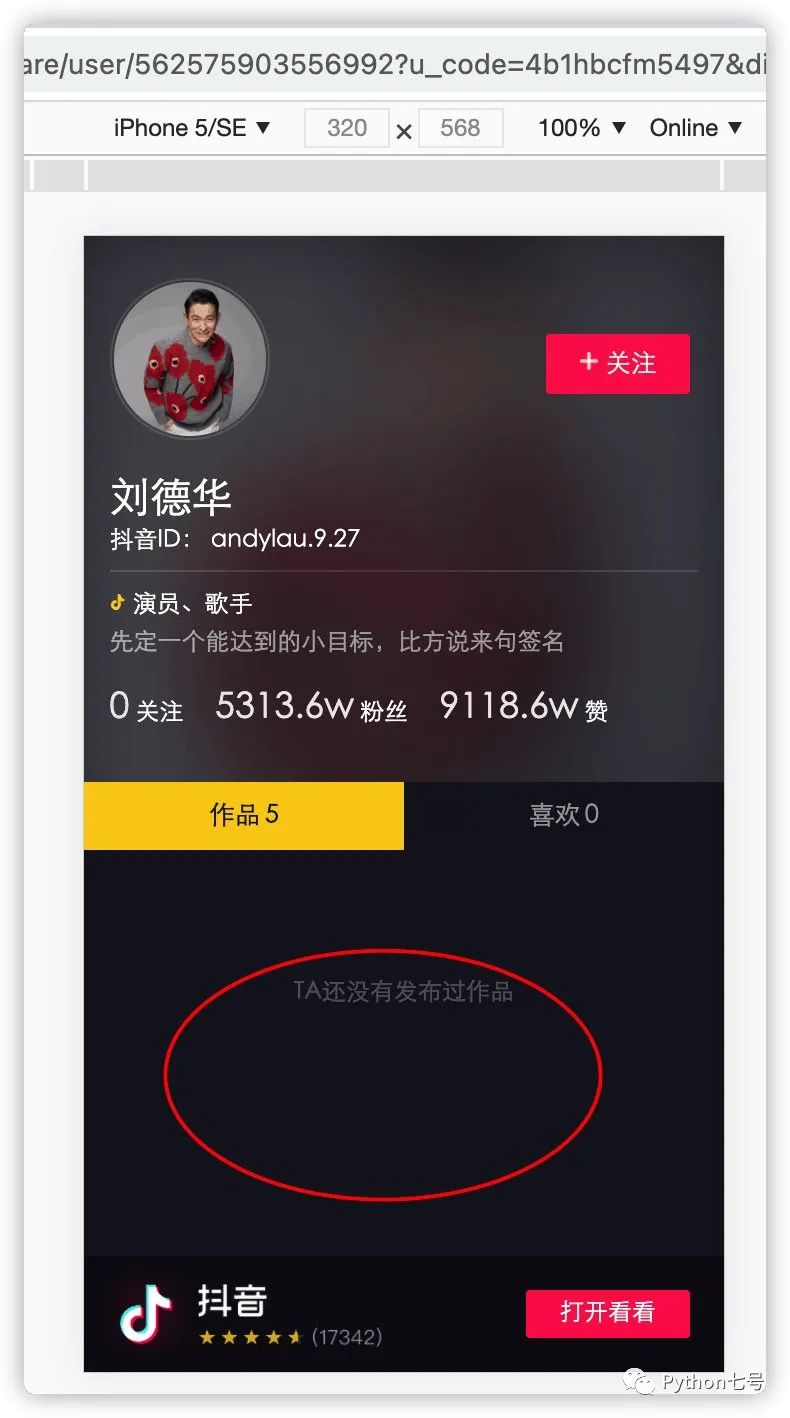
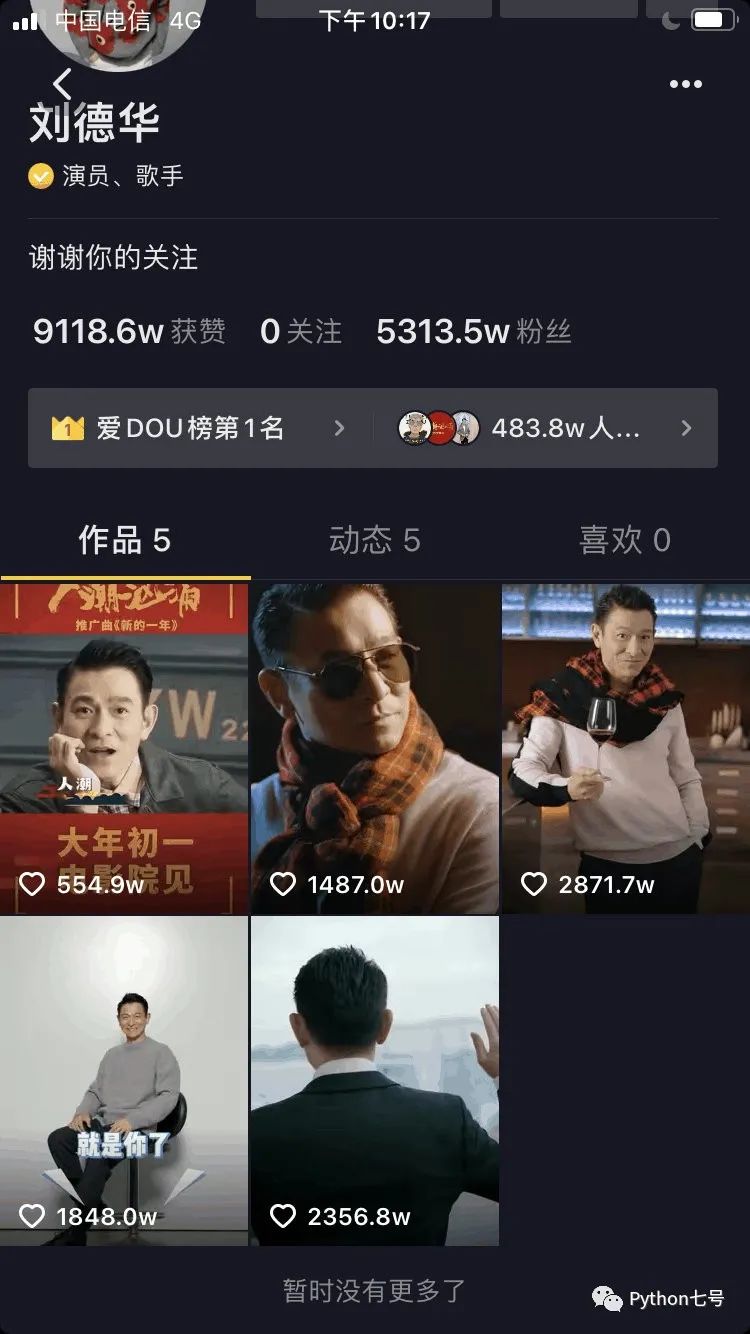
说明抖音做了一定的限制,防止从浏览器看到多个视频的信息。这时就需要学会从手机 APP 来抓包,看看手机上的 http 请求是怎么发起的,然后使用程序来模拟。
我一直在用的 BurpSuite(下面简称 Burp) 非常好用,这里顺便分享下如何使用:
1、运行 Burp。
公众号「Python七号」回复「burp」获取,下载后运行 start_burp.bat 或 sh start_burp.sh 来启动 Burp,然后打开代理设置,绑定到运行 Burp 的机器 IP,如下图所示:
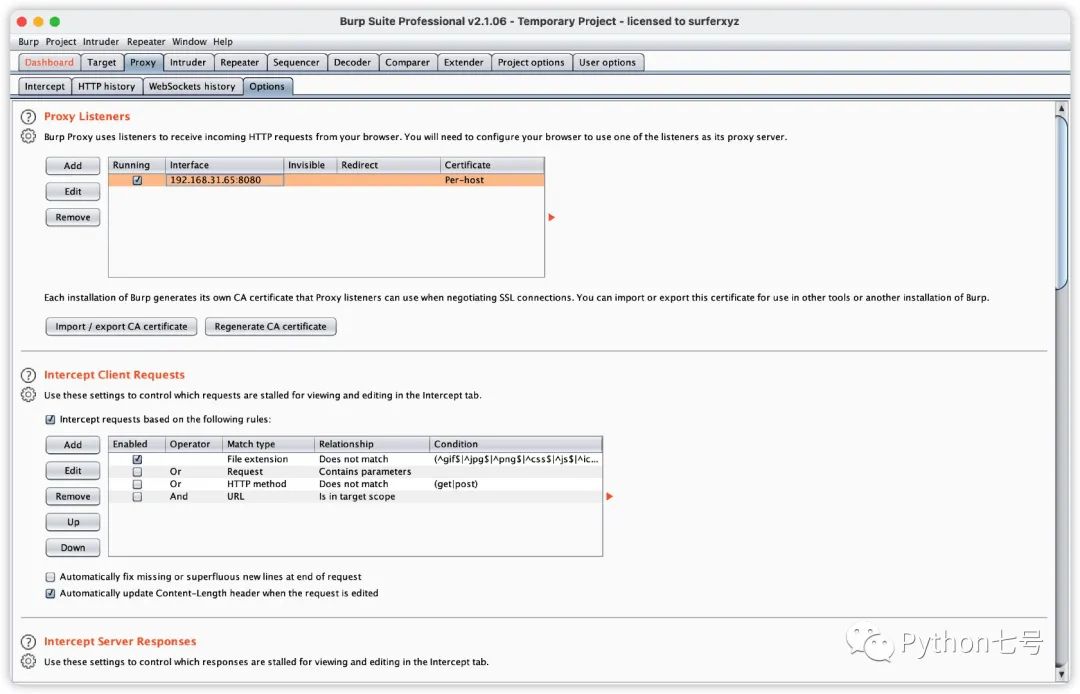
注意不要设置 ip 为 127.0.0.1,这样设置的话,只有本地请求可以使用代理,手机无法连接此代理。
2、手机设置代理。
手机与电脑连接同一 wifi,IPhone 的操作如下:然后进入设置-> 无线局域网 -> 点击同一 wifi 右边的 information 符号,然后下拉,点击配置代理,配置和 BurpSuite 一样的 ip 和端口。Android 的手机的设置也差不多。至此可以在 BurpSuite 上抓取手机的 http 流量。
3、手机下载 Burp 的证书,并设置信任。
手机浏览器 进入 http://burp。 点击 CA 下载证书。 设置->通用->描述文件->点击 PortSwigger CA->安装 设置->通用->关于本机->证书信任设置,将 BurpSuite 的证书开启
这样就可以抓取手机上发起的 https 包了。
4、设置 BurpSuite 中断。
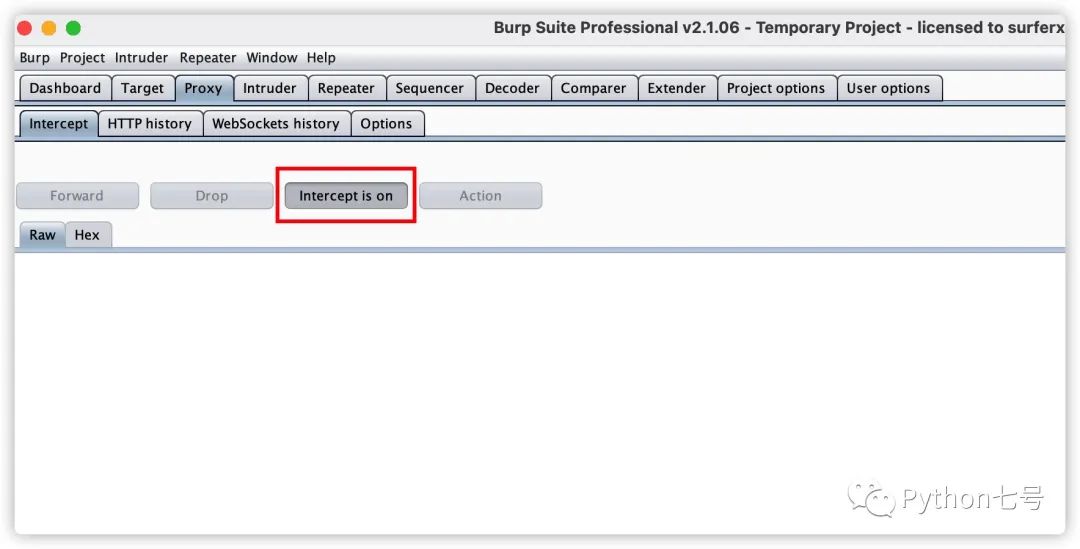
这一步骤设置之后,手机上的请求会在这里阻塞,你可以放行选择放行,或修改数据包后放行,也可以发往 repeater,以便后续重放请求,因此来自前端的请求是不可信的。
现在打开手机上的抖音 App,这里便会出现大量的请求阻塞在这里,我们选择放行,会发现抖音 App 里的数据一步一步的出现。快刷到个人主页的视频之前,将请求发到 Repeater,如下图所示:
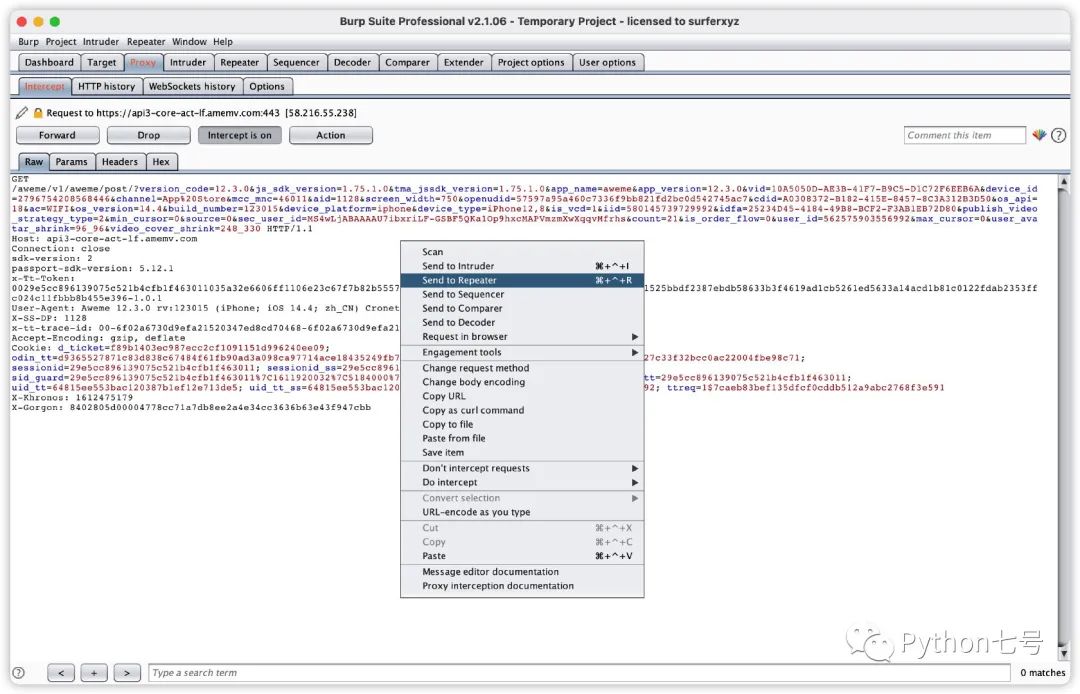
然后打开 BurpSuite 的 Repeater 选项卡,就可以看到刚才发过来的请求,这时我们选择重放,看数据,决定我们需要使用的接口,如下图所示:
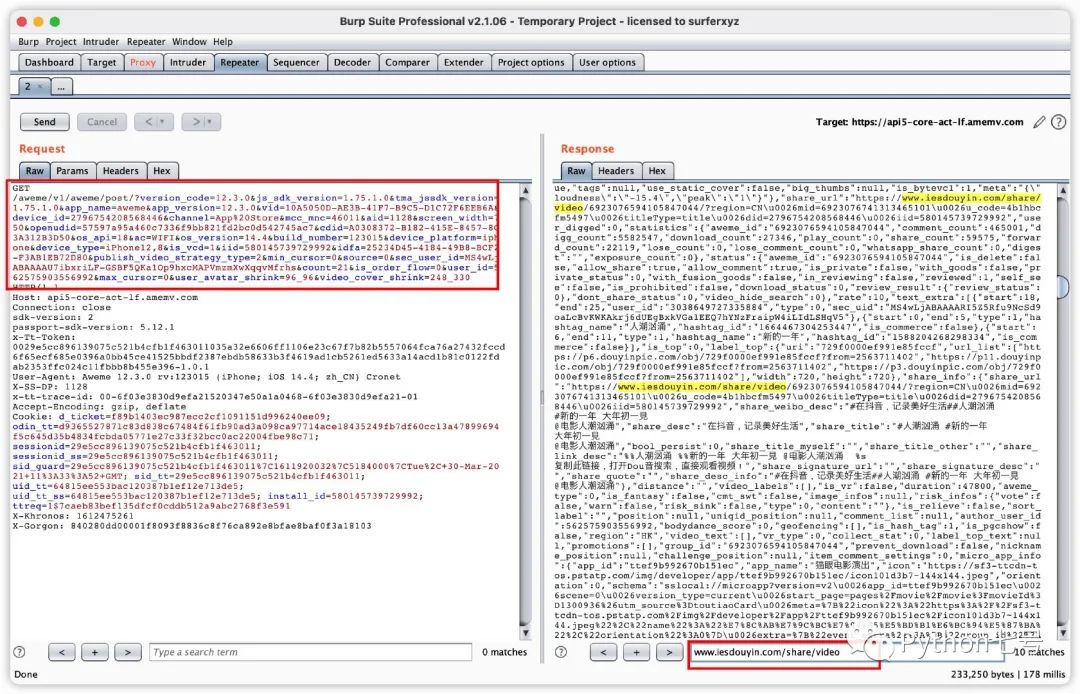
发现这个接口满足请求,这里可以看到接口的 url,headers 的各种参数,headers 中的 User-Agent 参数,是区分客户端是浏览器还是 App 的重要标识,因此就可以写代码来模拟请求,进而获取需要的批量下载链接。
由于 url 中的参数非常多,有些是固定不变的,有些随着不同人的主页参数会发生变化,如果仅仅是自己使用,可以简单的通过正则表达式来提取这些 url 链接,然后进行批量下载就可以了。
如果是想写好一个脚本供别人使用,那么就需要做更多的工作,比如说,需要查看更多的 api,以便确定 url 及 headers 中的参数是如何获取或生成的,然后写脚本自动化这一过程,有些情况下,还涉及到加密混淆等反爬措施,这里就不再展开了,请感兴趣的读者自行探索。
最后的话
爬取视频的关键在于找到视频的播放地址,有了播放地址,即使不写代码,也可以使用浏览器下载,寻找播放地址还不够,要考虑是否能去水印,如果要批量下载,那就要知道如何获取更多的视频链接,在浏览器抓取不到的时候,考虑使用 BurpSuite 抓取手机的流量包,进一步提取接口的数据,或模拟手机请求,对搞爬虫的同学,BurpSuite 是一个瑞士军刀,非常实用。
如果本文对你有所帮助,请点个赞或再看吧,谢谢支持。