
神经符号学习: 神经网络+逻辑推理
-
提出具有理论收敛保证的DeepLogic框架,该框架进行神经感知和逻辑推理的联合学习,使它们可以相互增强,以提高神经符号推理的性能和可解释性。
-
提出源自一阶逻辑的深度逻辑模块(DLM),能够从基本逻辑运算符构造和学习逻辑公式。
- 提出了深度逻辑优化(DLO)算法,通过理论上量化神经感知和逻辑推理之间的相互监督信号来保证神经感知和逻辑推理的联合学习。
2 DeepLogic框架 神经符号学习研究同时感知和推理的问题,其输入是语义数据,输出是未知的复杂关系。为避免任务分解,不应给出要学习的语义输入的符号属性。DeepLogic框架从数学角度描述了问题表述和建模,并提出了用于联合学习神经感知和符号推理的深度&逻辑优化(DLO)算法。 通过我们提出的DeepLogic框架,我们可以通过1位监督信号来共同学习感知能力和逻辑公式,指示语义输入是否满足给定的公式,如图1所示。 前向传递(顶部)从语义输入x通过中间符号属性z到最终演绎标签y进行顺序处理。 例如,推理一下1,2和3的关系。首先,系统通过神经感知模型将这些图像识别为符号:➊、➋和➌。然后,逻辑推理模型对➊、➋、➌之间的关系进行推理,得出满足逻辑公式:“➊加➋等于➌”的结论。在后向传递中(左下/右下),感知模型θ和符号系统φ的参数分别以另一个作为监督进行迭代优化。
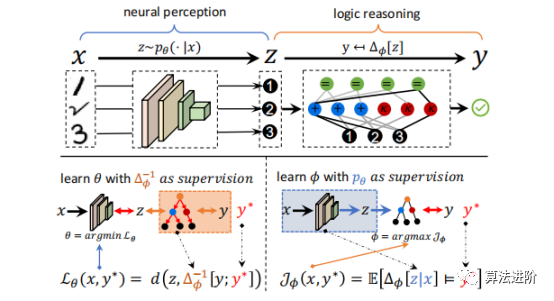 图1 DeepLogic框架 3 深度逻辑模块(DLM)
图1 DeepLogic框架 3 深度逻辑模块(DLM) 深度逻辑模块(DLM),能够对神经感知和逻辑推理进行建模。特别是,拟议的DLM具有以下优点:
-
DLM不依赖外部知识,易于实现;
-
DLM通过由浅入深的逻辑层堆叠,自适应适应各种场景;
- DLM能够利用监督信息来优化pθ和pφ,保证神经感知和逻辑推理的联合学习。
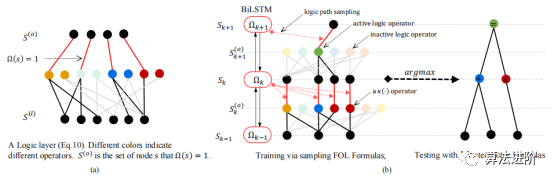
深度逻辑模块(DLM),是一个基于FOL的通用公式学习器,能够学习符号之间的符号关系。在本节中,我们将介绍DLM与深度神经网络(DNN)如何通过吸收语义输入并推理其符号关系来处理神经符号任务。我们还详细介绍了所提出的深度逻辑优化(DLO)算法,以联合优化DLM和DNN。
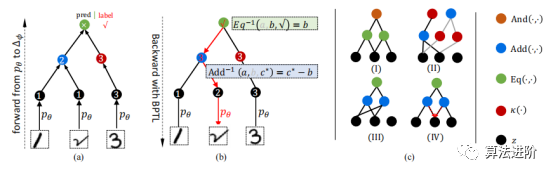 图 3(a)DeepLogic 从 pθ 到 Δφ 的前向传播。(b)DeepLogic 使用 BPTL 算法的反向传播(算法1)。(c)Deeplogic 公式的几种情况说明:(I)“And(Eq(Z1,Z2),Eq(Z2, Z3))”的公式;(II)两层定义同一个术语“Add(Z1,Z2)”的情况(黑线和灰线);(III)和(IV)公式的病态/自冲突情况;(III)中,方程始终为“True”,而在(IV)中,BPTL算法会在中间节点遇到自冲突。 5 实验
图 3(a)DeepLogic 从 pθ 到 Δφ 的前向传播。(b)DeepLogic 使用 BPTL 算法的反向传播(算法1)。(c)Deeplogic 公式的几种情况说明:(I)“And(Eq(Z1,Z2),Eq(Z2, Z3))”的公式;(II)两层定义同一个术语“Add(Z1,Z2)”的情况(黑线和灰线);(III)和(IV)公式的病态/自冲突情况;(III)中,方程始终为“True”,而在(IV)中,BPTL算法会在中间节点遇到自冲突。 5 实验 在本节中,我们在三个逻辑推理数据集上评估所提出的DeepLogic框架的性能、收敛性、稳定性和泛化能力。第一个和第二个数据集是根据具有多个属性和不同规则的MNIST手动构建的,而第三个数据集是广泛使用的推理数据集,旨在评估机器的推理能力。 5.1 MNIST-ADD MNIST-ADD是一个简单的个位数加法数据集。任务是在给定三个MNIST图像和1位“True/False”标签的情况下学习“个位数加法”公式。该数据集包括20,000个用于训练的实例和20,000个用于测试的实例。我们使用不同的分割策略将数据集进一步分割为α和β分割。在β分割中,测试集具有与训练集中的实例不同的附加实例。这种设置也称为“训练/测试分布偏移”,这对于神经网络来说很难解决。 结果总结如表1。 在MNSIT-ADd-α和MNIST-ADD-β数据集上,DNN模型过度拟合训练集。尽管尝试使用改变模型大小和dropout等方法,但效果不佳。DNN模型在逻辑准确性方面表现较差,尤其是在处理不平衡的β分裂时。与ABL模型相比,我们的模型更加灵活,无需Prolog程序即可达到更高的精度。最后,通过逻辑的反向传播有助于为感知模型提供监督。
表1:MNIST-ADD数据集上的准确性,其中EXTRA SUP表示模型是否使用额外的感知监督或仅一位逻辑监督进行训练,EXTRA TOOL表示模型是否使用任何额外的工具
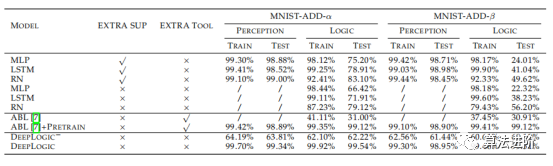
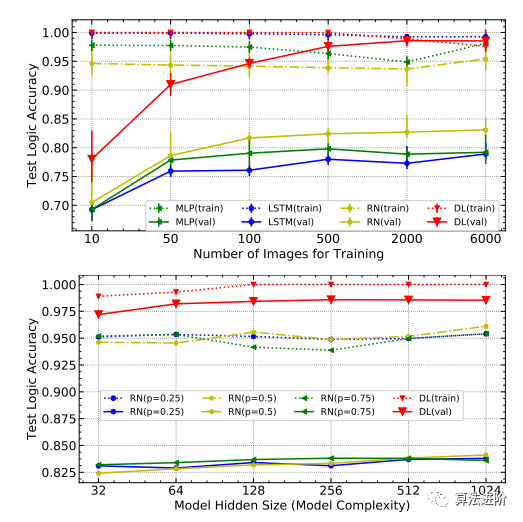
图 4 上图: 在 MNIST-ADD- α上使用不同尺度的训练图像测试准确性, DL 是 DeepLogic 的缩写; 下图: 测试不同模型隐藏大小以及 RN 和 DL 的不同 dropout 概 率的准确性。
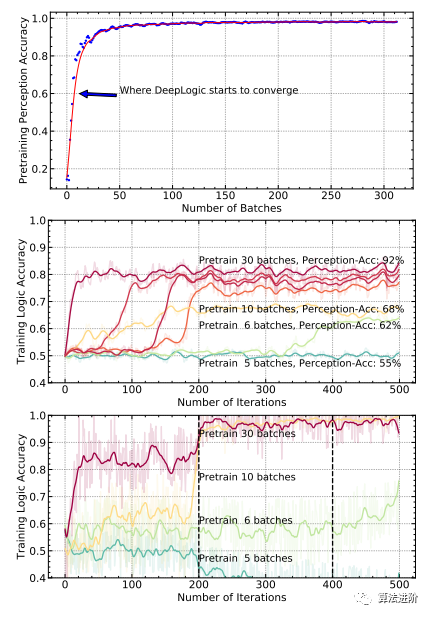
图 5 上 图 : 在 MNIST-ADD- α数据集上预训练 p θ时的 PERCEPTION 准确度; 中图: 在 MNIST-ADD- α数据集上使用不同批次的预训 练数据训练 DeepLogic- 的 LOGIC 准确性; 下图: 在 MNIST-ADD- α数据集上使用不同批次的预 训练数据训练 DeepLogic 的 LOGIC 准确 性。 主要发现是: 1 )更多的预训练批次确保了更好的准确性; 2 ) DeepLogic 最终收敛只需要很少 的预训练。
模型稳定性。 此任务采用两个术语层和一个公式层来学习特定逻辑,但实际应用可能受限。 实验表明(表3) ,系统在不同设置下学习效果不同,模型收敛容易,对不同初始化具有鲁棒性。
表3 MNIST-ADD数据集中不同设置下学习的典型公式。M表示术语层数,N表示公式层数。最后一列是5次随机试验中成功收敛的百分比。

C-MNIST-RULE是MNIST-ADD的扩展,其中包含一个额外的属性“颜色”和两个额外的公式“级数”和“互斥”。请注意,我们对MNIST-ADD和C-MNIST-RULE使用相同的DeepLogic模型,唯一的区别在于输出公式Δφ的数量,在C-MNIST-RULE中为1,而在C-MNIST-RULE中为3。DeepLogic能够同时学习多个公式和感知。
C-MNIST-RULE包含多个规则和属性,其中我们对MNIST图像进行着色以添加颜色属性,并根据Raven的渐进矩阵(RPM)实现三个规则。与MNIST-ADD类似,C-MNISTRULE数据集包含20,000个训练实例和20,000个测试实例。
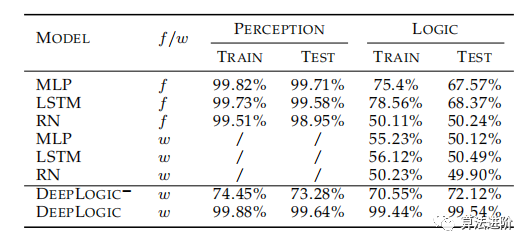
表2展示了不同模型在C-MNIST-RULE上的准确性。其中f表示模型使用额外的符号注释进行训练,w表示不涉及额外的符号注释。DeepLogic−不进一步训练pθ。DeepLogic和DeepLogic−均经过10个批次的预训练。LOGIC是最终预测y的准确性,而PERCEPTION是预测隐藏符号z的准确性。
表2 不同模型在C-MNIST-RULE的准确性
-
与 CMNIST-RULE 上没有符号注释的结果相比,纯基于 DNN 的方法性能较差。
- 基于纯DNN的方法在额外符号注释的帮助下收敛,这也与[15]一致,其中纯DNN甚至ResNet无法比没有额外注释的随机猜测表现得更好。
-
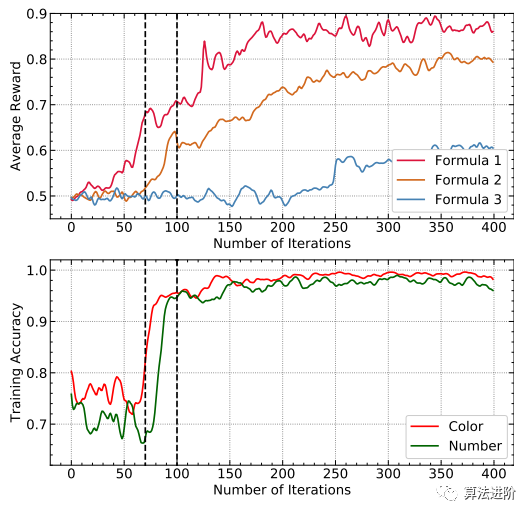
公式1收敛速度快。
-
收敛公式1监督Color属性收敛。
- 融合的Color属性进一步促进了公式2和其他公式的学习。
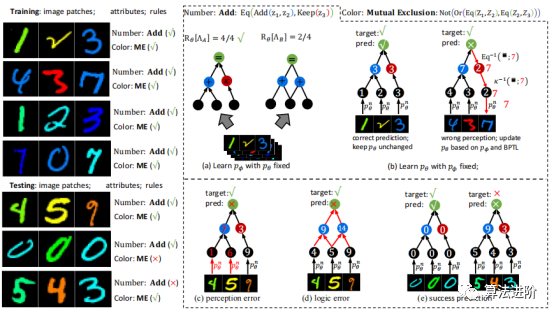
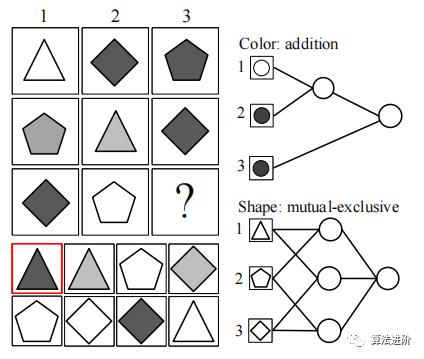
图 8 RPM 任务中 的 DLM 模块图示。 图像被视为输入,然后输入逻辑层,其中逻辑操作是 从所有 可能的候选组合中选择的。
Soft-DLM模块替换CoPINet中的原始融合方法后,性能得到显著提升, 如表4所示, 特别是在“2×2”和“3×3”的情况下。这验证了DeepLogic的泛化能力和在连续领域的潜力。表4 在RAVEN数据集上测试准确性。ACC是最终的准确率,其他列代表不同的任务配置

更多精彩内容请点击:AI领域文章精选! 关注👇公众号,后台回复【DeepLogic】可下载论文及代码
