
京东二面:高并发设计,都有哪些技术方案?

源 / 微观技术 文/ Tom哥
作为互联网从业者,高并发一直是我们绕不开的一个话题。
那么高并发系统都有哪些经验,掌握核心技巧,你可以快速成为一个架构师,主导一些高访问量系统的架构设计
然后,升职加薪自然也就是水到渠成的事。
一、负载均衡
靠优化单台机器的内存、CPU、磁盘、网络带宽,使其发挥极致性能,已经不太现实。
正所谓 "双拳难敌四手,恶虎还怕群狼",现在早已经是分布式时代,靠的是shu量取胜,也称之为水平伸缩方案
这么多的系统,如何流量调度,这里的第一道入口就是负载均衡
负载均衡,它的职责是将网络请求 “均摊”到不同的机器上。避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况
通过负载均衡,可以让每台服务器获取到适合自己处理能力的负载。在为高负载服务器分流的同时,还可以避免资源浪费,一举两得。
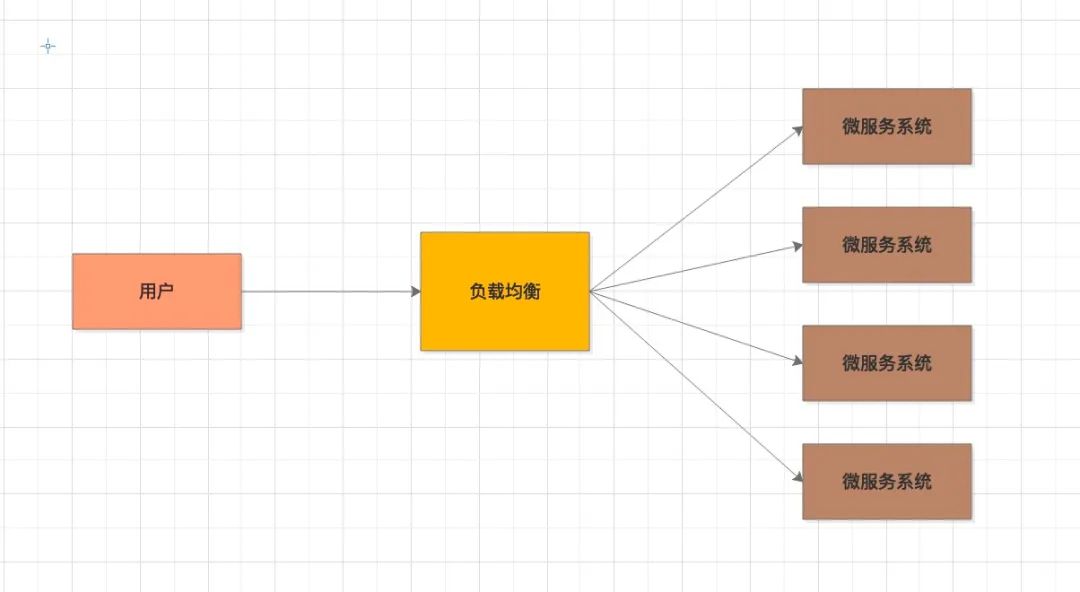
常见的负载算法:
随机算法 轮询算法 轮询权重算法 一致性哈希算法 最小连接 自适应算法
常用负载均衡工具:
LVS Nginx HAProxy
对于一些大型系统,一般会采用 DNS+四层负载+七层负载的方式进行多层次负载均衡。
二、分布式微服务
过去是一个大而全的系统,面对复杂的业务规则,我们采用分而治之的思想,通过SOA架构,将一个大的系统拆分成若干个微服务,粒度越来越小,称之为微服务架构
每个微服务独立部署,服务和服务间采用轻量级的通信机制,如:标准的HTTP协议、或者私有的RPC协议。
微服务特点:
按照业务划分服务,单个服务代码量小,业务单一,容易维护 每个微服务都有自己独立的基础组件,例如数据库 微服务之间的通信是通过HTTP协议或者私有协议,且具有容错能力 微服务有一套服务治理的解决方案,服务之间不耦合,可以随时加入和剔除 单个微服务能够集群化部署,有负载均衡的能力 整个微服务系统应该有完整的安全机制,包括用户验证,权限验证,资源保护 整个微服务系统有链路追踪的能力 有一套完整的实时日志系统
市面常用微服务框架有:Spring Cloud 、Dubbo 、kubernetes、gRPC、Thrift 等
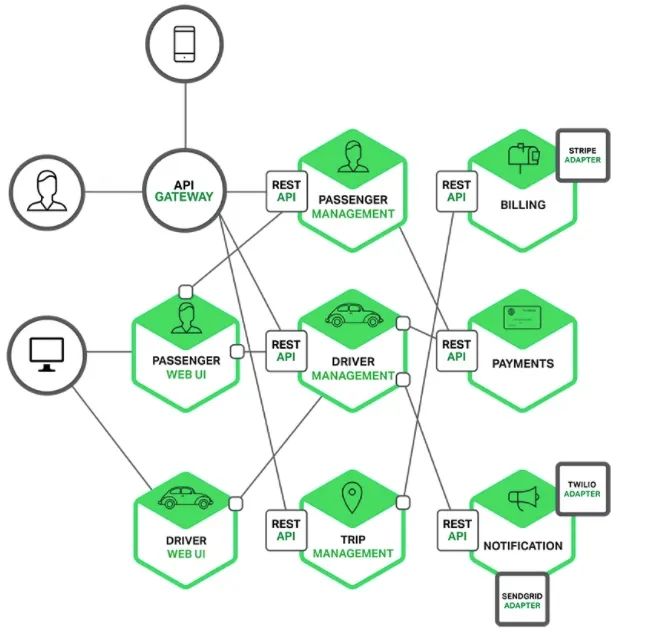
这么多的微系统之间如何感知?这里面会引入注册中心。
常用的注册中心有:Zookeeper、etcd、Eureka、Nacos、Consul
万事有利就有弊,分布式微服务由于拆分的过细,引入一些复杂化问题需要关注:
分布式事务 限流机制 熔断机制 网关 服务链路追踪
三、缓存机制
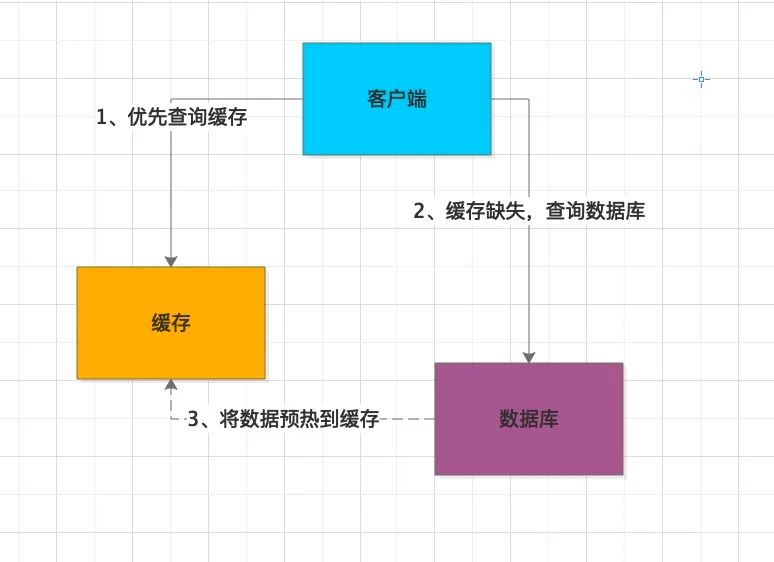
性能不够,缓存来凑。要想快速提升性能,缓存肯定少不了
缓存能够带来性能的大幅提升,以 Memcache 为例,单台 Memcache 服务器简单的 key-value 查询能够达到 TPS 50000 以上;Redis性能数据是10W+ QPS
为什么缓存的速度那么快?
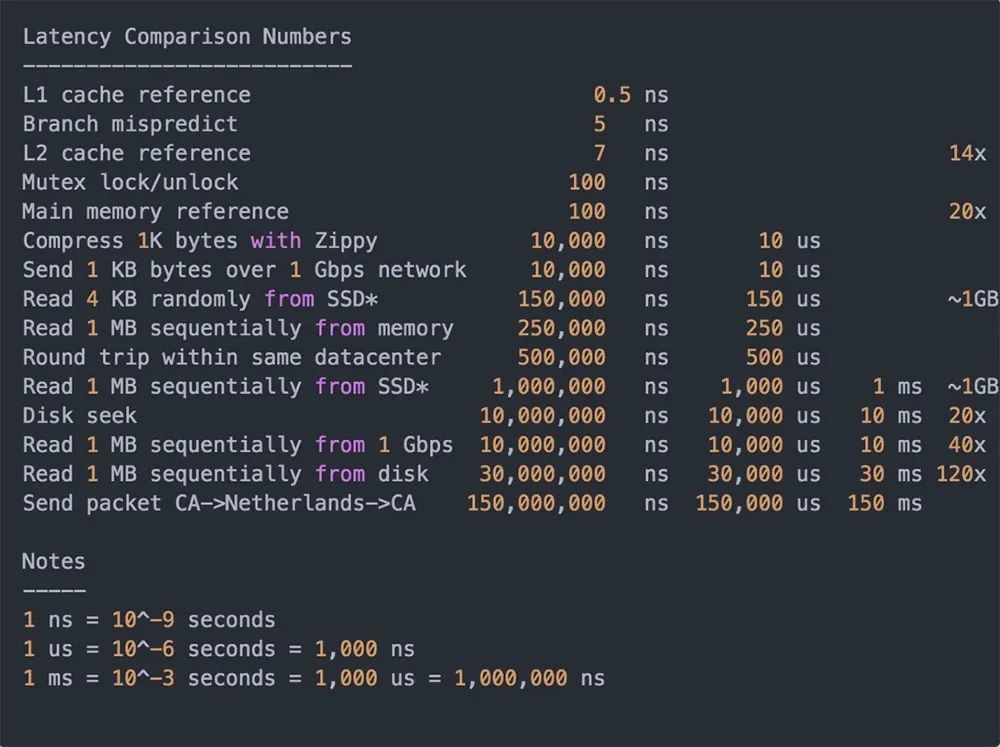
从上图中发现,同机房两台服务器跑个来回,再从内存中顺序读取1M数据,共耗时0.75ms。如果从硬盘读取,做一次磁盘寻址需要10ms,再从磁盘里顺序读取1M数据需要30ms。可见,使用内存缓存性能上提高多个数量级,同时也能支持更高的并发量。
常见的缓存分为本地缓存和分布式缓存,区别在与是否要走网络通讯。
本地缓存是部署在应用服务器中,而我们应用服务器通常会部署多台,当数据更新时,我们不能确定哪台服务器本地中了缓存,更新或者删除所有服务器的缓存不是一个好的选择,所以我们通常会等待缓存过期。因此,这种缓存的有效期很短,通常为分钟或者秒级别,以避免返回前端脏数据。
相反,分布式缓存采用集群化管理,支持水平扩容,并提供客户端路由数据,数据一致性维护更好。虽然有不到 1ms 的网络开销,但比起其优势,这点损耗微不足道。
缓存更新常用策略?
Cache aside,通常会先更新数据库,然后再删除缓存,为了兜底还会设置缓存时间。 Read/Write through, 一般是由一个 Cache Provider 对外提供读写操作,应用程序不用感知操作的是缓存还是数据库。 Write behind,延迟写入,Cache Provider 每隔一段时间会批量写入数据库,大大提升写的效率。像操作系统的page cache也是类似机制。
四、分布式关系型数据库
MySQL数据库采用B+数索引,三层结构,为了保证IO性能,一般建议单表存储 千万 条数据。
如果遇到单机数据库性能瓶颈,我们可以考虑分表。
分表又可以细分为 垂直分表 和 水平分表 两种形式。
1、垂直分表
数据表垂直拆分就是纵向地把一张表中的列拆分到多个表,表由“宽”变“窄”,简单来讲,就是将大表拆成多张小表,一般会遵循以下几个原则:
冷热分离,把常用的列放在一个表,不常用的放在一个表。 字段更新、查询频次拆分 大字段列独立存放 关系紧密的列放在一起
2、水平分表
表结构维持不变,对数据行进行切分,将表中的某些行切分到一张表中,而另外的某些行又切分到其他的表中,也就是说拆分后数据集的并集等于拆分前的数据集。
分库分表技术点:
SQl组合。因为是逻辑表名,需要按分表键计算对应的物理表编号,根据逻辑重新组装动态的SQL 数据库路由。如果采用分库,需要根据逻辑的分表编号计算数据库的编号 结果合并。如果查询没有传入指定的分表键,会全库执行,此时需要将结果合并再输出。
目前市面有很多的开源框架,大致分为两种模式:
Proxy模式。SQL 组合、数据库路由、执行结果合并等功能全部存放在一个代理服务中,业务方可以当做。
优点:支持多种语言。升级方便。对业务代码无侵入。 缺点:额外引入一个中间件,容易形成流量瓶颈,安全风险较高,有运维成本 Client 模式。常见是
sharding-jdbc,业务端系统只需要引入一个jar包即可,按照规范配置路由规则。jar 中处理 SQL 组合、数据库路由、执行结果合并等相关功能。优点:简单、轻便。不存在流量瓶颈,减少运维成本 缺点:单语言,升级不方便。
实现思路:
1、如何选择分表键。
数据尽量均匀分布在不同表或库、跨库查询操作尽可能少、这个字段的值不会变。比如电商订单采用user_id。
2、分片策略。
根据范围分片、根据 hash 值分片、根据 hash 值及范围混合分片
3、如何编写业务代码。结合具体的业务实现。
4、历史数据迁移
增量数据监听 binlog,然后通过 canal 通知迁移程序开始增量数据迁移 开启任务,全量数据迁移 开启双写,并关闭增量迁移任务 读业务切换到新库 线上运行一段时间,确认没有问题后,下线老库的写操作
有一种说法:数据量大,就分表;并发高,就分库
在实际的业务开发中,要做好数据量的增长预测,做好技术方案选型。另外,在引入分表方案后,要考虑数据倾斜问题,这个跟分表键有很大关系,避免数据分布不均衡影响系统性能。
五、分布式消息队列
并不是所有的调用都要走同步形式,对于时间要求不高、或者非核心逻辑,我们可以采用异步处理机制。
也就衍生出消息队列。
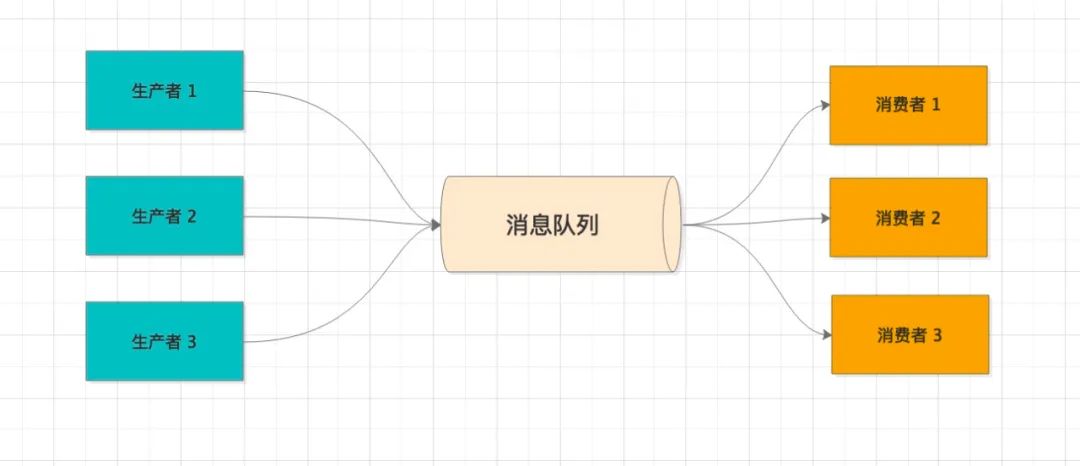
消息队列主要有三种角色:生产者、消息队列、消费者。
生产端核心的逻辑处理完后,会封装一个MQ消息,发送到消息队列。下游系统,如果关心这个事件,只需要订阅这个 topic ,便可以收到消息,进行后续的业务逻辑处理。
两者之间通过消息中间件完成了解耦,系统的扩展性非常高。
常用的消息框架有哪些?
ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaQ,RocketMQ、Pulsar 等
消息队列的应用场景?
1、异步处理。将一个请求链路中的非核心流程,拆分出来,异步处理,减少主流程链路的处理逻辑,缩短RT,提升吞吐量。如:注册新用户发短信通知。 2、削峰填谷。避免流量暴涨,打垮下游系统,前面会加个消息队列,平滑流量冲击。比如:秒杀活动。生活中像电源适配器也是这个原理。 3、应用解耦。两个应用,通过消息系统间接建立关系,避免一个系统宕机后对另一个系统的影响,提升系统的可用性。如:下单异步扣减库存 4、消息通讯。内置了高效的通信机制,可用于消息通讯。如:点对点消息队列、聊天室。
六、CDN
CDN 全称 (Content Delivery Network),内容分发网络。
目的是在现有的网络中增加一层网络架构,将网站的内容发布到最接近用户的网络“边缘”,使用户可以就近取得所需的内容,提高用户访问网站的响应速度。
CDN = 镜像(Mirror)+缓存(Cache)+整体负载均衡(GSLB)
CDN都以缓存网站中的静态数据为主,如:CSS、JS、图片和静态页面等数据。用户从主站服务器中请求到动态内容后,再从CDN下载静态数据,从而加速网页数据内容的下载速度。
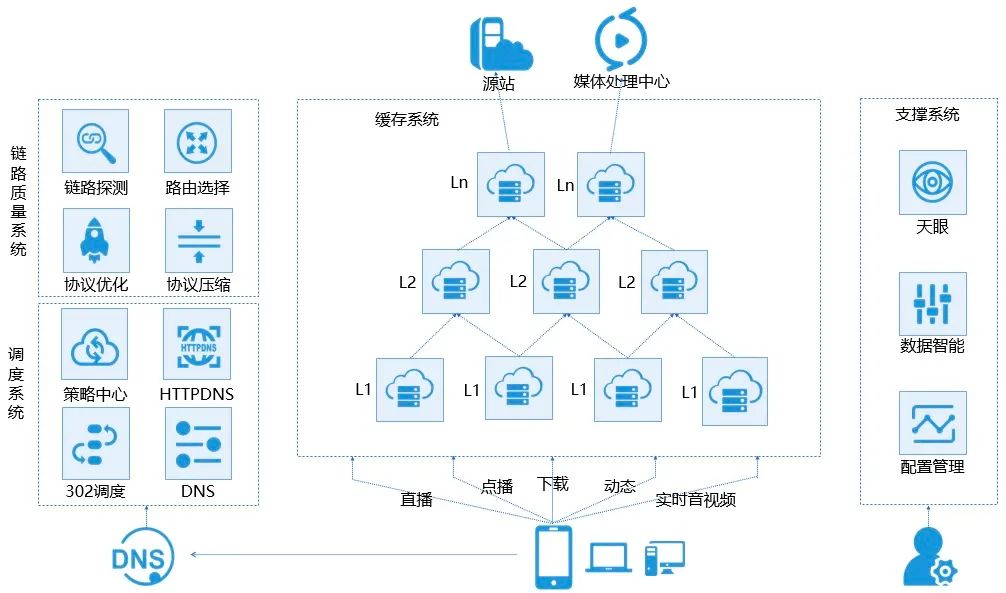
主要特点:
本地Cache加速 镜像服务 远程加速 带宽优化 集群抗攻击
应用场景
网站站点/应用加速 视音频点播/大文件下载分发加速 视频直播加速 移动应用加速
七、其他
作为补充,像分布式文件系统、大数据、NoSQL、NewSQL,慢慢也开始成为高并发系统的周围框架生态补充。
end

顶级程序员:topcoding
做最好的程序员社区:Java后端开发、Python、大数据、AI
一键三连「分享」、「点赞」和「在看」