本文由 InfoQ 整理自小年糕算法中台后端架构师封幼林在 QCon+ 大厂案例(2021 冬季北京站)的分享《高并发推荐系统架构设计》。
你好!我是封幼林,在小年糕负责推荐系统,主要从事服务架构相关工作。今天我要和你分享的话题是《高并发推荐系统架构设计》。
这次分享主要分为以下这几个部分:
推荐系统的基本架构;
旧版线上架构的并发瓶颈问题;
新版线上架构编程语言的选择;
印象深刻的 Go 踩坑经历。
我们进入第一部分,推荐系统的基本架构。第一个问题是,什么是推荐系统?以及为什么要有推荐系统?
 推荐系统
推荐系统
经过近几年互联网应用的飞速发展,我们迎来了数据爆炸时代。以时下流行的短视频应用为例,平台上有海量的视频资源。当一个用户到来时,平台需要展示他感兴趣的内容,用户的体验直接关系到平台的盈利能力。所以推荐系统本质上是一个信息过滤装置,用来在数以万计的内容中筛选出最符合用户兴趣的那一少部分。通过推荐系统,用户可以发现自己感兴趣的内容,从而提升体验;平台也可以自动发现有价值的内容,从而提高效率并带来更多收益。
 一个通用推荐系统的架构
一个通用推荐系统的架构
一个通用的推荐系统,就是以物料数据和用户行为日志为输入,经过预处理和特征工程之后得到相应的特征数据,再用一些算法模型学习特征数据中的隐含知识,最后基于学到的知识实现精准的个性化推荐。整个架构中,包含离线部分和线上部分。
推荐系统的线上架构,才是真正处理用户请求的部分。
 推荐系统 Online 架构
推荐系统 Online 架构
当一个请求到来时,首先经过 AB 分流模块,在这里,基于用户的某些特征应用哈希算法来进行分流,对分流后的用户应用不同的动态配置,主要用来支持不同策略的对比试验。AB 模块之后是多路召回,就是根据用户的特征在多个召回服务和 Redis 中并发获取数据。召回的数据经过过滤去重之后,就得到了本次推荐的粗略列表。再对这个列表应用模型排序,就得到了符合用户兴趣的个性化推荐结果。最后把结果返回给用户之前,还要根据具体业务规则,对结果进行一次重排序。关于推荐系统基本架构的介绍就到这里,后续内容都是基于推荐系统的线上架构展开的。
接下来进入第二部分,在这里,我要和你分享一个真实的并发瓶颈问题。
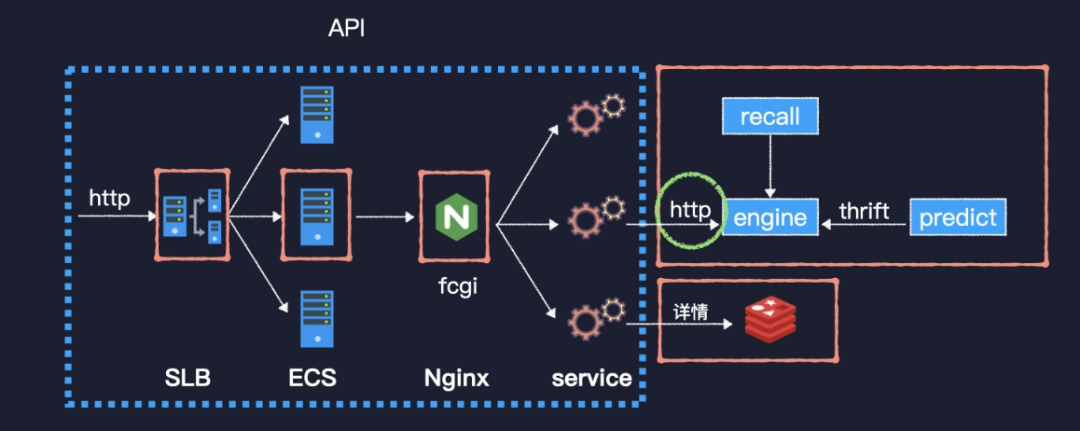 旧版推荐系统
旧版推荐系统
我们的旧版推荐系统是使用 C++ 开发的,主要包含以下几个核心服务。
接口服务 API 实现了业务侧的接口,推荐引擎 engine 实现了推荐的主要流程,recall 和 predict 分别是召回和模型预测服务。API 服务主要实现了两个接口,feed 流推荐接口和详情接口。当一个 http 请求到来时,先经过 SLB 到达一台 ECS,再经过本机部署的 Nginx,转换为 FastCGI 协议到达我们的服务程序。服务程序采用的是多进程单线程模式,类似于 php-fpm。推荐接口依赖于后续的几个服务,而详情接口比较简单,就是读取 Redis 并返回而已。要说的这个问题就出现在 API 服务上。
有一天晚高峰,接口的最大延迟突然从 300 毫秒左右飙升至 30 秒,触发了一系列报警。监控平台显示,API 两个接口的延迟曲线基本一致。API 和 engine 的 CPU 使用率都没超过 50%,但是 predict 服务却几乎跑满了 CPU。于是我们紧急将 predict 服务翻倍扩容,扩容后负载和延迟都下降至正常水平。
事后复盘发现有一个问题无法解释,那就是不依赖于后续服务的详情接口为何也会延迟飙升。带着这个问题去分析程序底层框架的源码,发现 FastCGI 模块是基于 epoll 实现的,但是用来发起 http 请求以及用来读写 Redis 的模块,都是工作在阻塞式 IO 之下的。所以在并发量很高时,进程都因等待后续服务的响应而阻塞,无法处理新的请求,这才造成详情接口延迟飙升。
沿着这个问题,我们来对比一下阻塞式 IO 与 IO 多路复用的不同。
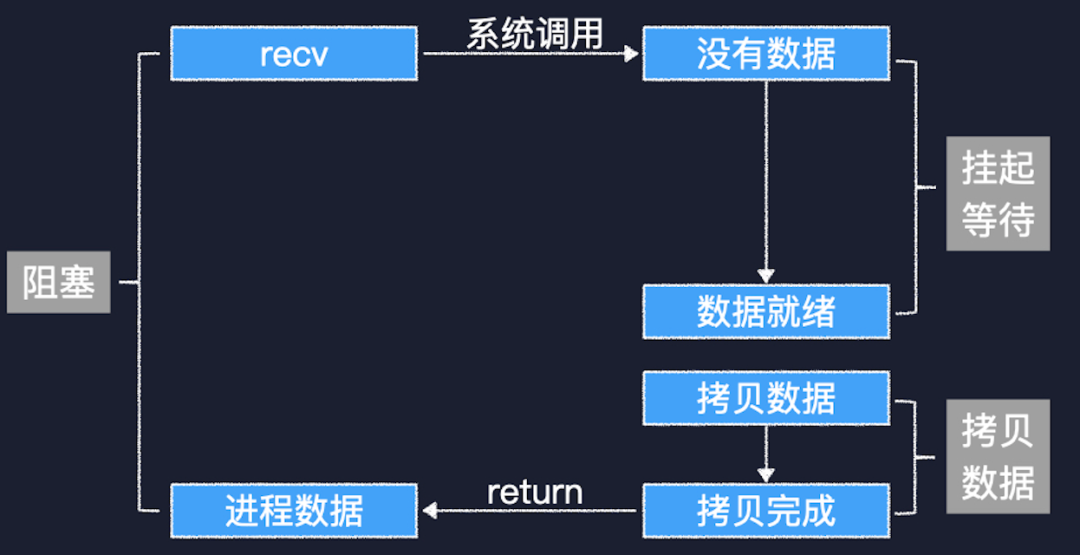 阻塞式 IO
阻塞式 IO
首先来看阻塞式 IO,线程调用 recv 来接收数据,内核这边发现 socket 接收缓冲区里没有数据,就把当前线程挂起。等到网络对端的数据发送过来,线程被唤醒向用户空间拷贝数据。

再来看 IO 多路复用,当前线程通过 epoll 监听多个 socket 上的可读、可写事件,调用 epoll_wait 时只要有一个 socket 能够满足要求,线程就不会被挂起。即使被挂起,也是只要有一个 socket 上的 IO 事件触发就能被唤醒。因为实现了多路监听,所以总是能够及时处理可读或可写的 socket。 Linux 平台的 IO 多路复用:epollLinux 系统上的 IO 多路复用技术就是 epoll,我们调用 epoll_create1 来创建一个 epoll 实例,这其实会在内核中创建一个 eventpoll 对象。eventpoll 中有一颗红黑树,用来管理所有监听的文件描述符,还有一个就绪队列,里面是 IO 事件已经触发的文件描述符。调用 epoll_ctl 把一个 socket 描述符添加到 epoll 中的时候,就会在红黑树中添加一个新的节点,同时还会在网络 IO 模块的 socket 对象那里设置一个回调。当这个 socket 对象上的 IO 事件触发时,就会调用这个回调,从而把对应的文件描述符添加到就绪队列中。线程调用 epoll_wait 的时候,只需要关心这个就绪队列就可以了,所以效率很高。前面只是理论层面的分析,我们再来通过实际的应用场景对比一下两者的不同
Linux 平台的 IO 多路复用:epollLinux 系统上的 IO 多路复用技术就是 epoll,我们调用 epoll_create1 来创建一个 epoll 实例,这其实会在内核中创建一个 eventpoll 对象。eventpoll 中有一颗红黑树,用来管理所有监听的文件描述符,还有一个就绪队列,里面是 IO 事件已经触发的文件描述符。调用 epoll_ctl 把一个 socket 描述符添加到 epoll 中的时候,就会在红黑树中添加一个新的节点,同时还会在网络 IO 模块的 socket 对象那里设置一个回调。当这个 socket 对象上的 IO 事件触发时,就会调用这个回调,从而把对应的文件描述符添加到就绪队列中。线程调用 epoll_wait 的时候,只需要关心这个就绪队列就可以了,所以效率很高。前面只是理论层面的分析,我们再来通过实际的应用场景对比一下两者的不同 基于阻塞式 IO 的 HTTP 请求读取过程一个 http 请求可以分为请求行、请求头和请求体三个部分。在这个例子中,第一行就是请求行。然后是请求头,以一个空行结束。最后是请求体。基于阻塞式 IO 来读取一个 http 请求时,只要循环地调用 recv 就可以了。检测到第一个\r\n 时,就表明接收到了完整的请求行。检测到两个连续的\r\n 时,就说明完成了请求头的接收。对于一个比较短的请求,请求头中一般会有 Content-Length,通过它,我们就可以知道需要接收多长的请求体。整个过程中,当前线程大部分时间应该都在挂起等待。
基于阻塞式 IO 的 HTTP 请求读取过程一个 http 请求可以分为请求行、请求头和请求体三个部分。在这个例子中,第一行就是请求行。然后是请求头,以一个空行结束。最后是请求体。基于阻塞式 IO 来读取一个 http 请求时,只要循环地调用 recv 就可以了。检测到第一个\r\n 时,就表明接收到了完整的请求行。检测到两个连续的\r\n 时,就说明完成了请求头的接收。对于一个比较短的请求,请求头中一般会有 Content-Length,通过它,我们就可以知道需要接收多长的请求体。整个过程中,当前线程大部分时间应该都在挂起等待。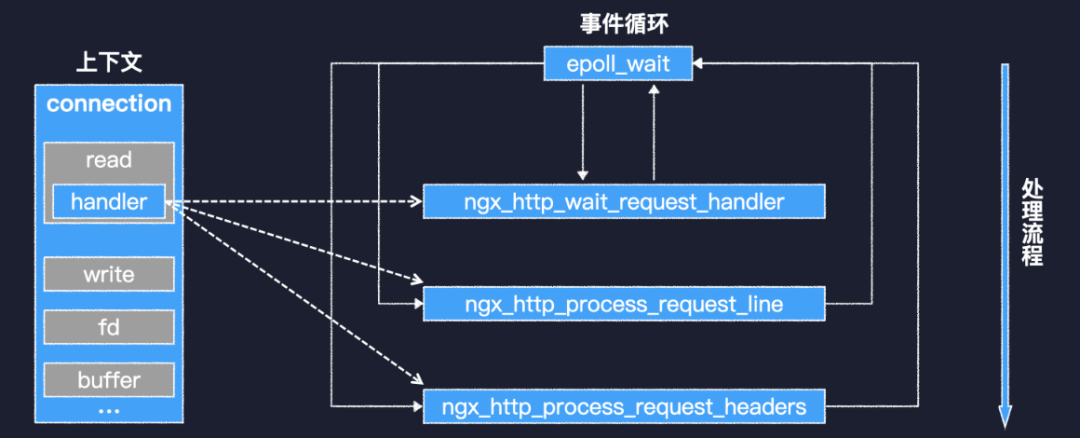 基于 IO 多路复用的 HTTP 请求读取,以 Nginx 为例再来看看基于 IO 多路复用的场景,以 Nginx 为例。因为是基于事件循环,所以 Nginx 实现了一系列的回调函数,并且用 connection 对象来存储每个连接的上下文。其中 read 对象的 handler 字段,就是现阶段处理可读事件的回调函数。http 连接建立之初,handler 指向 wait request 函数,该函数会等到客户端有数据发送过来,才实际分配需要的资源,并把 handler 指向 process request line 函数。后者会在接收到完整的请求行之后,把 handler 指向 process request headers 函数。就像这样,整个处理流程被分成了多个阶段,由一系列回调函数来完成。这样虽然性能很好,但确实不易于编程。所以除了 Nginx、Redis 这些基础软件之外,很少见到基于事件循环开发的业务系统。所以,要想基于 IO 多路复用来重构我们的推荐系统,是十分困难的。
基于 IO 多路复用的 HTTP 请求读取,以 Nginx 为例再来看看基于 IO 多路复用的场景,以 Nginx 为例。因为是基于事件循环,所以 Nginx 实现了一系列的回调函数,并且用 connection 对象来存储每个连接的上下文。其中 read 对象的 handler 字段,就是现阶段处理可读事件的回调函数。http 连接建立之初,handler 指向 wait request 函数,该函数会等到客户端有数据发送过来,才实际分配需要的资源,并把 handler 指向 process request line 函数。后者会在接收到完整的请求行之后,把 handler 指向 process request headers 函数。就像这样,整个处理流程被分成了多个阶段,由一系列回调函数来完成。这样虽然性能很好,但确实不易于编程。所以除了 Nginx、Redis 这些基础软件之外,很少见到基于事件循环开发的业务系统。所以,要想基于 IO 多路复用来重构我们的推荐系统,是十分困难的。
接下来就进入了第三部分,继续前面的话题,我们要重构推荐系统,希望有一种语言或框架,能够兼得阻塞式 IO 的简单易用和 IO 多路复用的高并发、高性能。这就是下面这个 IO 事件驱动的协程调度模型。 IO 事件驱动的协程调度来看这张图,我们为每个请求分配一个栈,也就成为了一个协程。当这个协程要等待网络 IO 时,我们把对应的 socket 描述符添加到 epoll 中,然后切换到下一个可运行的协程,后续的协程也是这样。等到没有可运行的协程时,再调用 epoll_wait,得到一组已经就绪的文件描述符。再找到每个描述符所关联的栈,就可以进行新一轮的调度。事件循环被封装在底层,每个协程中可以像阻塞式 IO 那样平铺直叙的写代码。但是这个模型还是很简陋,没有考虑 CPU 密集型应用,以及多核 CPU 上的扩展性等问题。而这些问题,通过 Go 语言的 GMP 调度模型都能够很好的解决。
IO 事件驱动的协程调度来看这张图,我们为每个请求分配一个栈,也就成为了一个协程。当这个协程要等待网络 IO 时,我们把对应的 socket 描述符添加到 epoll 中,然后切换到下一个可运行的协程,后续的协程也是这样。等到没有可运行的协程时,再调用 epoll_wait,得到一组已经就绪的文件描述符。再找到每个描述符所关联的栈,就可以进行新一轮的调度。事件循环被封装在底层,每个协程中可以像阻塞式 IO 那样平铺直叙的写代码。但是这个模型还是很简陋,没有考虑 CPU 密集型应用,以及多核 CPU 上的扩展性等问题。而这些问题,通过 Go 语言的 GMP 调度模型都能够很好的解决。 Go 语言的 GMP 调度模型在 GMP 中,G 就是协程,M 是工作线程,而 P 是个虚拟的处理器,持有一组资源。M 必须要关联一个 P 才能执行 Go 代码,系统中 P 的数量默认等于 CPU 核数,所以有很好的扩展性。每个 P 有自己的就绪队列,避免了频繁争用全局锁。在 M执行系统调用的时候,其关联的 P 可以被其他 M 抢占,保证了资源的利用率。多个 P 之间可以通过全局队列均衡任务,或者直接进行任务窃取,调度器还实现了基于时间片的抢占式调度,保证了调度的公平性。那么 IO 多路复用技术是如何与调度系统结合起来的呢?那就要看 Go 语言的 netpoller 模块。
Go 语言的 GMP 调度模型在 GMP 中,G 就是协程,M 是工作线程,而 P 是个虚拟的处理器,持有一组资源。M 必须要关联一个 P 才能执行 Go 代码,系统中 P 的数量默认等于 CPU 核数,所以有很好的扩展性。每个 P 有自己的就绪队列,避免了频繁争用全局锁。在 M执行系统调用的时候,其关联的 P 可以被其他 M 抢占,保证了资源的利用率。多个 P 之间可以通过全局队列均衡任务,或者直接进行任务窃取,调度器还实现了基于时间片的抢占式调度,保证了调度的公平性。那么 IO 多路复用技术是如何与调度系统结合起来的呢?那就要看 Go 语言的 netpoller 模块。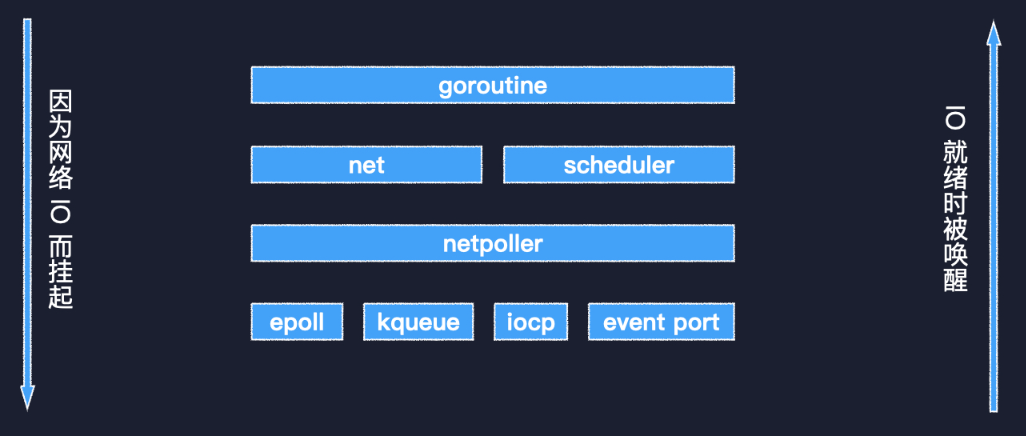 Go 语言 IO 多路复用模块netpoller 封装了具体平台相关的技术细节,Linux 的 epoll,BSD 的 kqueue,Windows 的 IO Completion Port,以及 Solaris 的 Event Port 等。在 netpoller 之上是标准库的 net 包和调度器。最上层的 goroutine 可能会因为调用 net 包中的相关函数执行网络 IO 而挂起,等到 IO 就绪后,被 netpoller 唤醒,进而得到调度执行。一个 goroutine 是如何因为网络 IO 而被挂起的呢?
Go 语言 IO 多路复用模块netpoller 封装了具体平台相关的技术细节,Linux 的 epoll,BSD 的 kqueue,Windows 的 IO Completion Port,以及 Solaris 的 Event Port 等。在 netpoller 之上是标准库的 net 包和调度器。最上层的 goroutine 可能会因为调用 net 包中的相关函数执行网络 IO 而挂起,等到 IO 就绪后,被 netpoller 唤醒,进而得到调度执行。一个 goroutine 是如何因为网络 IO 而被挂起的呢?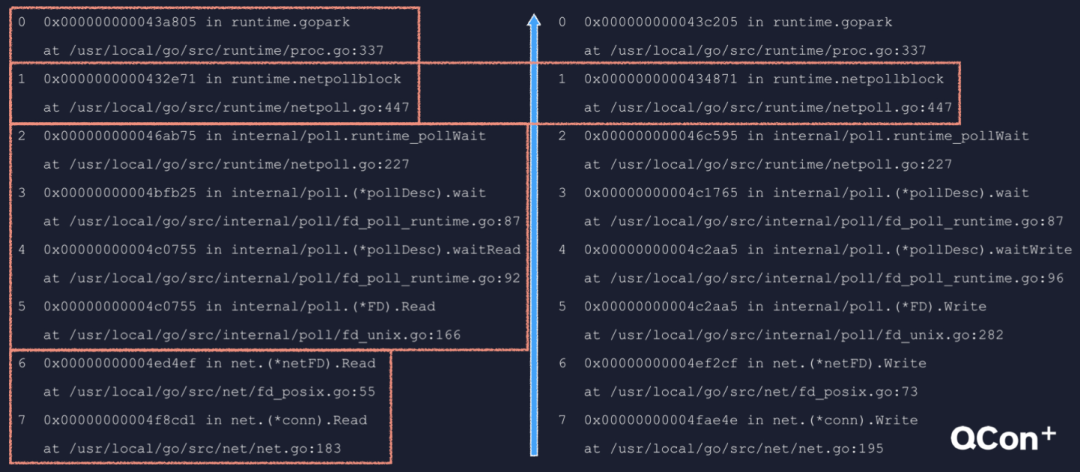 一个 goroutine 是如何因为网络 IO 被挂起的这里给出了两个调用栈,左边是因为调用网络连接的 Read 方法而被挂起,右边是因为调用 Write 方法而被挂起。可以根据不同的包把调用栈分为三个部分,net 包、internal/poll 包,最后是 runtime 包。两个调用栈的层级完全一致,最终都是由 netpollblock 函数调用 gopark 挂起了当前 goroutine。我们就来看一下这个 netpollblock 的逻辑。
一个 goroutine 是如何因为网络 IO 被挂起的这里给出了两个调用栈,左边是因为调用网络连接的 Read 方法而被挂起,右边是因为调用 Write 方法而被挂起。可以根据不同的包把调用栈分为三个部分,net 包、internal/poll 包,最后是 runtime 包。两个调用栈的层级完全一致,最终都是由 netpollblock 函数调用 gopark 挂起了当前 goroutine。我们就来看一下这个 netpollblock 的逻辑。 netpollblock 的逻辑第一个参数是个 pollDesc 类型的指针,这是 pollDesc 的结构定义。其中 fd 就是 socket 文件描述符,rg 是指向等待读事件的 goroutine 的指针。它有 4 种取值,0 表示没有协程在等待,IO 也没有就绪。pdReady 表示 IO 已经就绪,pdWait 表示有个协程即将在这里挂起等待,最后一种取值是一个 goroutine 的地址,指向在这里等待的 goroutine。wg 与 rg 类似,只不过针对的是写事件我们来看函数代码,mode 参数可能为 r 或 w,gpp 相应的指向 rg 或 wg。如果 old 为 pdReady,那就是 IO 已经就绪了,把它改成 0 也就是消费掉这个就绪状态,然后返回 true。如果 old 不为 pdReady,那就只应该是 0,否则那就是多个协程等待同一个 fd 的同一种事件,属于严重错误。internal/poll 包中 FD 类型的相关方法,内部通过锁来避免这种问题。接下来的 CAS 操作,把状态置为 pdWait,然后 gopark 挂起当前协程,netpollblockcommit 在挂起后会把 pdWait 改成 goroutine 的地址。最后,协程被唤醒后会来到这里,如果 old 等于 pdReady,说明是因为 IO 就绪而被唤醒,否则就应该是等待超时。总结一下,netpollblock 会被发起网络 IO 的协程调用,在 IO 已就绪的情况下不会挂起协程,若未就绪就挂起协程并把指针设置到 rg 或 wg 字段中。
netpollblock 的逻辑第一个参数是个 pollDesc 类型的指针,这是 pollDesc 的结构定义。其中 fd 就是 socket 文件描述符,rg 是指向等待读事件的 goroutine 的指针。它有 4 种取值,0 表示没有协程在等待,IO 也没有就绪。pdReady 表示 IO 已经就绪,pdWait 表示有个协程即将在这里挂起等待,最后一种取值是一个 goroutine 的地址,指向在这里等待的 goroutine。wg 与 rg 类似,只不过针对的是写事件我们来看函数代码,mode 参数可能为 r 或 w,gpp 相应的指向 rg 或 wg。如果 old 为 pdReady,那就是 IO 已经就绪了,把它改成 0 也就是消费掉这个就绪状态,然后返回 true。如果 old 不为 pdReady,那就只应该是 0,否则那就是多个协程等待同一个 fd 的同一种事件,属于严重错误。internal/poll 包中 FD 类型的相关方法,内部通过锁来避免这种问题。接下来的 CAS 操作,把状态置为 pdWait,然后 gopark 挂起当前协程,netpollblockcommit 在挂起后会把 pdWait 改成 goroutine 的地址。最后,协程被唤醒后会来到这里,如果 old 等于 pdReady,说明是因为 IO 就绪而被唤醒,否则就应该是等待超时。总结一下,netpollblock 会被发起网络 IO 的协程调用,在 IO 已就绪的情况下不会挂起协程,若未就绪就挂起协程并把指针设置到 rg 或 wg 字段中。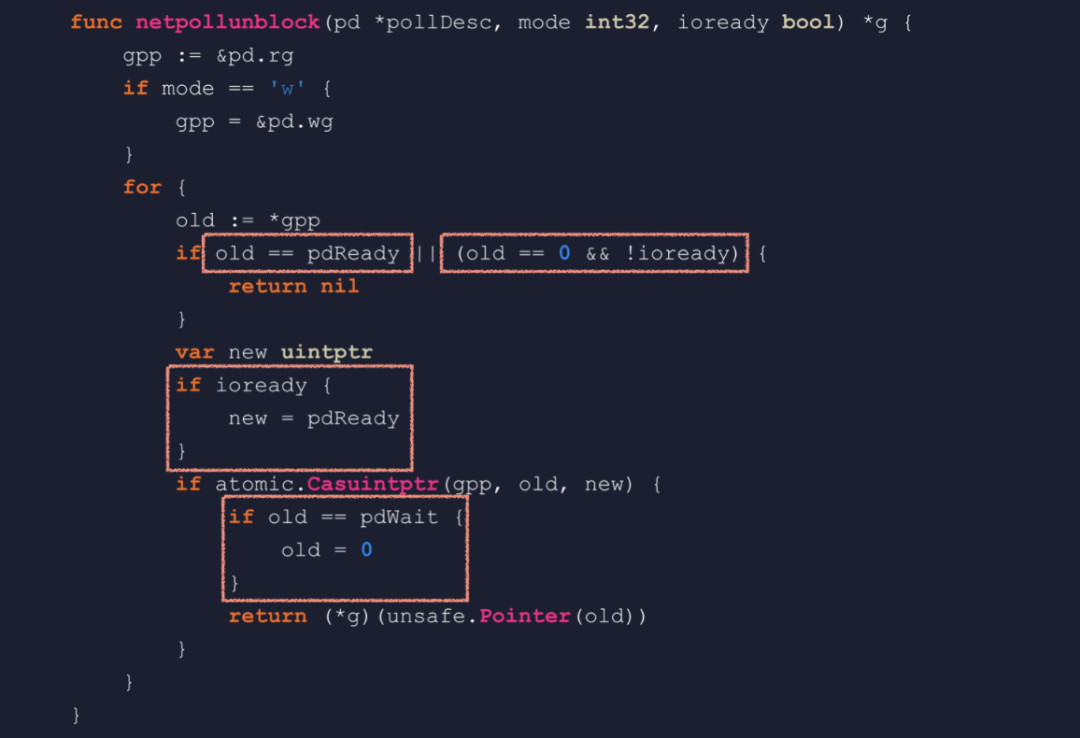 netpollunblock 函数当 IO 就绪时,netpoller 需要唤醒等待的协程,这就需要用到 netpollunblock 函数。这个函数会从 pollDesc 中取出等待 IO 的协程,并且根据触发的 IO 事件来更新 rg 或 wg。如果 old 等于 pdReady,那就说明没有协程在等待,并且已经记录了 IO 就绪状态,不需要更新,直接返回。old 等于 0 也是没有协程在等待,ioready 为 false 说明 IO 事件未触发,不需要更新状态,直接返回。ioready 为 true 的话,就要把记录的状态改成 pdReady。来到这里时,old 可能为 0、pdWait 或一个有效的 g 指针,pdWait 不是一个合法的指针,所以返回之前需要置为 0,也就是 nil。总结一下,netpolllunblock 用来提取等待 IO 事件的协程的地址,并把已触发的 IO 事件记录到 rg 或 wg 中。
netpollunblock 函数当 IO 就绪时,netpoller 需要唤醒等待的协程,这就需要用到 netpollunblock 函数。这个函数会从 pollDesc 中取出等待 IO 的协程,并且根据触发的 IO 事件来更新 rg 或 wg。如果 old 等于 pdReady,那就说明没有协程在等待,并且已经记录了 IO 就绪状态,不需要更新,直接返回。old 等于 0 也是没有协程在等待,ioready 为 false 说明 IO 事件未触发,不需要更新状态,直接返回。ioready 为 true 的话,就要把记录的状态改成 pdReady。来到这里时,old 可能为 0、pdWait 或一个有效的 g 指针,pdWait 不是一个合法的指针,所以返回之前需要置为 0,也就是 nil。总结一下,netpolllunblock 用来提取等待 IO 事件的协程的地址,并把已触发的 IO 事件记录到 rg 或 wg 中。 netpoll在调度循环的 findrunnable 函数,GC 关键点 pollWork 和 startTheWorldWithSema,以及监控线程 sysmon 中,都会调用 netpoll。netpoll 会返回一个包含 IO 就绪协程的列表,然后这个列表会被 injectglist 函数添加到全局队列中,保证了 IO 就绪的协程能够及时得到调度。
netpoll在调度循环的 findrunnable 函数,GC 关键点 pollWork 和 startTheWorldWithSema,以及监控线程 sysmon 中,都会调用 netpoll。netpoll 会返回一个包含 IO 就绪协程的列表,然后这个列表会被 injectglist 函数添加到全局队列中,保证了 IO 就绪的协程能够及时得到调度。 新版推荐系统线上架构部署架构这是我们重构后新版系统的部署架构,伴随了一些基础设施升级,服务间的依赖关系并没有太大改变。但是因为基于 Go 语言的关系,服务的并发处理能力大大提升。接下来进入最后一部分,和你分享一个印象深刻的踩坑经历。我给起的名字呢,叫做一次线上 Redis 幻读问题分析。这个幻读是加了引号的,Redis 本身是不会幻读的,出现问题是因为踩了 Go 的坑。一个后端服务中连接多个 Redis 是很常见的,我们的推荐服务也不例外。
新版推荐系统线上架构部署架构这是我们重构后新版系统的部署架构,伴随了一些基础设施升级,服务间的依赖关系并没有太大改变。但是因为基于 Go 语言的关系,服务的并发处理能力大大提升。接下来进入最后一部分,和你分享一个印象深刻的踩坑经历。我给起的名字呢,叫做一次线上 Redis 幻读问题分析。这个幻读是加了引号的,Redis 本身是不会幻读的,出现问题是因为踩了 Go 的坑。一个后端服务中连接多个 Redis 是很常见的,我们的推荐服务也不例外。 一个后端服务中连接多个 Redis新版推荐系统上线后,效果却出乎意料的不太理想。经过全面的排查,发现从 Redis 中读取特征数据时,时而能读到时而读不到,但是却不是网络通信错误造成的。从命令行查看,Redis 中的数据是一直存在的,这让我们大惑不解。最后不得已在一台机上抓包,通过分析网络包,发现程序竟然连接了错误的 Redis。也就是本来数据在 1 号 Redis 中,程序却跑到 3 号 Redis 去读。这个发现真的令人非常震惊,我们立即重新 review 了一次代码。
一个后端服务中连接多个 Redis新版推荐系统上线后,效果却出乎意料的不太理想。经过全面的排查,发现从 Redis 中读取特征数据时,时而能读到时而读不到,但是却不是网络通信错误造成的。从命令行查看,Redis 中的数据是一直存在的,这让我们大惑不解。最后不得已在一台机上抓包,通过分析网络包,发现程序竟然连接了错误的 Redis。也就是本来数据在 1 号 Redis 中,程序却跑到 3 号 Redis 去读。这个发现真的令人非常震惊,我们立即重新 review 了一次代码。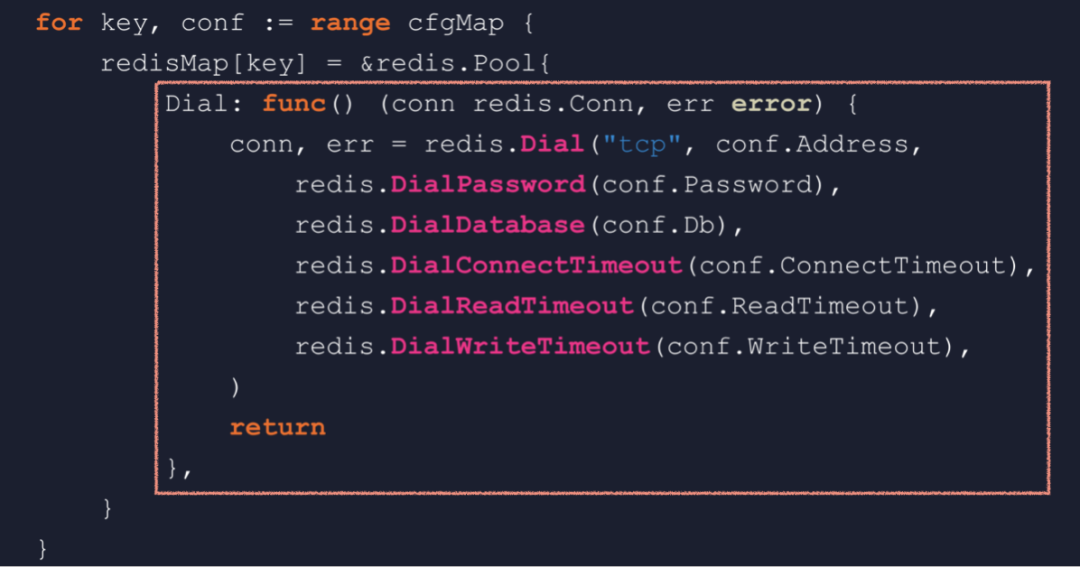 看似正常实则有问题的 Redis 连接池初始化代码于是就发现了这样一段看似正常,实则很有问题的代码。这段代码在程序初始化阶段负责初始化 Redis 连接池,它会遍历一个包含所有 Redis 配置的 map,然后逐个创建连接池,并且存放到另一个 map 中。如果已经有了一定的 Go 应用经验,你可能一眼就会发现这里的循环套闭包问题。有很多人被这个问题给坑过,然而这底层到底是什么原理呢?要弄清这个问题,我们先要弄清楚闭包的庐山真面目。所谓闭包,通俗来讲就是内层函数使用了外层函数局部作用域中的变量,这段代码就会返回一个闭包。我们通常会有个疑问,就是外层函数返回之后,栈帧也随即释放,变量 n 也就销毁了。那么,内层函数如何能够合法的访问变量 n 呢?
看似正常实则有问题的 Redis 连接池初始化代码于是就发现了这样一段看似正常,实则很有问题的代码。这段代码在程序初始化阶段负责初始化 Redis 连接池,它会遍历一个包含所有 Redis 配置的 map,然后逐个创建连接池,并且存放到另一个 map 中。如果已经有了一定的 Go 应用经验,你可能一眼就会发现这里的循环套闭包问题。有很多人被这个问题给坑过,然而这底层到底是什么原理呢?要弄清这个问题,我们先要弄清楚闭包的庐山真面目。所谓闭包,通俗来讲就是内层函数使用了外层函数局部作用域中的变量,这段代码就会返回一个闭包。我们通常会有个疑问,就是外层函数返回之后,栈帧也随即释放,变量 n 也就销毁了。那么,内层函数如何能够合法的访问变量 n 呢? 闭包的庐山真面目——闭包对象我们通过反编译来看看到底是怎么回事,看到 runtime.newobject 函数,这就说明在堆上分配了一个对象。再根据后面几条指令,可以推导出这个对象的结构。第一个字段 F,就是内层函数的地址;第二个字段 n,其实是变量 n 的副本。外层函数最终返回的,是这个对象的地址,我们就称它为闭包对象。runtime 中的 funcval 结构描述了一个闭包对象的结构,第一个字段永远是函数地址,后面是捕获列表,闭包会捕获它用到的变量。那么,内层函数如何得知被捕获变量的地址呢?我们再反编译一下内层函数,返现编译器会使用 DX 寄存器传递闭包对象地址,类似于 C++ 的 thiscall。好了,我们现在对闭包的原理有了最基本的了解。
闭包的庐山真面目——闭包对象我们通过反编译来看看到底是怎么回事,看到 runtime.newobject 函数,这就说明在堆上分配了一个对象。再根据后面几条指令,可以推导出这个对象的结构。第一个字段 F,就是内层函数的地址;第二个字段 n,其实是变量 n 的副本。外层函数最终返回的,是这个对象的地址,我们就称它为闭包对象。runtime 中的 funcval 结构描述了一个闭包对象的结构,第一个字段永远是函数地址,后面是捕获列表,闭包会捕获它用到的变量。那么,内层函数如何得知被捕获变量的地址呢?我们再反编译一下内层函数,返现编译器会使用 DX 寄存器传递闭包对象地址,类似于 C++ 的 thiscall。好了,我们现在对闭包的原理有了最基本的了解。 何时捕获值,何时捕获地址还是这段代码,我们已经知道它的闭包对象是这样的,捕获了 n 的值。我们把这段代码稍作改动,返回之前修改一下变量 n,相应的闭包对象就变成了这个样子,捕获了 n 的地址。所以我们简单地得出结论,变量无改动,捕获值,变量有改动,捕获地址。这个改动不仅限于内层函数中,前面的循环套闭包问题,就是因为外层循环不断改变循环变量的值,造成闭包捕获地址。从语义角度来讲,闭包本应该总是捕获变量地址,但是这样会造成更多的变量逃逸。所以,作为一种优化,编译器在逻辑允许的条件下,改为捕获值。最后,再跟你介绍一种方法,可以直接看到闭包对象的结构。
何时捕获值,何时捕获地址还是这段代码,我们已经知道它的闭包对象是这样的,捕获了 n 的值。我们把这段代码稍作改动,返回之前修改一下变量 n,相应的闭包对象就变成了这个样子,捕获了 n 的地址。所以我们简单地得出结论,变量无改动,捕获值,变量有改动,捕获地址。这个改动不仅限于内层函数中,前面的循环套闭包问题,就是因为外层循环不断改变循环变量的值,造成闭包捕获地址。从语义角度来讲,闭包本应该总是捕获变量地址,但是这样会造成更多的变量逃逸。所以,作为一种优化,编译器在逻辑允许的条件下,改为捕获值。最后,再跟你介绍一种方法,可以直接看到闭包对象的结构。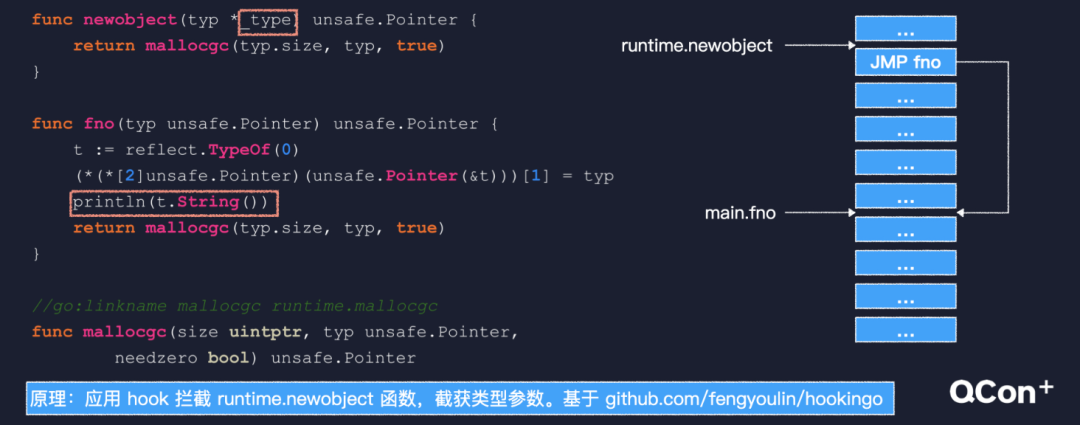 将闭包逮个正着我们已经知道,在堆上分配闭包对象会调用 newobject 函数,该函数有个 type 参数,这个 type 类型在 Go 语言的类型系统中用来描述一种数据类型,是反射得以实现的基础。我们 hook 技术拦截 newobject 函数,就可以获得这个参数。Hook 技术,就是运行阶段修改函数代码,把入口处替换为一条无条件跳转指令,跳转到一个我们给出的函数。在该函数里用反射,就可以打印出闭包对象的结构。1.多路复用技术是实现高性能网络 IO 的基础,但是事件循环不易于编程;2.Go 基于协程和 netpoller 把事件循环封装在 runtime内部,编码方式对开发者友好;3.GMP 调度模型在多核 CPU 上有很好的扩展性,能充分发挥系统的计算能力;4.闭包的捕获列表会尽量捕获值,只有变量会被修改时捕获地址。最后,如果我再做一遍这个项目,我可能会从两个角度上再优化一下:1.要落实系统、全面的测试。尤其在进行重构的时候,我们遇到过的很多问题,都是因为测试不完善,或者测试环境不能模拟真实环境所致。很多本来是可以避免的,所以落实系统、全面的测试真的很有必要。2.避免过度设计。我们从一入行就被告知,写的程序要灵活易于扩展。长此以往之后,很多人实际上会做过度设计。反思我自己也有这种问题,代码中的各种设计模式,还有服务模块的拆分等等。不仅造成了较高的维护成本,还会在一定程度上影响性能。所以一定要结合实际需求进行设计。
将闭包逮个正着我们已经知道,在堆上分配闭包对象会调用 newobject 函数,该函数有个 type 参数,这个 type 类型在 Go 语言的类型系统中用来描述一种数据类型,是反射得以实现的基础。我们 hook 技术拦截 newobject 函数,就可以获得这个参数。Hook 技术,就是运行阶段修改函数代码,把入口处替换为一条无条件跳转指令,跳转到一个我们给出的函数。在该函数里用反射,就可以打印出闭包对象的结构。1.多路复用技术是实现高性能网络 IO 的基础,但是事件循环不易于编程;2.Go 基于协程和 netpoller 把事件循环封装在 runtime内部,编码方式对开发者友好;3.GMP 调度模型在多核 CPU 上有很好的扩展性,能充分发挥系统的计算能力;4.闭包的捕获列表会尽量捕获值,只有变量会被修改时捕获地址。最后,如果我再做一遍这个项目,我可能会从两个角度上再优化一下:1.要落实系统、全面的测试。尤其在进行重构的时候,我们遇到过的很多问题,都是因为测试不完善,或者测试环境不能模拟真实环境所致。很多本来是可以避免的,所以落实系统、全面的测试真的很有必要。2.避免过度设计。我们从一入行就被告知,写的程序要灵活易于扩展。长此以往之后,很多人实际上会做过度设计。反思我自己也有这种问题,代码中的各种设计模式,还有服务模块的拆分等等。不仅造成了较高的维护成本,还会在一定程度上影响性能。所以一定要结合实际需求进行设计。最后送你一句话,知其所以然,磨刀不误砍柴工。
推荐阅读:
世界的真实格局分析,地球人类社会底层运行原理
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)
企业IT技术架构规划方案
论数字化转型——转什么,如何转?
华为干部与人才发展手册(附PPT)
企业10大管理流程图,数字化转型从业者必备!
【中台实践】华为大数据中台架构分享.pdf
华为的数字化转型方法论
华为如何实施数字化转型(附PPT)
超详细280页Docker实战文档!开放下载
华为大数据解决方案(PPT)
