
CNN真的需要下采样(上采样)吗?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
在常见的卷积神经网络中,采样几乎无处不在,以前是max_pooling,现在是strided卷积。
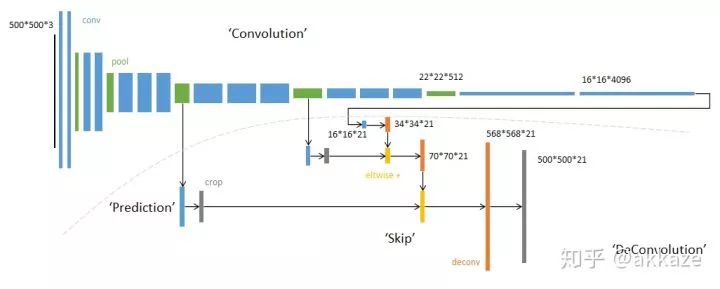
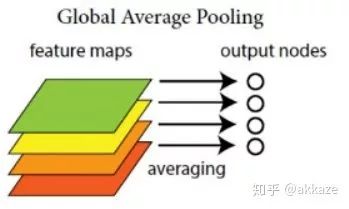
Input-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->GAP-->Conv1x1-->Softmax-->Output而分割网络的范式变为(最近的一些文章也在考虑用upsample+conv_1x1代替deconv),Input-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Deconv_x_2-->Deconv_x_2-->Deconv_x_2-->Softmax-->Output这里暂时不考虑任何shortcut。
可是,我们不得不去想,下采样,上采样真的是必须的吗?可不可能去掉呢?
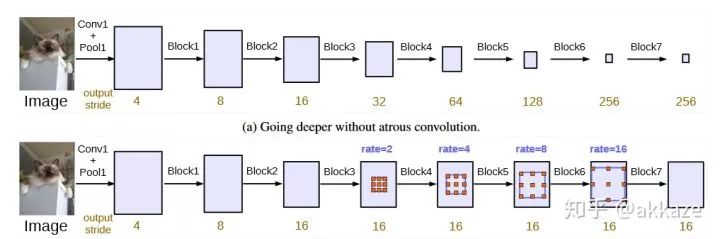
一个很自然的想法,下采样只是为了减小计算量和增大感受野,如果没有下采样,要成倍增大感受野,只有两个选择,空洞卷积和大卷积核。所以,第一步,在cifar10的分类上,我尝试去掉了下采样,将卷积改为空洞卷积,并且膨胀率分别递增,模型结构如下所示,

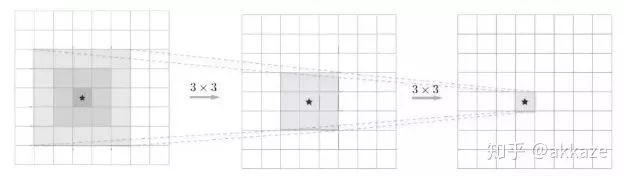
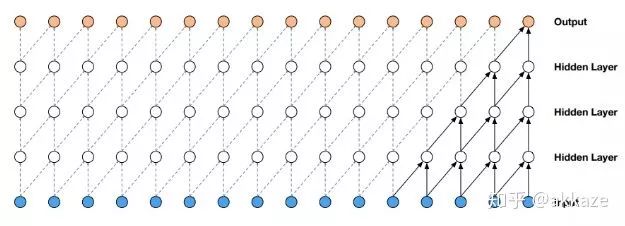
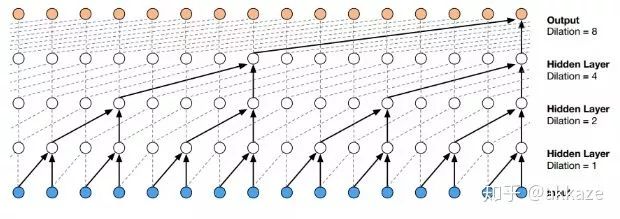
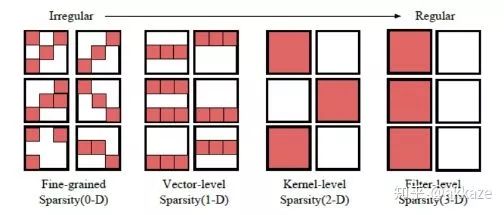
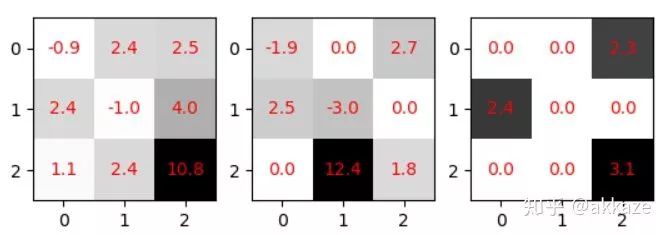
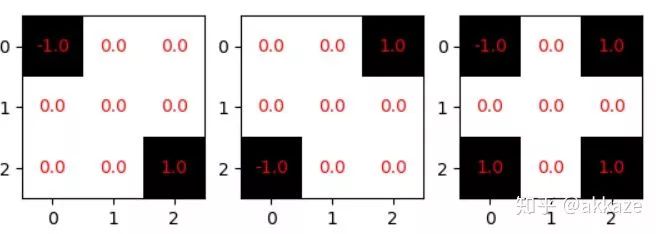


Input-->Conv(dilate_rate=1)-->Conv(dilate_rate=2)-->Conv(dilate_rate=4)-->Conv(dilate_rate=8)-->GAP-->Conv1x1-->Softmax-->Output分割网络的范式将如下所示,Input-->Conv(dilate_rate=1)-->Conv(dilate_rate=2)-->Conv(dilate_rate=4)-->Conv(dilate_rate=8)-->Conv(dilate_rate=16)-->Conv(dilate_rate=32)-->Softmax-->Output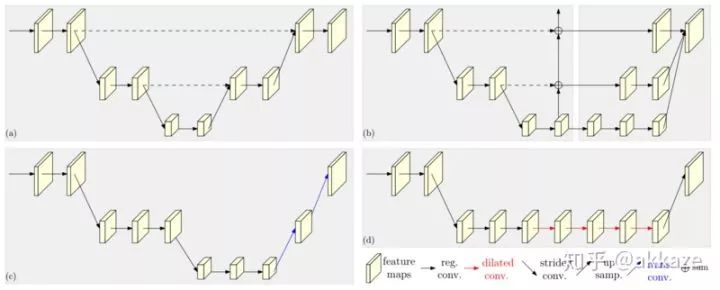
 在不同的
在不同的  下的图像,
下的图像,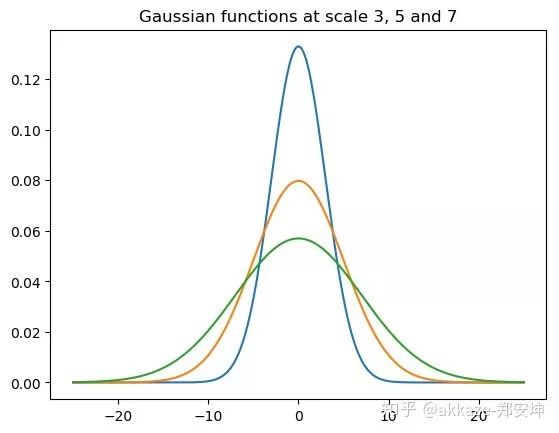





 ,cnn的目的就是找到这样一个
,cnn的目的就是找到这样一个  ,
, 在这里是非线性激活函数,
在这里是非线性激活函数,



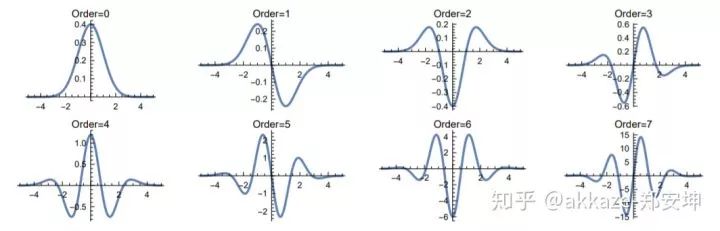



 ,请自行将
,请自行将  对应到卷积核大小上
对应到卷积核大小上交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论