
风控ML[10] | 风控建模中的自动分箱的方法有哪些

之前有位读者朋友说有空介绍一下自动分箱的方法,这个确实在我们实际建模过程前是需要解决的一个问题,简单来说就是把连续变量通过分箱的方式转换为类别变量。关于这个话题,我也借着这个主题来系统的梳理总结一下几点:为什么要分箱?不分箱可以入模型吗?自动分箱的常用方法有哪些?评估分箱效果好坏的方法有哪些? 如果篇幅允许,就顺便把实现的Python代码也分享下,如果太长了就另外起一篇文章来讲。因此,本篇文章主要从下面几个模块来展开说说。
00 Index
01 分箱是什么意思,为什么要分箱,什么时候分箱?
02 常见的自动分箱方法有哪些?
03 如何评估分箱效果的好坏
04 设计一个基于风控建模的自动分箱轮子
01 分箱是什么意思,为什么要分箱,什么时候分箱?
分箱的意思就是将连续性变量通过几个划分点,分割成几段的过程。比如说我们有一个字段「年龄」,通过分箱可以变成: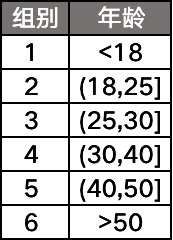
那到了这里有同学就会问了,为什么要对连续性变量进行分箱呢?直接拿来用不行吗?要回答这个问题,我们先要搞清楚分箱的好处有有哪些,主要有2点:
1)对变量进行分箱后,会对异常数据有较强的鲁棒性,变量会更加稳定;
2)变量分箱后,对于风控建模常用的LR,这种表达能力有限的线性模型,可以提升模型的表达能力,加强模型拟合能力。
嗯,讲了一些好处,还是有一个问题需要解决的,那就是:不分箱直接使用变量进入模型可以吗?
Actually,对于风控评分卡的大多数模型,是可以的,只不过有些模型,如果直接把连续变量进入模型的话,带来的模型效果会不太理想。那么,下面我将从两类我们常用的风控模型来说下:
1)LR:本身属于线性模型,表达能力有限,将变量分箱后意味着引入了更多的非线性特征,有助于提升模型拟合能力,一般情况下都进行WOE分箱之后再进入模型;
2)GBDT:作为Boosting类集成分类器模型的经典,这是一类将弱分类器提升为强分类器的算法,其中的提升树(Boosting tree)中间过程会产生大量决策树,如果输入的变量是分箱后高稀疏特征的话,一是会导致模型训练效果过低,二是会特别容易过拟合。一般都是输入连续型变量或者是非稀疏的OneHot;
3)XGBoost:它与GBDT类似,可以简单理解为XGBoost是一种基于GBDT的极度梯度提升的模型,优化了正则项和将损失函数展开到二阶,在算法精度、训练速度、泛化能力上有较大的优化。同GBDT,使用高稀疏的分箱特征入模型的话,速度还是会比较慢的。
4)CatBoost:CatBoost的主要“卖点”就是可以直接处理类别变量,也就是不需要OneHot直接入模,它也是可以直接对连续变量直接使用的;
总的来说,像LR这类的线性模型一般都是需要对连续变量分箱的,而对于GBDT、XGBoost这类的非线性模型,可以直接输入连续变量。
02 常见的自动最优分箱方法有哪些?
在介绍了分箱的好处以及应用的场景后,我们需要知道一些方法去进行分箱,最直观的自动分箱方法就是等频和等距分箱,不过这类过于简单理论的方法,往往效果并不是特别地好。所以今天介绍一下3种业界常用的自动最优分箱方法。
1)基于CART算法的连续变量最优分箱
2)基于卡方检验的连续变量最优分箱
3)基于最优KS的连续变量最优分箱
基于CART算法的连续变量最优分箱
回顾一下CART,全称为分类与回归树(Classification And Regression Tree),由于CART生成的决策树都是二叉决策树,并且该算法是基于最小基尼指数递归的方式选择最优的二值划分点,不断地把数据集划分成D1和D2两部分,依此类推直到满足停止条件。
所以连续分箱也是可以借助相同的理论来使用,其实现步骤如下:
1,给定连续变量 V,对V中的值进行排序;
2,依次计算相邻元素间中位数作为二值划分点的基尼指数;
3,选择最优(划分后基尼指数下降最大)的划分点作为本次迭代的划分点;
4,递归迭代步骤2-3,直到满足停止条件。(一般是以划分后的样本量作为停止条件,比如叶子节点的样本量>=总样本量的10%)
基于卡方检验的连续变量最优分箱
卡方检验相信很多同学会比较熟悉,它是基于卡方分布的一种假设检验的方法,主要是用于两个分类变量之间的独立性检验,其基本思想就是根据样本数据推断两个分类变量是否相互独立,其卡方值的计算公式如下:
其中,A是实际频数,E是期望频数。那么这应该怎么算呢?可以参考一下下面的例子: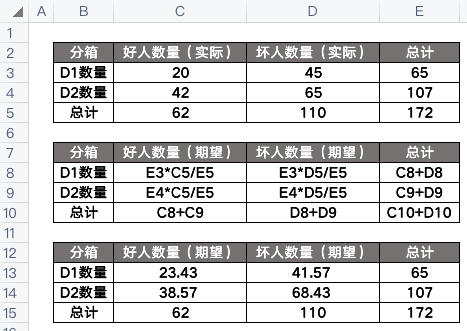
套入上面的公式,算得卡方值为1.26:
这个卡方值我们可以通过查找卡方表来确定是否拒绝原假设,这里的原假设是假设两个数据集D1和D2没有区别,也就是不需要拆分,可以合并。
import pandas as pd
import numpy as np
from scipy.stats import chi2
p = [0.995, 0.990, 0.975, 0.950, 0.900, 0.100, 0.050, 0.025, 0.010, 0.005]
df = pd.DataFrame(np.array([chi2.isf(p, df=i) for i in range(1,10)]), columns=p, index=list(range(1,10)))
df
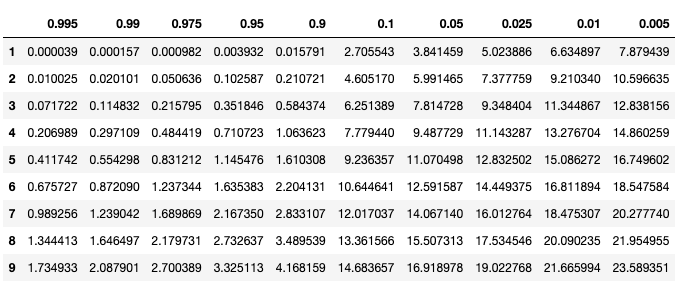
要想读懂上表,我们需要知道自由度n(纵轴)以及显著性水平p(横轴),其中:
自由度n = (行数-1)* (列数-1),上面例子中n = (2-1)* (2-1) = 1,所以我们只需要看表中第一行,而我们算出来的卡方值是1.26,也就是显著性水平p介于0.1~0.9之间,p大于0.05,我们就认为原假设成立! 也就是说两个数据集可以合并!总的来说,就是算出来的卡方值越小,就越证明这两个数据集是同一类,可以合并。
因此,卡方最优分箱的理论基础就在这儿,卡方分箱算法原名叫ChiMerge算法,分成2阶段:初始化阶段和自底向上合并阶段,主要实现步骤如下:
1,给定连续变量 V,对V中的值进行排序,然后每个元素值单独一组,完成初始化阶段;
2,对相邻的组,两两计算卡方值;
3,合并卡方值最小的两组;
4,递归迭代步骤2-3,直到满足停止条件。(一般是卡方值都高于设定的阈值,或者达到最大分组数等等)
基于最优KS的连续变量最优分箱
KS相信大家也都不陌生,可以稍微回顾下《风控建模的KS》 ,不过这里的KS值不是基于模型计算的,而是基于变量计算的,不过,计算逻辑和原理都是相通的。
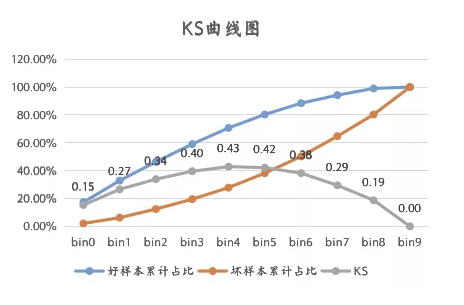 所以,我们的最优KS分箱方法实现步骤如下:
所以,我们的最优KS分箱方法实现步骤如下:
1,给定连续变量 V,对V中的值进行排序;
2,每一个元素值就是一个计算点,对应上图中的bin0~9;
3,计算出KS最大的那个元素,作为最优划分点,将变量划分成两部分D1和D2;
4,递归迭代步骤3,计算由步骤3中产生的数据集D1 D2的划分点,直到满足停止条件。(一般是分箱数量达到某个阈值,或者是KS值小于某个阈值)
我们需要知道,分箱后的连续变量,其KS值肯定是比原来的要小的,所以我们要设置好停止条件,不然分箱后的变量效果不太好了。
03 如何评估分箱效果的好坏
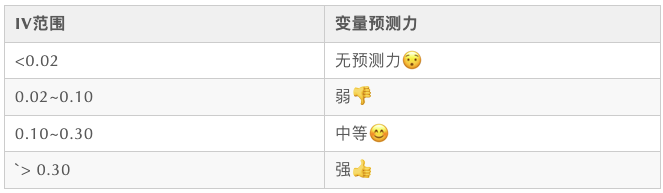
这个比较简单,就是看变量的IV值,具体可以参考之前的一篇文章。《风控建模的WOE与IV》
04 设计一个基于风控建模的自动分箱轮子
一般来说,如果要造一个基于风控建模的连续变量分箱框架,需要考虑什么内容呢?我觉得应该有下面几点是需要关注的:
1,最小的分组数量
2,badrate比例控制
3,缺失值的处理逻辑
4,分箱后IV值计算与判断(不能低于0.02)
5,分箱的数量不能太多,以免太过于稀疏。
基于上面的考虑,我将会在未来设计一个连续变量自动分箱的“轮子”,到时候把源码也放出来,欢迎大家来补充。
Reference
https://blog.csdn.net/xgxyxs/article/details/90413036
https://zhuanlan.zhihu.com/p/44943177
https://blog.csdn.net/hxcaifly/article/details/84593770
https://blog.csdn.net/haoxun12/article/details/105301414/
https://www.bilibili.com/read/cv12971807