
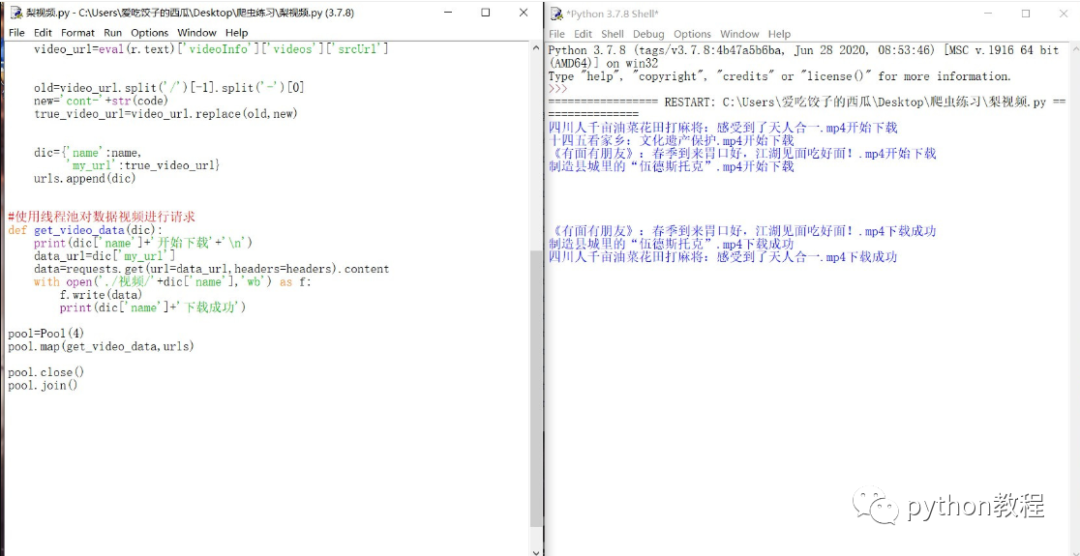
完整代码如下:
import requests
from lxml import etree
import random
import os
from multiprocessing.dummy import Pool
if not os.path.exists('./视频'):
os.mkdir('./视频')
urls=[]
url='https://www.pearvideo.com/category_5'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//ul[@id="listvideoListUl"]/li')
for li in li_list:
a_url='https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
old=video_url.split('/')[-1].split('-')[0]
new='cont-'+str(code)
true_video_url=video_url.replace(old,new)
dic={'name':name,
'my_url':true_video_url}
urls.append(dic)
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
说明:
当前日期(2021/3/14)版本的梨视频的视频伪url由ajax获取。
部分代码解释:
1:模块
import requests #网路爬虫标准库(代替urllib)
from lxml import etree #用于解析页面信息
import random #梨视频的url中有一段需要随机数
import os #主要用于生成文件夹存放视频
from multiprocessing.dummy import Pool #导入线程池对应类
2:获取视频伪url
#参数准备
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={
'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
#获取url
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
3:获取真正url
经本人实验,使用上文获得的url爬取视频下载内容为空。
此处视频地址做了加密即ajax中得到的地址需要加上cont-,并且修改一段数字为id才是真地址
真地址:"https://video.pearvideo.com/mp4/third/20201120/cont-1708144-10305425-222728-hd.mp4"
伪地址:"https://video.pearvideo.com/mp4/third/20201120/1606132035863-10305425-222728-hd.mp4"
#仅需要做几个简单的截取切片操作就可以替换相关内容
old=video_url.split('/')[-1].split('-')[0]
new='cont-'+str(code)
true_video_url=video_url.replace(old,new)
4:存储
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
5:结果
到此这篇关于python爬取梨视频生活板块最热视频的文章就介绍到这了
 扫下方二维码加老师微信
扫下方二维码加老师微信
或是搜索老师微信号:XTUOL1988【切记备注:学习Python】
邀您来听Python web开发,Python爬虫,Python数据分析,人工智能 免费精品教程,0基础入门到企业项目实战教学!
欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
万水千山总是情,点个【在看】行不行
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜
