
预备AI工程师升级必备:大厂常见图像分类面试题
图像分类是深度学习计算机视觉技术中极其重要的应用场景和技术基础,图像检测、语义分割等等各种任务场景都需要基于图像分类的基础能力。也是大家入门深度学习CV方向任务开发极好的切入点。

针对如此关键的图像分类任务,飞桨PaddleClas团队提炼、总结了在开发过程中常遇到的问题和一些巧妙的开发技巧(Trick),希望能帮助开发者更快、更好地获得最佳的模型及应用效果。这门武功秘笈分为四篇:《基础知识》、《模型训练》、《数据大法》和《模型推理预测》,本文节选了其中10个小技巧,供各位大侠使用。

基础知识篇
Precision = TP / (TP + FP) Recall = TP / (TP + FN) F-score = 2×Precision×Recall / ( Precision + Recall)
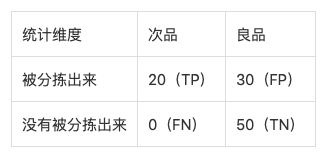
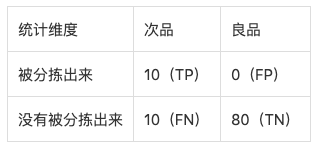

Accuary表示所有类别预测正确的图像数量占总图像数量的百分比; Class-wise Accuracy是先对每个类别的图像计算Accuracy,再对所有类别的Accuracy取平均。

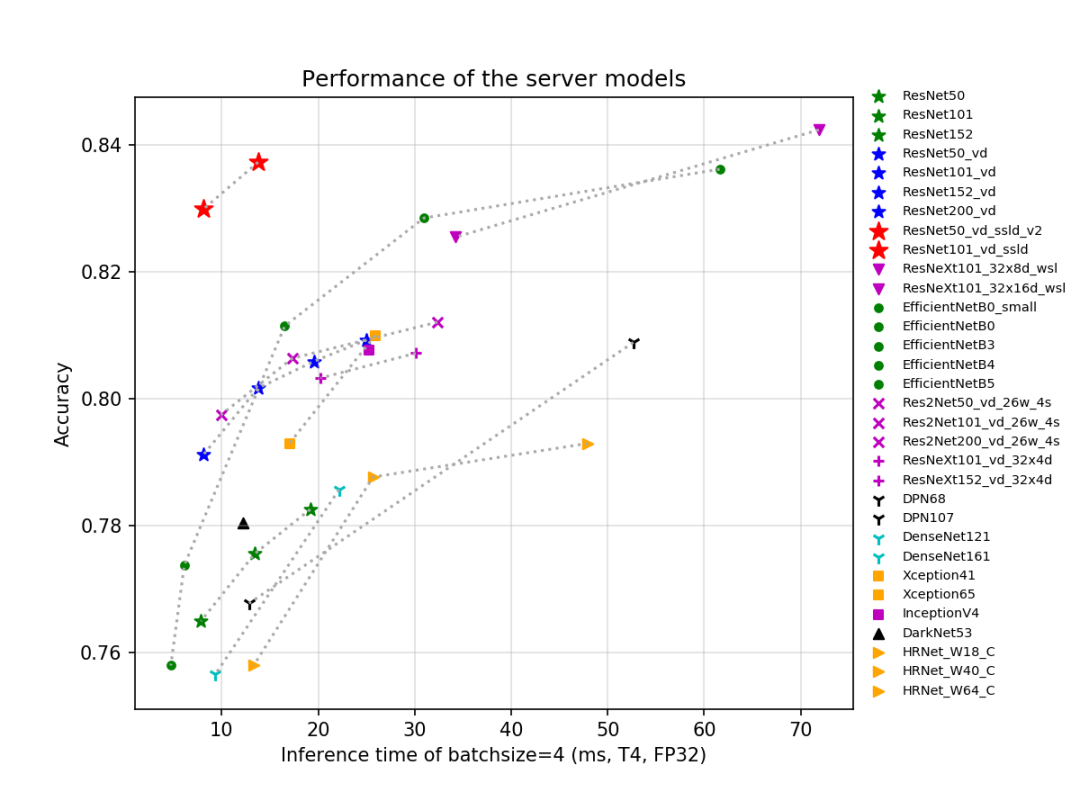
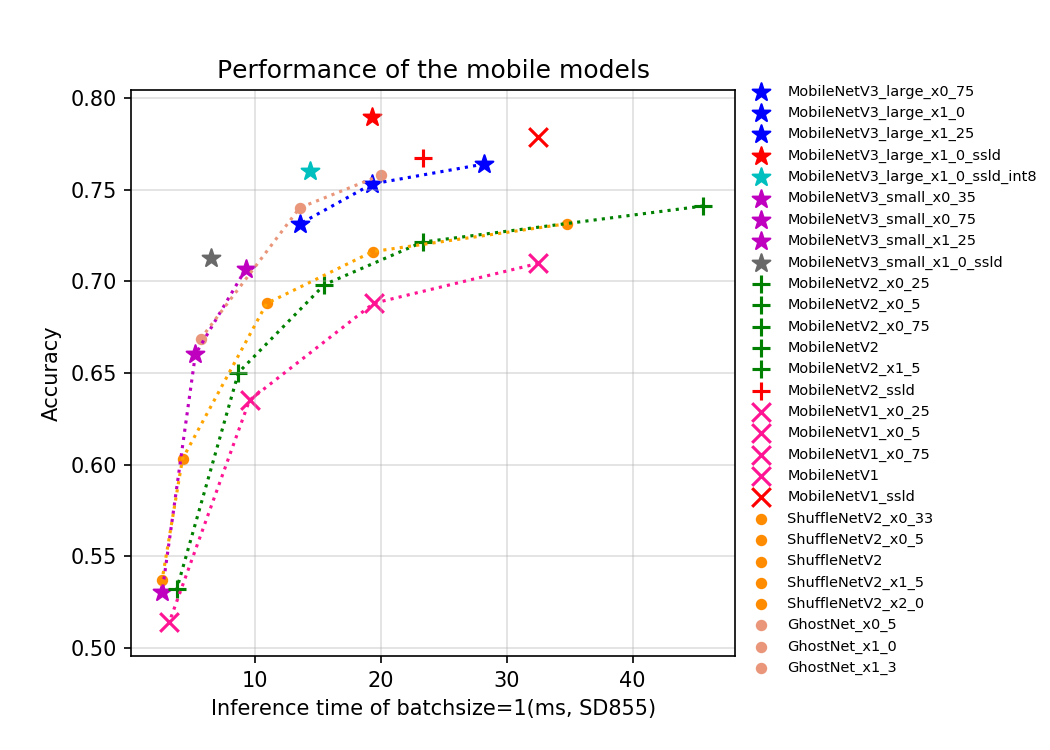
模型剪枝:将权重矩阵中相对不重要的权值剔除,然后再重新对网络进行微调;
模型量化:一种将浮点计算转成低比特定点计算的技术,如:8 bit、4 bit等,可以有效的模型在推理过程中的计算复杂度,提高推理速度,降低推理计算的能耗。
知识蒸馏:使用教师模型(teacher model)去指导学生模型(student model)学习特定任务,保证小模型在参数量不变的情况下,性能有较大的提升,甚至获得与大模型相似的精度指标。PaddleClas提供了一种简单的知识蒸馏策略(Simple Semi-supervised Label Distillation, SSLD),基于ImageNet-1k验证集,不同模型经过SSLD蒸馏均有3%以上的精度提升,更多细节可以参考SSLD知识蒸馏文档:
https://github.com/PaddlePaddle/PaddleClas/blob/master/docs/zh_CN/advanced_tutorials/distillation/distillation.md
模型训练篇
检查数据标注,确保训练集和验证集的数据标注正确; 尝试调整学习率(初期以10倍为单位进行调节),过大(训练震荡)或者过小(收敛太慢)的学习率都可能导致收敛效果差; 数据量太大,选择的模型太小,难以学习所有数据的特征; 查看数据预处理的过程中是否使用了归一化,如果没有,会影响收敛速度; 如果数据量比较小,可以尝试加载PaddleClas中提供的基于ImageNet-1k数据集的预训练模型,可以大大提升训练收敛速度; 数据集存在长尾问题,可以参考数据长尾问题解决方案。https://github.com/PaddlePaddle/PaddleClas/blob/master/docs/zh_CN/faq.md#jump
use_mix: True # 是否使用混叠类数据增广
ls_epsilon: 0.1 # label smoothing的epsilon值,该值不在(0,1)区间或者为None表示不使用label smoothing
OPTIMIZER:
function: 'Momentum'
params:
momentum: 0.9
regularizer:
function: 'L2'
factor: 0.000070 # weight_decay的值
TRAIN:
transforms:
- DecodeImage: # 读入图像并转为RGB通道
to_rgb: True
to_np: False
channel_first: False
- RandCropImage: # 随机裁剪
size: 224
scale: [0.08, 1.0] # RandomCrop的区域面积比例范围
- RandFlipImage: # 随机水平翻转
flip_code: 1
- AutoAugment: # 使用自动增广方式进行数据增广(图像变换类)
- NormalizeImage: # 对图像进行归一化
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- RandomErasing: # 使用随机擦除的方法进行数据增广(图像裁剪类)
EPSILON: 0.5
sl: 0.02
sh: 0.4
r1: 0.3
mean: [0., 0., 0.]
- ToCHWImage:
mix: # Mixup数据增广,在use_mix设置为True时有效(图像混叠类)
- MixupOperator:
alpha: 0.2 # Mixup的超参数配置
数据大法篇
图像变换类:主要包括AutoAugment和RandAugment; 图像裁剪类:主要包括CutOut、RandErasing、HideAndSeek和GridMask; 图像混叠类:主要包括Mixup和Cutmix。

如果您已经加载了PaddleClas中提供的预训练模型,每个类别包括10-20张图像即可保证基本的分类效果;
如果您没有加载预训练模型,每个类别需要至少包含100~200张图像以保证基本的分类效果。
模型推理篇
使用更大的预测尺度,比如说训练时使用的是224,那么预测时可以考虑使用288或者320,这会直接带来0.5%左右的精度提升; 使用测试时增广的策略(Test Time Augmentation, TTA),将测试集通过旋转、翻转、颜色变换等策略,创建多个副本,并分别预测,最后将所有的预测结果进行融合,这可以大大提升预测结果的精度和鲁棒性; 使用多模型融合的策略,将多个模型针对相同图片的预测结果进行融合。
