
spring-cloud gateway 网关调优
网关线程数的增加,对吞吐量有较大提升;
网关对CPU要求较高,建议提升CPU性能,但需要权衡单台高配和多台低配的整体性能对比;
网关对内存、硬盘要求较低;
在吞吐量追求和CPU负载升高之间,做权衡选择机器配置;
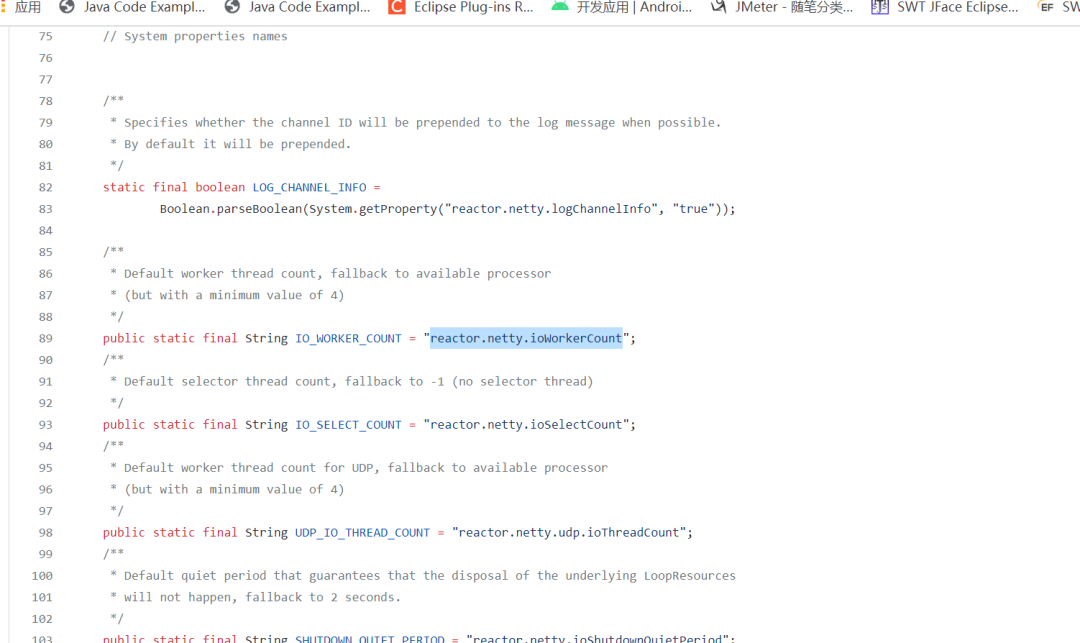
reactor.netty.ioWorkerCount参数调整netty工作线程数,在文件reactor.netty.ReactorNetty中
Spring Cloud Gateway 工作原理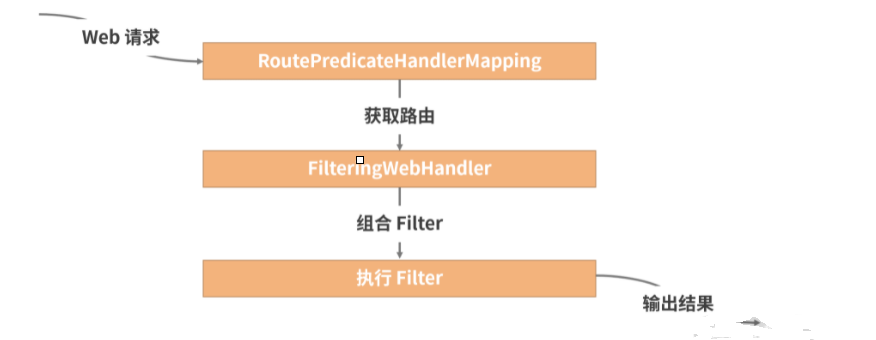
找到源码
org.springframework.cloud.gateway.handler.RoutePredicateHandlerMapping
再看RoutePredicateHandlerMapping#lookupRoute的实现
protected Mono lookupRoute(ServerWebExchange exchange) {
return this.routeLocator
.getRoutes()
//individually filter routes so that filterWhen error delaying is not a problem
.concatMap(route -> Mono
.just(route)
.filterWhen(r -> {
// add the current route we are testing
exchange.getAttributes().put(GATEWAY_PREDICATE_ROUTE_ATTR, r.getId());
return r.getPredicate().apply(exchange);
})
//instead of immediately stopping main flux due to error, log and swallow it
.doOnError(e -> logger.error("Error applying predicate for route: "+route.getId(), e))
.onErrorResume(e -> Mono.empty())
)
// .defaultIfEmpty() put a static Route not found
// or .switchIfEmpty()
// .switchIfEmpty(Mono.empty().log("noroute"))
.next()
//TODO: error handling
.map(route -> {
if (logger.isDebugEnabled()) {
logger.debug("Route matched: " + route.getId());
}
validateRoute(route, exchange);
return route;
});
/* TODO: trace logging
if (logger.isTraceEnabled()) {
logger.trace("RouteDefinition did not match: " + routeDefinition.getId());
}*/
}
遍历所有的路由规则直到找到一个符合的,路由过多是排序越往后自然越慢,但是也考虑到地方项目只有10个,但是我们还是试一试。
我们把这部分源码抽出来自己修改一下,先写死一个路由
protected Mono lookupRoute(ServerWebExchange exchange) {
if (this.routeLocator instanceof CachingRouteLocator) {
CachingRouteLocator cachingRouteLocator = (CachingRouteLocator) this.routeLocator;
// 这里的getRouteMap()也是新加的方法
return cachingRouteLocator.getRouteMap().next().map(map ->
map.get(“api-user”))
//这里写死一个路由id
.switchIfEmpty(matchRoute(exchange));
}
return matchRoute(exchange);
}
重新压测后速度提升了10倍,cpu也只有在请求进入时较高,但是仍然存在被拒绝的请求以及卡顿。
于是根据这个情况以及我们实际设定的路由规则,在请求进入时对重要参数以及path进行hash保存下次进入时不再走原来的判断逻辑。
protected Mono lookupRoute(ServerWebExchange exchange) {
//String md5Key = getMd5Key(exchange);
String appId = exchange.getRequest().getHeaders().getFirst("M-Sy-AppId");
String serviceId = exchange.getRequest().getHeaders().getFirst("M-Sy-Service");
String token = exchange.getRequest().getHeaders().getFirst("M-Sy-Token");
String path = exchange.getRequest().getURI().getRawPath();
StringBuilder value = new StringBuilder();
String md5Key = "";
if(StringUtils.isNotBlank(token)) {
try {
Map<String, Object> params = (Map<String, Object>) redisTemplate.opsForValue().get("token:" + token);
if(null !=params && !params.isEmpty()) {
JSONObject user = JSONObject.parseObject(params.get("user").toString());
appId = user.getString("appId");
serviceId = user.getString("serviceid");
}
}catch(Exception e) {
e.printStackTrace();
}
}
if(StringUtils.isBlank(appId) || StringUtils.isBlank(serviceId)) {
md5Key = DigestUtils.md5Hex(path);
}else {
value.append(appId);
value.append(serviceId);
value.append(path);
md5Key = DigestUtils.md5Hex(value.toString());
}
if (logger.isDebugEnabled()) {
logger.info("Route matched before: " + routes.containsKey(md5Key));
}
if ( routes.containsKey(md5Key)
&& this.routeLocator instanceof CachingRouteLocator) {
final String key = md5Key;
CachingRouteLocator cachingRouteLocator = (CachingRouteLocator) this.routeLocator;
// 注意,这里的getRouteMap()也是新加的方法
return cachingRouteLocator.getRouteMap().next().map(map ->
map.get(routes.get(key)))
// 这里保证如果适配不到,仍然走老的官方适配逻辑
.switchIfEmpty(matchRoute(exchange,md5Key));
}
return matchRoute(exchange,md5Key);
}
private Mono matchRoute(ServerWebExchange exchange,String md5Key) {
//String md5Key = getMd5Key(exchange);
return this.routeLocator
.getRoutes()
//individually filter routes so that filterWhen error delaying is not a problem
.concatMap(route -> Mono
.just(route)
.filterWhen(r -> {
// add the current route we are testing
exchange.getAttributes().put(GATEWAY_PREDICATE_ROUTE_ATTR, r.getId());
return r.getPredicate().apply(exchange);
})
//instead of immediately stopping main flux due to error, log and swallow it
.doOnError(e -> logger.error("Error applying predicate for route: "+route.getId(), e))
.onErrorResume(e -> Mono.empty())
)
// .defaultIfEmpty() put a static Route not found
// or .switchIfEmpty()
// .switchIfEmpty(Mono.empty().log("noroute"))
.next()
//TODO: error handling
.map(route -> {
if (logger.isDebugEnabled()) {
logger.debug("Route matched: " + route.getId());
logger.debug("缓存"+routes.get(md5Key));
}
// redisTemplate.opsForValue().set(ROUTE_KEY+md5Key, route.getId(), 5, TimeUnit.MINUTES);
routes.put(md5Key, route.getId());
validateRoute(route, exchange);
return route;
});
/* TODO: trace logging
if (logger.isTraceEnabled()) {
logger.trace("RouteDefinition did not match: " + routeDefinition.getId());
}*/
}
此次修改后路由有了一个较大的提升,开始继续分析拒绝请求以及卡顿问题。
考虑到是不是netty依据电脑的配置做了限制?在自己的笔记本上限制连接在200左右,在服务器上在2000左右
查了许多资料发现netty的对外配置并不是很多,不像tomcat、undertow等等
目前使用的scg版本较旧没有办法将netty修改为tomcat或者undertow,于是我在官网下载了最新的scg并将启动容器修改为tomcat和undertow依次进行了尝试,发现都没有200的限制。
然后开始查找netty方面的资料,发现了reactor.ipc.netty.workerCount
DEFAULT_IO_WORKER_COUNT:如果环境变量有设置reactor.ipc.netty.workerCount,则用该值;没有设置则取Math.max(Runtime.getRuntime().availableProcessors(), 4)))
JSONObject message = new JSONObject();
try {
Thread.sleep(30000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
ServerHttpResponse response = exchange.getResponse();
message.put("code", 4199);
message.put("msg", "模拟堵塞");
byte[] bits = message.toJSONString().getBytes(StandardCharsets.UTF_8);
DataBuffer buffer = response.bufferFactory().wrap(bits);
response.setStatusCode(HttpStatus.UNAUTHORIZED);
// 指定编码,否则在浏览器中会中文乱码
response.getHeaders().add("Content-Type", "application/json;charset=UTF-8");
return response.writeWith(Mono.just(buffer));
通过模拟堵塞测试,发现该参数用于控制接口的返回数量,这应该就是压测时接口卡顿返回的原因了,通过压测发现该参数在16核cpu的3倍时表现已经较好。16核cpu4倍时单机scg压测时没有卡顿,但是单机压15000时cpu大概在70-80。
通过找到该原因,怀疑人生的自己重拾信心通过百度reactor.ipc.netty.workerCount发现了另一个参数reactor.ipc.netty.selectCount
DEFAULT_IO_SELECT_COUNT:如果环境变量有设置reactor.ipc.netty.selectCount,则用该值;没有设置则取-1,表示没有selector thread
找到源码reactor.ipc.netty.resources.DefaultLoopResources
看到这段代码
if (selectCount == -1) {
this.selectCount = workerCount;
this.serverSelectLoops = this.serverLoops;
this.cacheNativeSelectLoops = this.cacheNativeServerLoops;
}else {
this.selectCount = selectCount;
this.serverSelectLoops =
new NioEventLoopGroup(selectCount, threadFactory(this, "select-nio"));
this.cacheNativeSelectLoops = new AtomicReference<>();
}
历经漫长的怀疑人生与越挫越勇(并没有),总共修改了2处,达成了一个10倍提升的小目标
总结
修改原生路由查找逻辑
设置系统变量reactor.ipc.netty.workerCount为cpu核数的3倍或4倍;设置reactor.ipc.netty.selectCount的值为1(只要不是-1即可)
另外,httpclient的配置情况可以参考org.springframework.cloud.gateway.config.GatewayAutoConfiguration.NettyConfiguration
source: www.icode9.com/content-4-1057716.html
喜欢,在看