
【深度学习】百度&中科院开源新的视觉Transformer:卷积与自注意力的完美结合 | CVPR 2022 Oral
以下文章来源于极市平台 ,作者CV开发者都爱看的
论文地址:https://arxiv.org/abs/2204.02557
写在前面的话

问题引出
如何解决
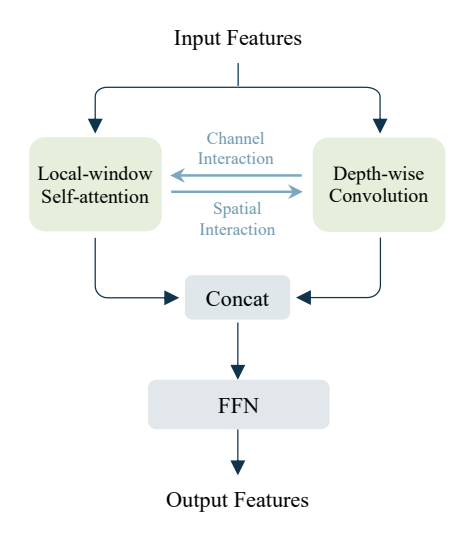

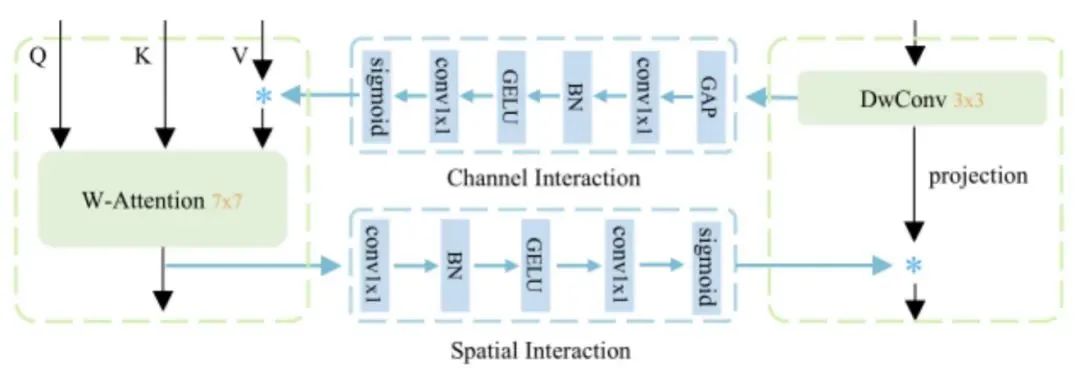
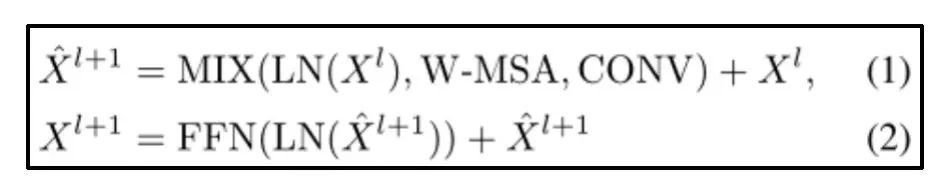
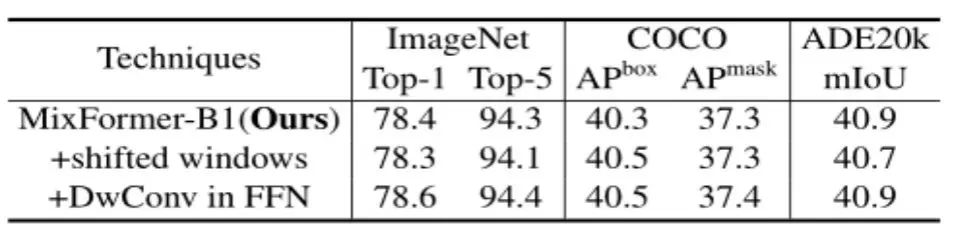

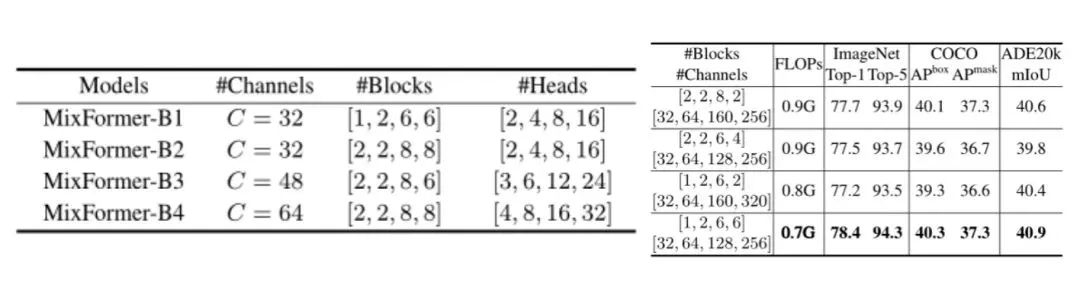
思考
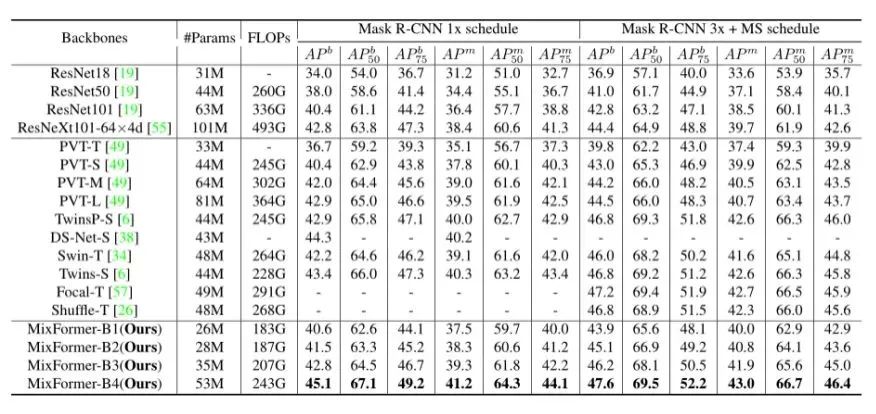
END
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码:
评论