
SRCNN:基于深度学习的超分辨率开山之作回顾

来源:DeepHub IMBA 本文约1800字,建议阅读5分钟
本文将介绍CNN 如何用于单图像超分辨率(SISR)。
本文提供了与SRCNN论文的总结和回顾,如果你对于图像的超分辨率感兴趣,一定要先阅读这篇论文,他可以说是所有基于深度学习的超分辨率模型的鼻祖。
卷积神经网络通常用于分类,目标检测,图像分割等与某些与图像有关的问题中。
在本文中,将介绍CNN 如何用于单图像超分辨率(SISR)。这有助于解决与计算机视觉相关的各种其他问题。在CNN出现之前,传统的方法是使用最近邻插值、双线性或双三次插值等上采样方法,也可以取得不错的效果。
Nearest Neighbors Interpolation — 最近邻插值是一种简单明了的方法。它为每个插值点选择最近像素的值,而不考虑任何其他像素的值。
Bilinear Interpolation (BLI) — 双线性插值 这是一种在图像的一个轴上进行线性插值,然后再移动到另一个轴的技术。因为它产生了一个接受域大小为 2x2 的二次插值,所以它在保持合理速度的同时优于最近邻插值。
Bicubic Interpolation(BCI) — 双三次插值与双线性插值一样,双三次插值 (BCI) 在两个轴上进行。与 BLI 相比,BCI 考虑 4x4 像素,从而产生更平滑的输出,具有更少的伪影,但速度要慢得多。

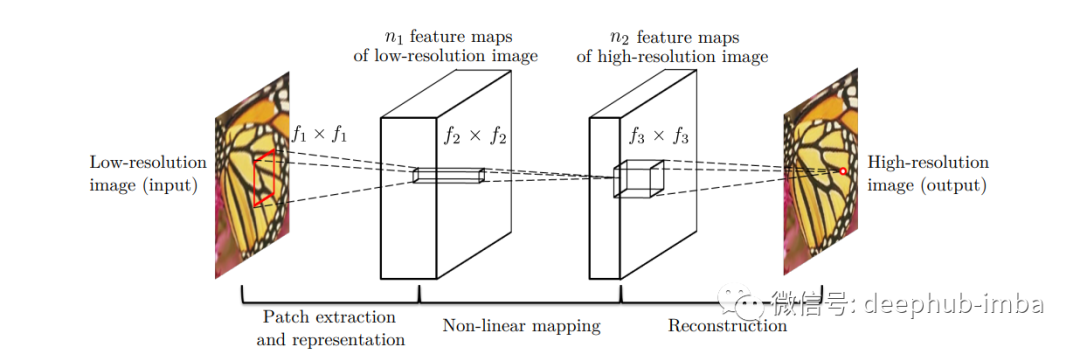
本文介绍的SRCNN 模型基本由三个使用步骤组成:
区块补丁提取和表示
非线性映射
重建
相关工作
一般情况下 SISR (Single Image Super Resolution,)可以总结为以下4种方法——预测模型、基于边缘的方法、图像统计方法和基于补丁(或基于样本)的方法。SRCNN 使用基于补丁的方法。利用输入图像内部样本的自相似性属性来生成补丁。SRCNN 使用稀疏编码公式来映射低分辨率和高分辨率的补丁,并且图像考虑了 YCbCr 颜色通道。
用于图像恢复的深度学习
大多数图像恢复深度学习方法都是去噪驱动的。虽然自编码器不能提供从低分辨率到高分辨率图像的端到端映射,但是在去噪图像领域表现得非常好,而SRCNN 专注于解决这个问题。
CNN 超分辨率
对于一个单一的低分辨率图像:首先使用双三次插值将其放大到适当的大小,这是唯一要做的预处理。使用术语“Y”来描述我们正在谈论的内容。Y 是插值图像。我们的目标是让图像 F(Y) 回到与高分辨率真实图像 (X) 尽可能接近的 Y 上。我们仍然将 Y 称为“低分辨率”,因为它易于呈现,尽管它与 (X) 大小相同。而模型的目的是学习 F(Y) 映射,它由三部分操作组成:
1. 补丁提取和表示:该操作从低分辨率图像 Y 中提取(重叠)补丁,然后将每个补丁表示为一个高维向量。这些向量由一组特征图组成,其数量等于向量的维度。
2. 非线性映射:每个高维向量在这个过程中非线性映射到另一个高维向量上。高分辨率补丁在概念上由每个映射向量表示。另一个特征图集合由这些向量组成。
3. 重建:这个过程结合了前面提到的高分辨率补丁表示来产生最终的高分辨率图像。此图像应类似于 X 真实图像。
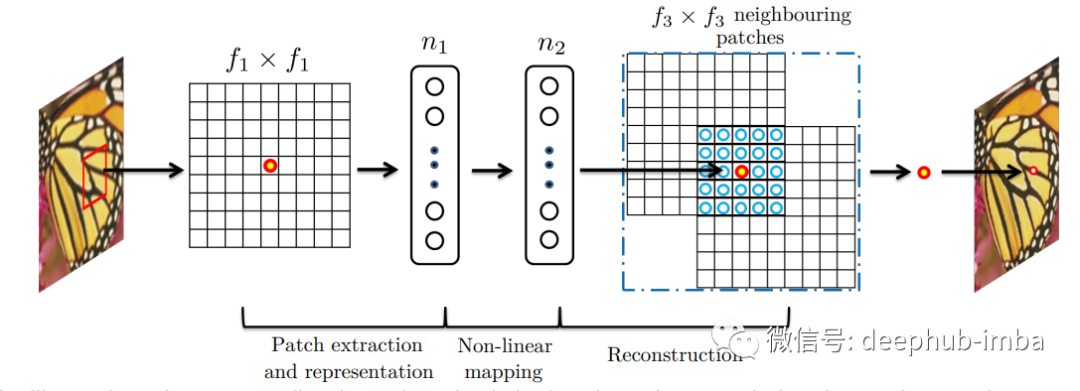
补丁提取和表示
采用提取小块的方法,通过一组预训练的基础(例如 PCA、DCT离散余弦变换等)来表示它,这种技术非常的常见。这与通过一系列卷积核(过滤器)的运行图像相同。操作表示为:这里 W1,B1 是过滤器和偏差,* 表示执行卷积。W1 是支持 c x f1 x f1 的 n1 个过滤器,其中 c 代表通道,f1 是过滤器的大小。B1 的大小为 n1。
非线性映射
执行非线性映射以减少维度,并尝试保持数据点之间的距离。
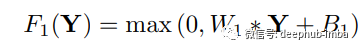
这里 W2 是 n1 x f2 x f2 x n2 并且 f2 = 1 ,n1>n2。
重建
最后,卷积层再次用于生成最终的高分辨率图像。
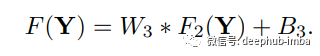
W3 的大小为 n2 x f3 x f3,B3 是 c 维向量。
与基于稀疏编码的方法的关系
在稀疏编码(Sparse Coding / SC)的情况下,输入图片通过 f1 进行卷积并投影到 n1 维字典上。在大多数情况下 n1=n2 。然后,在没有减少维度的情况下,n1 到 n2 被映射为相同的维度。它类似于将低分辨率矢量映射到高分辨率矢量。之后f3 重建每个补丁并卷积对重叠的补丁进行平均,而不是将它们与不同的权重放在一起。
训练过程
训练图像时的损失函数是 MSE 均方误差。
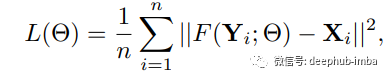
模型使用 T91和 ImageNet 进行训练。为了评估 SRCNN,考虑了图像恢复中流行的评估指标 PSNR(峰值信噪比)。T91个图像数据集的 SRCNN 为 31.42,ImageNet 数据集为 35.2 dB(分贝),与之前的超分辨率技术相比,两者的性能都非常出色。
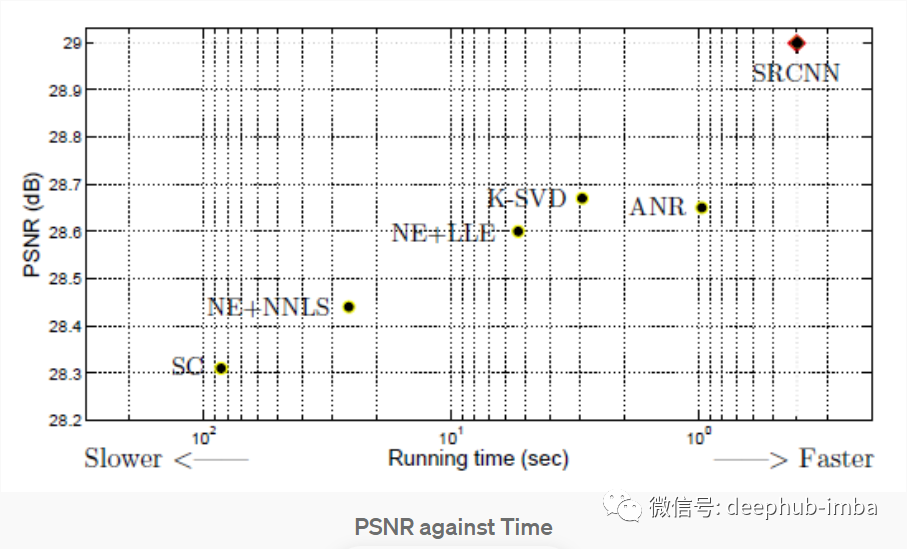
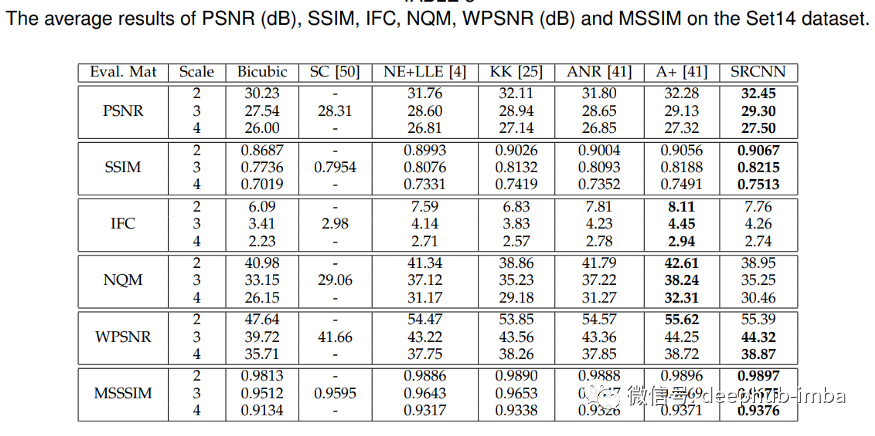
上图中可以看到 SRCNN 表现更好,在图像超分辨率 SRCNN 的其他评估指标中也表现良好。Set14 数据集是来自 T91 图像数据集的子图像,其中 24.800 个子图像使用步幅 14 和高斯模糊。
总结
经过这么多年的发展,相比于SRGAN 等图像超分辨率的最先进模型,SRCNN肯定已经被超越了。但是SRCNN 是一个简单模型,使用仅仅3层就解决了解决图像恢复问题并且产生了非常好的效果,目前超分方向的论文基本上都是以他的研究为基础的,所以如果你对图像超分感兴趣,或者想深入学习的话,这篇论文一定要看。
论文地址:
Image Super-Resolution Using Deep Convolutional Networks https://arxiv.org/abs/1501.00092
最后这里有个完整代码,可以直接线上运行:
https://colab.research.google.com/drive/1qGit7oTmIBPcFdu9CR5jH7sMe0X_4Qeg?usp=sharing
作者:Jitesh Rawat
编辑:黄继彦